Document AI adds one-click model training with ML Workbench
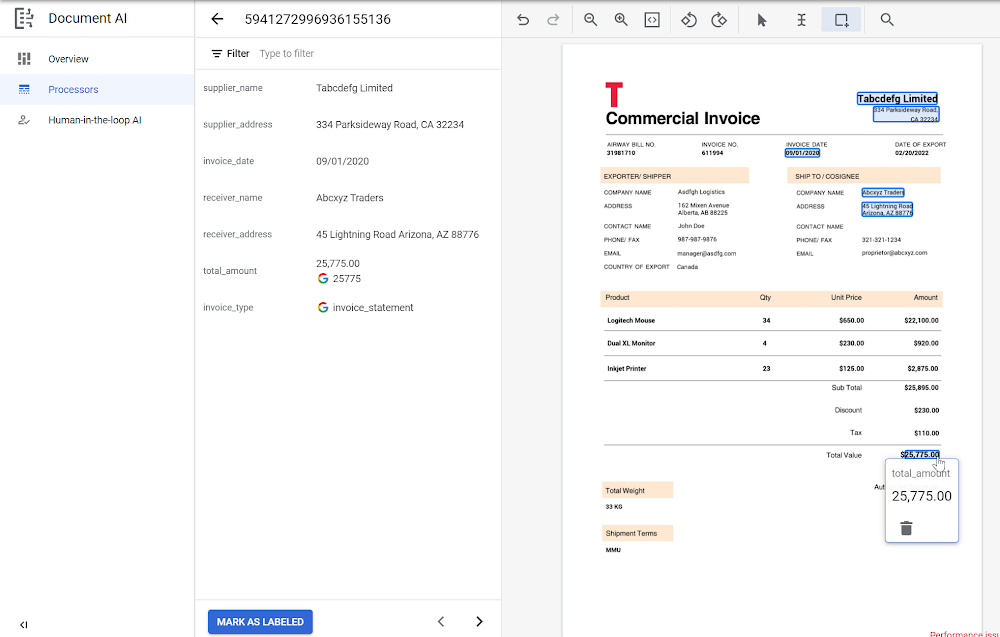
Each day, countless documents are created, revised, and shared across organizations. The result is a treasure trove of information, but because the data is primarily unstructured — without rows, columns or some other predefined organizational schema — it is difficult to interpret, analyze or use for business processes. That’s why we introducedDocument AI: so users can extract structured data from documents through machine learning (ML) models to automate business processes and improve decision-making. Over the last two years, our customers have used Document AI toaccelerate and enhance document-based workflows in area like procurement, lending, identity, and contracts—and at Google Cloud Next ’22, we expanded these capabilities in a big way with the release of Document AI Workbench, a new feature that makes it fast and easy to apply ML to virtually any document-based workflow. Document AI Workbench lets analysts, developers, and even business users ingest their own data to train models with the click of a button, then extract fields from documents needed for the business. Relative to traditional development approaches, Document AI Workbench lets organizations build models faster and with less data—thus accelerating time-to-value for processing and analysis of unstructured data in documents.This [Document AI Workbench] is poised to be a game changer, because we can now uptrain various text documents and forms utilizing powerful Google machine learning models to get the desired accuracy creating greater time and resource efficiencies for our clients Daan De Groodt Managing Director, Deloitte Consulting LLPIn this blog post, we’ll explore Document AI Workbench’s capabilities, as well as ways customers are already putting this new feature to work. Benefits of custom modeling with Document AI Workbench Our customers use Document AI Workbench to ultimately save time and money. “Document AI Workbench is helping us expand document automation more quickly and effectively. By using Document AI Workbench, we have been able to train our own document parser models in a fraction of the time and with less resources. We feel this will help us realize important operational improvements for our business and help us serve our customers much better,” said Daniel Ordaz Palacios, Global Head Business Process & Operations, at financial services company BBVA. Let’s break down some of the ways the feature delivers these benefits. Democratized MLData scientists’ time is scarce. With Document AI Workbench, developers, analysts, and others with limited ML experience can create ML models by labeling data with a simple interface, then initiating training with the click of a button. By leveraging training data to create a model behind the scenes, Document AI Workbench expands the range of users who can contribute to ML models while preserving data scientists’ efforts for the most sophisticated projects.Many document typesWith Document AI Workbench, organizations can bring their own data to create ML models for many document types and attributes, including printed or handwritten text, tables and other nested entities, checkboxes, and more. Customers can process document images whether they were professionally scanned or captured in a quick photo, and they can import data in multiple formats, such as PDFs, common image formats, and JSON document.proto.Time-to-marketDocument AI Workbench significantly reduces customers’ time to market, compared to building custom ML models, because users simply provide training data, with Document AI handling the rest. Our users don’t have to worry about model weights, parameters, anchors, etc.Less training dataDocument AI Workbench helps customers build ML models that achieve accurate results with less training data. This is especially true when “uptraining,” in which Document AI Workbench transfers learnings from pre-trained models to produce more accurate results. We support uptraining for Invoice, Purchase Order, Contracts, W2, 1099-R, and paystub documents.We plan to support more document types in the future, and to make ML model training even easier by continuing to reduce the amount of training data required for accurate output. As an example, Google’s DeepMind team recently developed a new method that allows the creation of document parsing ML models for utility bills and purchase orders with 50%-70% less training data than what was previously needed for Document AI. We’re working on integrating this method into Document AI Workbench in the coming months.1No-cost trainingInstead of having to pay to spin up servers and wait while models are trained, Document AI Workbench lets users create and evaluate ML models for free. Customers simply pay as they go once models are deployed.With Document AI Workbench, organizations can enjoy all these features and more. And organizations own the data used to train models.Thanks to these benefits, many customers are already seeing impressive results. Muthukumaraswamy B, VP of Data Science at technology firm Searce said, “We estimate that our time-to-market will reduce by up to ~80% with Document AI Workbench vs. building custom models.”Similarly, software company Libeo “uptrained an invoice processor with 1,600 documents and increased testing accuracy from 75.6% (with pretrained models) to 83.9% with uptraining on Document AI Workbench,” said CPO & CTO Pierre-Antoine Glandier. “Thanks to uptraining, Document AI results beat the results of a competitor and will help Libeo save ~20% on the overall cost over the long run.”Technology firm Zencore is making strides as well. “Document AI Workbench allows us to develop highly accurate document parsing models in a matter of days. Our customers have completely automated tasks that formerly required significant human labor,” said Sean Earley, VP of Delivery Service.How to use Document AI WorkbenchUsers can leverage a simple interface in the Google Cloud Consoleto prepare training data, create and evaluate models, and deploy a model into production, at which point it can be called to extract data from documents. Import and prepare training dataTo get started, users import and label documents to train an ML model. If documents are labeled using other tools, users can simply import labels with JSON in the doc.proto format. If documents need to be labeled, they can create their document schema and use our simple interface to label documents. Optical character recognition (OCR) will automatically detect the content and prepare training data.Train a modelWith one click, users can train a model. If they are working with a document type similar in layout and schema to an existing document model, they can uptrain the relevant model to get accurate results faster. If there is no relevant, uptrainable model available for the document, they can create a model with Document AI Workbench’s Customer Document Extractor.Evaluate a model and iterateOnce a model is trained, it’s time to evaluate it by looking at the performance metrics–F1 score, precision, recall, etc. Users can dive into specific instances where the model predicted an error and provide additional training data to improve future performance.Going into productionOnce a model meets accuracy targets, it’s time to deploy into production, after which the model endpoint can be called to extract structured data from documents. Finally, users can configure human-in-the-loop review workflows to correct predictions whose confidence levels are below the required threshold. With human review, organizations can correct or confirm output before they use it in production and leverage the corrected data to train the model and improve the accuracy of future predictions.“Google’s Document AI Workbench offers a flexible, easy-to-use interface with the end-to-end functionality our clients demand. Custom document extractors and classifiers not only reduce our prototyping from months to weeks, but also offer clients added cost reductions compared to their current technologies,” said Erik Willsey, CTO at data and analytics modernization firm Pandera. Getting started with Document AI WorkbenchWe’re thrilled to see so many customers and partners already driving value with Document AI Workbench. To learn more, check out the Document AI Workbench landing page, watch this Next’22 session on Document AI or peruse our key partners who are ready to help you get started.1. Deepmind used thousands of Google’s internal documents, such as utility bills and purchase orders from a variety of vendors to develop and evaluate this method. The performance will vary and depend on the evaluation dataset.
Quelle: Google Cloud Platform