AI-powered coding assistants are becoming a core part of modern development workflows. At the same time, many teams are increasingly concerned about where their code goes, how it’s processed, and who has access to it.
By combining OpenCode with Docker Model Runner, you can build a powerful AI-assisted coding experience while keeping full control over your data, infrastructure and spend.
This post walks through how to configure OpenCode to use Docker Model Runner and explains why this setup enables a privacy-first and cost-aware approach to AI-assisted development.
What Are OpenCode and Docker Model Runner?
OpenCode is an open-source coding assistant designed to integrate directly into developer workflows. It supports multiple model providers and exposes a flexible configuration system that makes it easy to switch between them.
Docker Model Runner (DMR) allows you to run and manage large language models easily. It exposes an OpenAI-compatible API, making it straightforward to integrate with existing tools that already support OpenAI-style endpoints.
Together, they provide a familiar developer experience backed by models running entirely within infrastructure you control.
Modifying the OpenCode Configuration
OpenCode can be customized using a configuration file that controls how providers and models are defined.
You can define this configuration in one of two places:
Global configuration: ~/.config/opencode/opencode.json
Project-specific configuration: opencode.json in the root of your project
When a project-level configuration is present, it takes precedence over the global one.
Using OpenCode with Docker Model Runner
Docker Model Runner (DMR) exposes an OpenAI-compatible API, which makes integrating it with OpenCode straightforward. To enable this integration, you simply need to update your opencode.json file to point to the DMR server and declare the locally available models.
Assuming Docker Model Runner is running at: http://localhost:12434/v1
your opencode.json configuration could look like this:
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"dmr": {
"npm": "@ai-sdk/openai-compatible",
"name": "Docker Model Runner",
"options": {
"baseURL": "http://localhost:12434/v1",
},
"models": {
"qwen-coder3": {
"name": "qwen-coder3"
},
"devstral-small-2": {
"name": "devstral-small-2"
}
}
}
}
}
This configuration allows OpenCode to utilize locally hosted models through DMR, providing a powerful and private coding assistant.Note for Docker Desktop users:
If you are running Docker Model Runner via Docker Desktop, make sure TCP access is enabled. OpenCode connects to Docker Model Runner over HTTP, which requires the TCP port to be exposed:
docker desktop enable model-runner –tcp
Once enabled, Docker Model Runner will be accessible at http://localhost:12434/v1.
Figure 1: Enabling OpenCode to utilize locally hosted models through Docker Model Runner
Figure 2: Models like qwen3-coder, devstral-small-2, gpt-oss are good for coding use cases.
Benefits of using OpenCode with Model Runner
Privacy by Design
Using OpenCode with Docker Model Runner enables a privacy-first approach to AI-assisted development by keeping all model inference within the infrastructure you control.
Docker Model Runner runs models behind an OpenAI-compatible API endpoint. OpenCode sends prompts, source code, and context only to that endpoint, and nowhere else.
This means:
No third-party AI providers are involved
No external data sharing or vendor-side retention
No training on your code by external services
From OpenCode’s perspective, the provider is simply an API endpoint. Where that endpoint runs, on a developer machine, an internal server, or a private cloud, is entirely up to you.
Cost Control
Beyond privacy, running models with Docker Model Runner provides a significant cost advantage over hosted AI APIs.
Cloud-hosted coding assistants, can become expensive very quickly, especially when:
Working with large repositories
Passing long conversational or code context
Running frequent iterative prompts during development
With Docker Model Runner, inference runs on your own hardware. Once the model is pulled, there are no per-token fees, no request-based pricing, and no surprise bills. Teams can scale usage freely without worrying about escalating API costs.
Recommended Models for Coding
When using OpenCode with Docker Model Runner, model choice has a direct impact on both quality and developer experience. While many general-purpose might models work reasonably well, coding-focused models are optimized for long context windows and code-aware reasoning, which is especially important for real-world repositories.
The following models are well suited for use with OpenCode and Docker Model Runner:
qwen3-coder
devstral-small-2
gpt-oss
Each of these models can be served through Docker Model Runner and exposed via its OpenAI-compatible API.
You can pull these models by simply running:
docker model pull qwen3-coder
Pulling Models from Docker Hub and Hugging Face
Docker Model Runner can pull models not only from Docker Hub, but also directly from Hugging Face and automatically convert them into OCI artifacts that can be run and shared like any other Docker model.
For example, you can pull a model directly from Hugging Face with:
docker model pull huggingface.co/unsloth/Ministral-3-14B-Instruct-2512-GGUF
This gives teams access to the broader open model ecosystem without sacrificing consistency or operability.
Context Length Matters
For coding tasks, context length is often more important than raw parameter count. Large repositories, multi-file refactors, and long conversational histories all benefit from being able to pass more context to the model.
By default:
qwen3-coder → 128K context
devstral-small-2 → 128K context
gpt-oss → 4,096 tokens
The difference comes down to model intent.
qwen3-coder and devstral-small-2 are coding-focused models, designed to ingest large amounts of source code, project structure, and related context in a single request. A large default context window is critical for these use cases.
gpt-oss, on the other hand, is a general-purpose model. Its default context size reflects a broader optimization target, where extremely long inputs are less critical than they are for code-centric workflows.
Increasing Context Size for GPT-OSS
If you want to use gpt-oss for coding tasks that benefit from a larger context window, Docker Model Runner makes it easy to repackage the model with an increased context size.
For example, to create a version of gpt-oss with a 128K context window, you can run:
docker model pull gpt-oss # In case it's not pulled
docker model package –from gpt-oss –context-size 128000 gpt-oss:128K
This creates a new model artifact with an expanded context length that can be served by Docker Model Runner like any other model.Once packaged, you can reference this model in your opencode.json configuration:
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"dmr": {
"npm": "@ai-sdk/openai-compatible",
"name": "Docker Model Runner",
"options": {
"baseURL": "http://localhost:12434/v1"
},
"models": {
"gpt-oss:128K": {
"name": "gpt-oss (128K)"
}
}
}
}
}
Sharing Models Across Your Team
Packaging models as OCI Artifacts has an additional benefit: the resulting model can be pushed to Docker Hub or a private registry.
This allows teams to:
Standardize on specific model variants (including context size)
Share models across developers without local reconfiguration
Ensure consistent behavior across environments
Version and roll back model changes explicitly
Instead of each developer tuning models independently, teams can treat models as first-class artifacts, built once and reused everywhere.
Putting It All Together: Using the Model from the CLI
With Docker Model Runner configured and the gpt-oss:128K model packaged, you can start using it immediately from OpenCode.
This section walks through selecting the model and using it to generate an agents.md file directly inside the Docker Model project.
Step 1: Verify the Model Is Available
First, confirm that the packaged model is available locally:
docker model ls
You should see gpt-oss:128K listed among the available models. If not, make sure the packaging step is completed successfully.
Step 2: Configure OpenCode to Use the Model
Ensure your project’s opencode.json includes the packaged model:
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"dmr": {
"npm": "@ai-sdk/openai-compatible",
"name": "Docker Model Runner",
"options": {
"baseURL": "http://localhost:12434/v1"
},
"models": {
"gpt-oss": {
"name": "gpt-oss:128K"
}
}
}
}
}
This makes the model available to OpenCode under the dmr provider.
Step 3: Start OpenCode in the Project
From the root of the Docker Model project, start OpenCode:
opencode
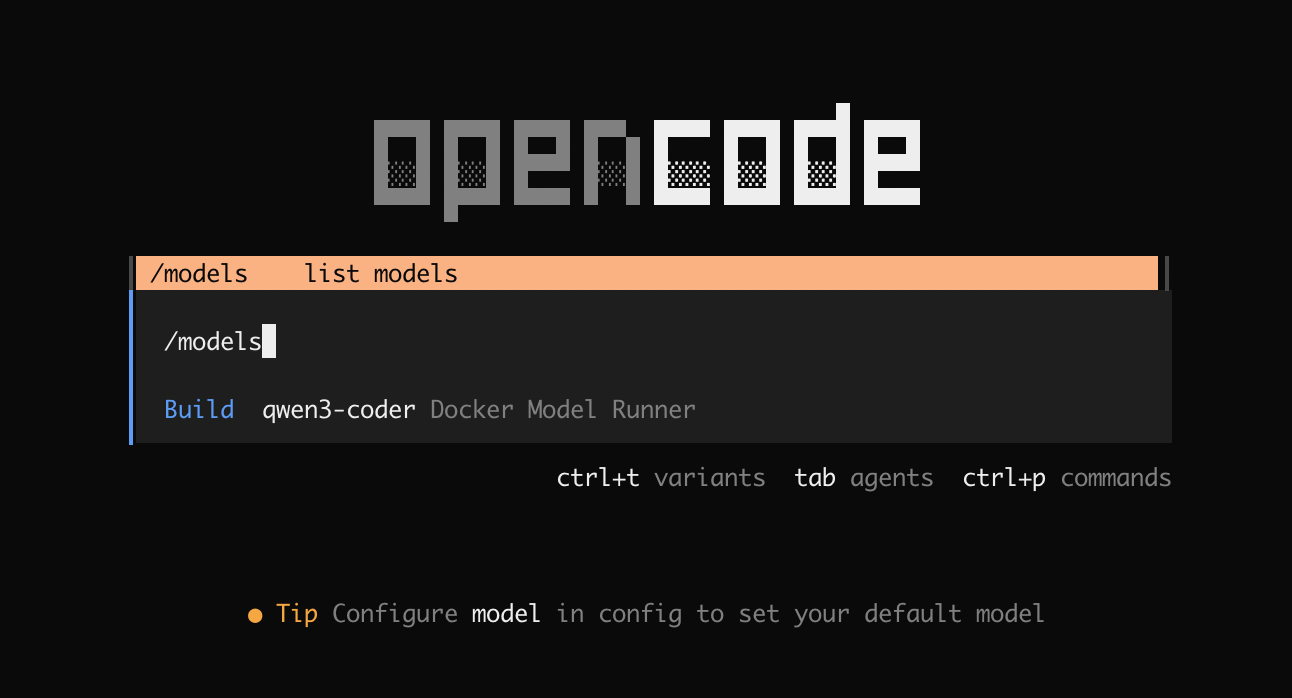
Select the model from the list by running:
/models
Figure 3: Selecting gpt-oss model powered by Docker Model Runner in OpenCode
Step 4: Ask OpenCode to Generate agents.md
Once OpenCode is running, prompt the model to generate an agents.md file using the repository as context:
Generate an agents.md file in the project root following the agents.md specification and examples.
Use this repository as context and include sections that help an AI agent work effectively with this project, including:
– Project overview
– Build and test commands
– Code style guidelines
– Testing instructions
– Security considerations
Base the content on the actual structure, tooling, and conventions used in this repository.
Keep the file concise, practical, and actionable for an AI agent contributing to the project.
Because OpenCode is connected to Docker Model Runner, it can safely pass repository structure and relevant files to the model without sending any data outside your infrastructure.
The expanded 128K context window allows the model to reason over a larger portion of the project, resulting in a more accurate and useful agents.md.
Figure 4: The resulting agents.md file
Step 5: Review and Contribute to Docker Model Runner
Once the file is generated:
cat agents.md
Make any necessary adjustments so it accurately reflects the project, then commit it like any other project artifact:
git add agents.md
git commit -m "Add agents documentation"
At this point, you’re ready to open your first Docker Model Runner pull request.
Using OpenCode with Docker Model Runner makes it easy to contribute high-quality documentation and project artifacts, while keeping all model inference and repository context within the infrastructure you control.
How You Can Get Involved
The strength of Docker Model Runner lies in its community and there’s always room to grow. We need your help to make this project the best it can be. To get involved, you can:
Star the repository: Show your support and help us gain visibility by starring the Docker Model Runner repo.
Contribute your ideas: Have an idea for a new feature or a bug fix? Create an issue to discuss it. Or fork the repository, make your changes, and submit a pull request. We’re excited to see what ideas you have!
Spread the word: Tell your friends, colleagues, and anyone else who might be interested in running AI models with Docker.
We’re incredibly excited about this new chapter for Docker Model Runner, and we can’t wait to see what we can build together. Let’s get to work!
Learn more
Check out the Docker Model Runner General Availability announcement
Visit our Model Runner GitHub repo! Docker Model Runner is open-source, and we welcome collaboration and contributions from the community!
Get started with Docker Model Runner with a simple hello GenAI application
Quelle: https://blog.docker.com/feed/