Elektroauto: Tesla erhöht Reichweite von Model 3 und Model Y
Das Tesla Model 3 und Model Y fahren jetzt weiter und haben auch noch andere technische Verbesserungen erhalten. Das Model 3 bekommt bessere Blinker. (Tesla, Elektroauto)
Quelle: Golem

Das Tesla Model 3 und Model Y fahren jetzt weiter und haben auch noch andere technische Verbesserungen erhalten. Das Model 3 bekommt bessere Blinker. (Tesla, Elektroauto)
Quelle: Golem

Bayern steht im Verdacht, lieber sein eigenes Ding zu machen, als mit nördlichen Bundesländern zu kooperieren. Drei Beispiele zeigen, wie es auch anders gehen kann. Von Markus Feilner (Open Source, Linux)
Quelle: Golem
AWS Directory Service now enables customers to upgrade Managed Microsoft AD from Standard to Enterprise Edition programmatically through the UpdateDirectorySetup API. The self-service edition upgrade eliminates the need for support tickets when scaling Managed Microsoft AD directories. The API-driven Standard to Enterprise Edition upgrade removes operational barriers that previously required coordinating maintenance windows with AWS support, enabling on-demand directory scaling with automated pre-upgrade snapshots and sequential domain controller upgrades. This streamlined process ensures data protection through automatic backup creation before upgrades begin, while the sequential upgrade approach maintains directory availability throughout the process. Organizations can now scale their directory infrastructure in response to growing user bases or expanding application requirements without the delays associated with traditional support-driven upgrade processes. The programmatic approach enables integration with existing automation frameworks and infrastructure-as-code deployments. Directory size upgrades are available in all AWS Directory Service regions through the AWS SDK, providing consistent upgrade capabilities across global deployments. To learn more, see the AWS Directory Service documentation and UpdateDirectorySetup API reference.
Quelle: aws.amazon.com

Die SPD warnt vor dem Aus für das Verbrennerverbot. Das sei nicht nur schlecht für Planungssicherheit und Klimaschutz, sondern auch für die Autoindustrie. Ein Interview von Friedhelm Greis (Elektroauto, Auto)
Quelle: Golem

Wegen verdächtiger Drohnen sind die Start- und Landebahnen am Donnerstagabend stundenlang gesperrt gewesen. 3.000 Passagiere sind festgesessen. (Drohne, Politik)
Quelle: Golem

Bei einem von tausenden Zahnarztpraxen eingesetzten Praxisverwaltungssystem hätten durch eine Schwachstelle Patientendaten gelesen und verändert werden können. Ein Bericht von Günter Born (Sicherheitslücke, SQL)
Quelle: Golem

Der Tech-Sektor im Land sucht händeringend nach Fachkräften – mit flachen Hierarchien und zum Teil verlockenden Gehältern. Was Interessenten wissen müssen. Ein Ratgebertext von Peter Ilg (Arbeit, Wirtschaft)
Quelle: Golem

Das Projekt soll die Stromerzeugung eines Offshore-Windparks ergänzen. Noch sind Fragen offen, wie das Meer auf die Solarzellen reagiert. (Solarenergie, Energiewende)
Quelle: Golem
Today we’re announcing new capabilities in Azure AI Foundry that make it easier for developers to build, observe, and govern multi-agent systems, while helping organizations close the trust gap in AI.
As agentic AI adoption accelerates—eight in ten enterprises now use some form of agent-based AI, according to PwC1—the complexity of managing these systems is increasing. Developers face fragmented tooling, and organizations struggle to ensure agents behave responsibly. Our latest updates to Azure AI Foundry address these challenges head-on.
Introducing Microsoft Agent Framework (public preview)
The Microsoft Agent Framework, now in public preview, is the open-source SDK and runtime that simplifies the orchestration of multi-agent systems. It converges AutoGen, a former Microsoft Research project, and the enterprise-ready foundations of Semantic Kernel into a unified, commercial-grade framework—bringing cutting-edge research to developers.
Get started with the Microsoft Agent Framework
With Microsoft Agent Framework, developers can:
Experiment locally and then deploy to Azure AI Foundry with observability, durability, and compliance built in.
Integrate any API via OpenAPI, collaborate across runtimes with Agent2Agent (A2A), and connect to tools dynamically using Model Context Protocol (MCP).
Use the latest multi-agent patterns like Magentic One and orchestrate agents into Workflows.
Reduce context-switching across tools and platforms.
Build multi-agent systems connecting Azure AI Foundry, Microsoft 365 Copilot, and other agent platforms.
This framework is designed to help developers stay in flow. According to an industry study2, 50% of developers lose more than 10 hours per week due to inefficiencies like fragmented tools, highlighting the need for solutions that reduce complexity and improve the developer experience.
One organization using Microsoft Agent Framework to reduce friction is KPMG. KPMG’s transformation began with KPMG Clara, its cloud-based smart audit platform used on every KPMG audit worldwide.
KPMG Clara AI is tightly aligned with the next-generation, open-source Microsoft Agent Framework, built on the convergence of Semantic Kernel and AutoGen.
This means KPMG Clara AI can connect specialized agents to enterprise data and tools, while benefiting from built-in safeguards and an open, extensible developer ecosystem. The framework’s open-source connectors allow agents in KPMG Clara AI to interoperate not only with Azure AI Foundry, but also with external systems and language models, making it possible to scale multi-agent collaboration across a global, regulated enterprise.
Foundry Agent Service and Microsoft Agent Framework connect our agents to data and each other, and the governance and observability in Azure AI Foundry provide what KPMG firms need to be successful in a regulated industry.
— Sebastian Stöckle, Global Head of Audit Innovation and AI at KPMG International
We invite developers to join us in shaping the future of agentic AI by contributing code and feedback to Microsoft Agent Framework.
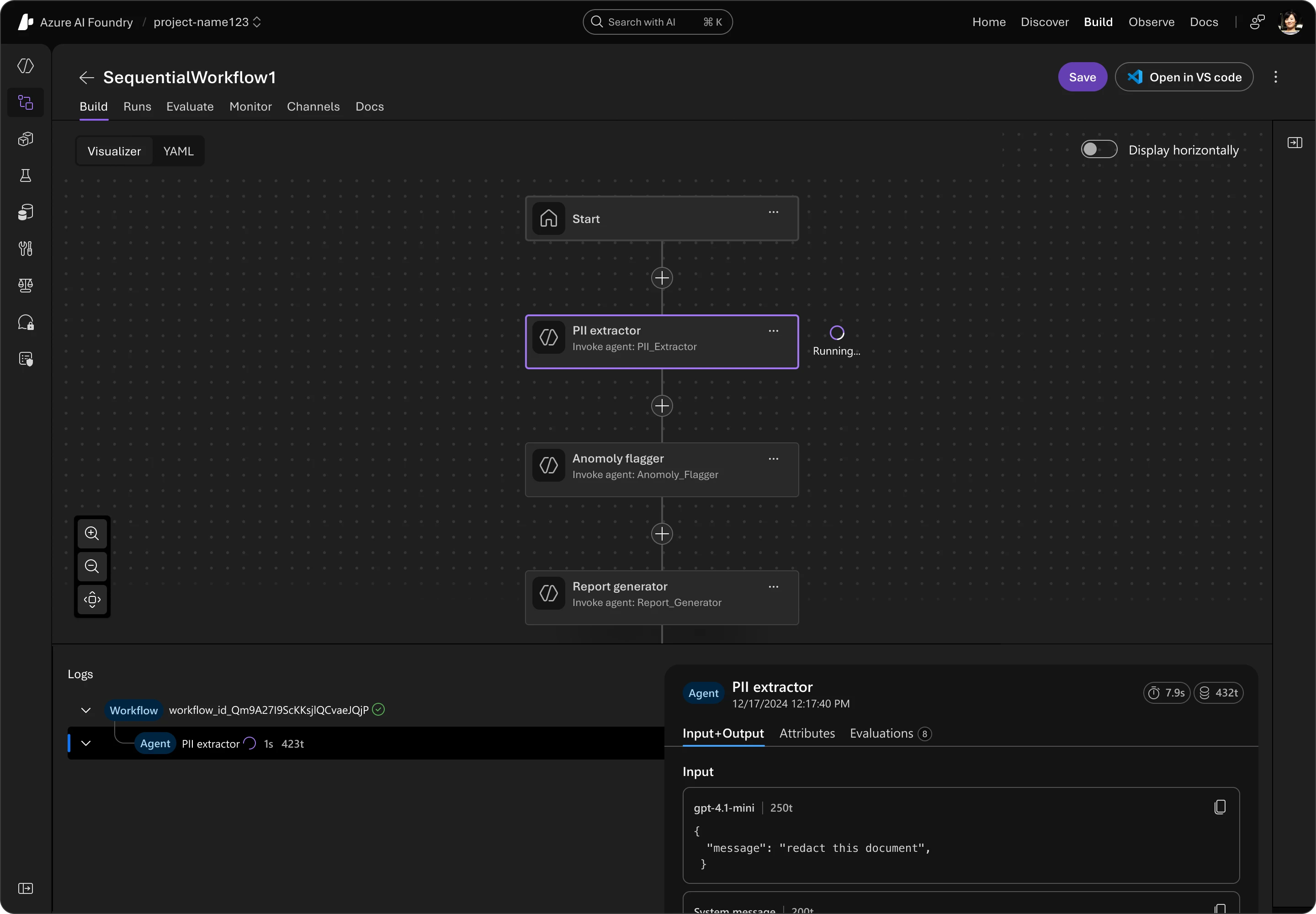
Multi-agent workflows (private preview)
Building on Microsoft Agent Framework, we’re extending these capabilities directly into the cloud with multi-agent workflows in Foundry Agent Service. This new feature enables developers to orchestrate sophisticated, multi-step business processes using a structured, stateful workflow layer.
With multi-agent workflows, teams can:
Coordinate multiple agents across long-running tasks with persistent state and context sharing.
Automate complex enterprise scenarios such as customer onboarding, financial transaction processing, and supply chain automation.
Leverage built-in error handling, retries, and recovery to improve reliability at scale.
Workflows can be authored and debugged visually through the VS Code Extension or Azure AI Foundry, then deployed, tested, and managed in Foundry alongside existing solutions.
Several customers are currently experimenting with this capability, and we look forward to expanding to more customers in the coming weeks.
Multi-agent observability across popular frameworks with OpenTelemetry contributions
We’re also announcing enhancements to multi-agent observability, with contributions to OpenTelemetry that help standardize tracing and telemetry for agentic systems.
This gives teams deeper visibility into agent workflows, tool call invocations, and collaboration—critical for debugging, optimization, and compliance. We made the above enhancements to OpenTelemetry in collaboration with Outshift, Cisco’s incubation engine.
With the above enhancements, Azure AI Foundry now provides unified observability for agents built with multiple frameworks, including Microsoft Agent Framework and others like LangChain, LangGraph, and OpenAI Agents SDK.
Voice Live API in Azure AI Foundry now generally available
Mutli-agent workflows are increasingly initiated through voice inputs and culminate in voice outputs. We’re excited to announce the general availability of Voice Live API, which empowers developers and enterprises to build scalable, production-ready voice AI agents. Voice Live API is a unified, real-time speech-to-speech interface that integrates speech-to-text (STT), generative AI models, text-to-speech (TTS), avatar, and conversational enhancement features into a single, low-latency pipeline.
Organizations such as Capgemini, healow, Astra Tech, and Agora are leveraging Voice Live API to build customer service agents, educational tutors, HR assistants, and multilingual agents. Voice Live API is transforming how developers build voice AI agents by providing an integrated, scalable, and efficient solution.
Responsible AI capabilities public preview
Building on advancements in agent observability and framework integration, it’s equally important to ensure that AI systems operate responsibly and securely—especially as they become more deeply embedded in critical enterprise workflows.
According to McKinsey’s 2025 Global AI Trust Survey3, the number one barrier to AI adoption is lack of governance and risk-management tools. That’s why we’re putting the following responsible AI features in public preview in the coming weeks:
Task adherence: Help agents stay aligned with assigned tasks.
Prompt shields with spotlighting: Protect against prompt injection and spotlight risky behavior.
PII detection: Identify and manage sensitive data.
These capabilities are built into Azure AI Foundry, helping organizations build with confidence and comply with internal and external standards.
Customer momentum
Azure AI Foundry solutions are helping over 70,000 organizations worldwide—from digital natives to enterprise companies—transform AI innovation into practical results. For example:
Commerzbank: Commerzbank is piloting Microsoft Agent Framework to power avatar-driven customer support, enabling more natural, accessible, and compliant customer interactions.
The new Microsoft Agent Framework simplifies coding, reduces efforts and fully supports MCP for agentic solutions. We are really looking forward to the productive usage of container-based Azure AI Foundry agents, which significantly reduces workload in IT operations.
— Gerald Ertl, Managing Director/Head of Digital Banking Solutions, Commerzbank AG
Citrix: Citrix is exploring how they can use agentic AI within virtual desktop infrastructure (VDI) environments to improve enterprise productivity and efficiency.
Citrix has always embraced flexible ways of working as the leader in secure work. As we move into a world where agentic AI works side-by-side with us, we’re excited to enable that also within workspaces that our customers already use every day. Microsoft’s Agent Framework brings a modern, developer-first approach to building agents. With support for key APIs and languages, and native adoption of emerging protocols for tool calling and observability, it enables intuitive development of agents on Azure AI Foundry without compromising developer control. We are eager to leverage the framework to deliver on our vision – enterprise-scale, production-ready AI agents for our customers.
— George Tsolis, Distinguished Engineer, Citrix
TCS: Tata Consultancy Services is actively building a multi-agent practice on the Microsoft Agent Framework, with several initiatives underway that showcase their strategic investment and technical depth, including agentic solutions for finance, IT operations, and retail.
Adopting Microsoft Agent Framework is not just a technological advancement, but a bold step towards reimagining industry value chains. By harnessing Agentic AI and Frontier models, we enable our teams to build flexible, scalable, enterprise-grade solutions that transform workflows and deliver value across platforms. True leadership is about empowering innovation, embracing change, and fostering an environment where agility and collaboration drive excellence.
— Girish Phadke, Head, Microsoft Azure Practice, TCS
Sitecore: Sitecore is developing a solution that enables marketers to interact seamlessly with the platform by automating tasks across the entire content supply chain—from creating and managing web experiences to handling digital assets—using intelligent agents.
By partnering with Microsoft to leverage its new Microsoft Agent Framework, Sitecore can bring together the best of both worlds: the flexibility to power fully non-deterministic agentic orchestrations and the reliability to run more deterministic, repeatable agents. At the same time, we benefit from Microsoft’s enterprise-grade observability and telemetry, ensuring that these orchestrations are not only powerful but also secure, measurable, and production-ready.
— Mo Cherif, VP of AI, Sitecore
Elastic: Elasticsearch supports a native connector to Microsoft Agent Framework, enabling developers to seamlessly integrate enterprise data into intelligent agents and workflows.
Elasticsearch is the context engineering platform and vector database of choice for organizations to store and search their most valuable operational and business data. With the new Microsoft Agent Framework connector, developers can now bring the most relevant organizational context directly into intelligent agents and multi-agent workflows. This makes it easier than ever to build production-ready AI solutions that combine the reasoning power of agents with the speed and scale of Elasticsearch.
— Steve Kearns, General Manager Search Solutions, Elastic
A trusted agent factory for developers
Azure AI Foundry is more than a platform—it’s a trusted agent factory for developers and enterprises. Whether you’re a CIO looking to scale AI responsibly, a security architect focused on governance, or a developer building the next generation of intelligent agents, Azure AI Foundry provides the tools, frameworks, and trust you need.
Microsoft stands out in the AI landscape with its commitment to open standards, interoperability, and responsible AI. The Microsoft Agent Framework, now in public preview, is a unified, enterprise-grade framework that integrates cutting-edge research and allows developers to seamlessly orchestrate multi-agent systems with built-in observability, durability, and compliance.
Unlike other solutions, our framework supports integration with any API via OpenAPI, collaboration across runtimes with Agent2Agent (A2A), and dynamic tool connections using MCP. This ensures developers can reduce context-switching and stay in flow, accelerating innovation.
The open-source nature of the framework invites developers to contribute and shape the future of agentic AI, making it a truly collaborative and forward-thinking platform. With Microsoft, organizations can trust that their AI systems will be powerful, efficient, responsible, and secure, addressing the top barriers to AI adoption identified in McKinsey’s 2025 Global AI Trust Survey.
Learn more about Azure AI Foundry
1 PwC’s AI Agent Survey.
2 AI adoption is rising, but friction persists.
3 Insights on responsible AI from the Global AI Trust Maturity Survey.
The post Introducing Microsoft Agent Framework appeared first on Microsoft Azure Blog.
Quelle: Azure
I’ve been experimenting with local models for a while now, and the progress in making them accessible has been exciting. Initial experiences are often fantastic, many models, like Gemma 3 270M, are lightweight enough to run on common hardware. This potential for broad deployment is a major draw.
However, as I’ve tried to build meaningful, specialized applications with these smaller models, I’ve consistently encountered challenges in achieving the necessary performance for complex tasks. For instance, in a recent experiment testing the tool-calling efficiency of various models, we observed that many local models (and even several remote ones) struggled to meet the required performance benchmarks. This realization prompted a shift in my strategy.
I’ve come to appreciate that simply relying on small, general-purpose models is often insufficient for achieving truly effective results on specific, demanding tasks. Even larger models can require significant effort to reach acceptable levels of performance and efficiency.
And yet, the potential of local models is too compelling to set aside. The advantages are significant:
Privacy
Offline capabilities
No token usage costs
No more “overloaded” error messages
So I started looking for alternatives, and that’s when I came across Unsloth, a project designed to make fine-tuning models much faster and more accessible. Its growing popularity (star history) made me curious enough to give it a try.
In this post, I’ll walk you through fine-tuning a sub-1GB model to redact sensitive info without breaking your Python setup. With Docker Offload and Unsloth, you can go from a baseline model to a portable, shareable GGUF artifact on Docker Hub in less than 30 minutes. In part 2 of this post, I will share the detailed steps of fine-tuning the model.
Challenges of fine-tuning models
Setting up the right environment to fine-tune models can be… painful. It’s fragile, error-prone, and honestly a little scary at times. I always seem to break my Python environment one way or another, and I lose hours just wrestling with dependencies and runtime versions before I can even start training.
Fortunately, the folks at Unsloth solved this with a ready-to-use Docker image. Instead of wasting time (and patience) setting everything up, I can just run a container and get started immediately.
Of course, there’s still the hardware requirement. I work on a MacBook Pro, and Unsloth doesn’t support MacBooks natively, so normally, that would be a deal-breaker.
But here’s where Docker Offload comes in. With Offload, I can spin up GPU-backed resources in the cloud and tap into NVIDIA acceleration, all while keeping my local workflow. That means I now have everything I need to fine-tune models, without fighting my laptop.
Let’s go for it.
How to fine-tune models locally with Unsloth and Docker
Can a model smaller than 1GB reliably mask personally identifiable information (PII)?
Here’s the test input:
This is an example of text that contains some data. The author of this text is Ignacio López Luna, but everybody calls him Ignasi. His ID number is 123456789. He has a son named Arnau López, who was born on 21-07-2021.
Desired output:
This is an example of text that contains some data. The author of this text is [MASKED] [MASKED], but everybody calls him [MASKED]. His ID number is [MASKED]. He has a son named [MASKED], who was born on [MASKED].
When tested with Gemma 3 270M using Docker Model Runner, the output was:
[PERSON]
Clearly, not usable. Time to fine-tune.
Step 1: Clone the example project
git clone https://github.com/ilopezluna/fine-tuning-examples.git
cd fine-tuning-examples/pii-masking
The project contains a ready to use python script to fine tune Gemma 3 using the pii-masking-400k dataset from ai4privacy.
Step 2: Start Docker Offload (with GPU)
docker offload start
Select your account.
Answer Yes when asked about GPU support (you’ll get an NVIDIA L4-backed instance).
Check status:
docker offload status
See the Docker Offload Quickstart guide.
Step 3: Run the Unsloth container
The official Unsloth image includes Jupyter and some example notebooks. You can start it like this:
docker run -d -e JUPYTER_PORT=8000
-e JUPYTER_PASSWORD="mypassword"
-e USER_PASSWORD="unsloth2024"
-p 8000:8000
-v $(pwd):/workspace/work
–gpus all
unsloth/unsloth
Now, let’s attach a shell to the container:
docker exec -it $(docker ps -q) bash
Useful paths inside the container:
/workspace/unsloth-notebooks/ → example fine-tuning notebooks
/workspace/work/ → your mounted working directory
Thanks to Docker Offload (with Mutagen under the hood), the folder /workspace/work/ stays in sync between cloud GPU and local dev machine.
Step 4: Fine-tune
The script finetune.py is a small training loop built around Unsloth. Its purpose is to take a base language model and adapt it to a new task using supervised fine-tuning with LoRA. In this example, the model is trained on a dataset that teaches it how to mask personally identifiable information (PII) in text.
LoRA makes the process lightweight: instead of updating all of the model’s parameters, it adds small adapter layers and only trains those. That means the fine-tune runs quickly, fits on a single GPU, and produces a compact set of weights you can later merge back into the base model.
When you run:
unsloth@46b6d7d46c1a:/workspace$ cd work
unsloth@46b6d7d46c1a:/workspace/work$ python finetune.py
Unsloth: Will patch your computer to enable 2x faster free finetuning.
[…]
The script loads the base model, prepares the dataset, runs a short supervised fine-tuning pass, and saves the resulting LoRA weights into your mounted /workspace/work/ folder. Thanks to Docker Offload, those results are also synced back to your local machine automatically.
The whole training run is designed to complete in under 20 minutes on a modern GPU, leaving you with a model that has “learned” the new masking behavior and is ready for conversion in the next step.
For a deeper walkthrough of how the dataset is built, why it’s important and how LoRA is configured, stay tuned for part 2 of this blog!
Step 5: Convert to GGUF
At this point you’ll have the fine-tuned model artifacts sitting under /workspace/work/.
To package the model for Docker Hub and Docker Model Runner usage, it must be in GGUF format. (Unsloth will support this directly soon, but for now we convert manually.)
unsloth@1b9b5b5cfd49:/workspace/work$ cd ..
unsloth@1b9b5b5cfd49:/workspace$ git clone https://github.com/ggml-org/llama.cpp
Cloning into 'llama.cpp'…
[…]
Resolving deltas: 100% (45613/45613), done.
unsloth@1b9b5b5cfd49:/workspace$ python ./llama.cpp/convert_hf_to_gguf.py work/result/ –outfile work/result.gguf
[…]
INFO:hf-to-gguf:Model successfully exported to work/result.gguf
Next, check that the file already exists locally (this indicates the automatic Mutagen-powered file sync process did finish):
unsloth@46b6d7d46c1a:/workspace$ exit
exit
((.env3.12) ) ilopezluna@localhost pii-masking % ls -alh result.gguf
-rw-r–r–@ 1 ilopezluna staff 518M Sep 23 15:58 result.gguf
At this point, you can stop Docker Offload:
docker offload stop
Step 6: Package and share on Docker Hub
Now let’s package the fine-tuned model and push it to Docker Hub:
((.env3.12) ) ilopezluna@localhost pii-masking % docker model package –gguf /Users/ilopezluna/Projects/fine-tuning-examples/pii-masking/result.gguf ignaciolopezluna020/my-awesome-model:version1 –push
Adding GGUF file from "/Users/ilopezluna/Projects/fine-tuning-examples/pii-masking/result.gguf"
Pushing model to registry…
Uploaded: 517.69 MB
Model pushed successfully
You can find more details on distributing models in the Docker blog on packaging models.
Step 7: Try the results!
Finally, run the fine-tuned model using Docker Model Runner:
docker model run ignaciolopezluna020/my-awesome-model:version1 "Mask all PII in the following text. Replace each entity with the exact UPPERCASE label in square brackets (e.g., [PERSON], [EMAIL], [PHONE], [USERNAME], [ADDRESS], [CREDIT_CARD], [TIME], etc.). Preserve all non-PII text, whitespace, ' ' and punctuation exactly. Return ONLY the redacted text. Text: This is an example of text that contains some data. The author of this text is Ignacio López Luna, but everybody calls him Ignasi. His ID number is 123456789. He has a son named Arnau López, who was born on 21-07-2021"
This is an example of text that contains some data. The author of this text is [GIVENNAME_1] [SURNAME_1], but everybody calls him [GIVENNAME_1]. His ID number is [IDCARDNUM_1]. He has a son named [GIVENNAME_1] [SURNAME_1], who was born on [DATEOFBIRTH_1]
Just compare with the original Gemma 3 270M output:
((.env3.12) ) ilopezluna@F2D5QD4D6C pii-masking % docker model run ai/gemma3:270M-F16 "Mask all PII in the following text. Replace each entity with the exact UPPERCASE label in square brackets (e.g., [PERSON], [EMAIL], [PHONE], [USERNAME], [ADDRESS], [CREDIT_CARD], [TIME], etc.). Preserve all non-PII text, whitespace, ' ' and punctuation exactly. Return ONLY the redacted text. Text: This is an example of text that contains some data. The author of this text is Ignacio López Luna, but everybody calls him Ignasi. His ID number is 123456789. He has a son named Arnau López, who was born on 21-07-2021"
[PERSON]
The fine tuned model is far more useful, and now it’s already published on Docker Hub for anyone to try.
Why fine-tuning models with Docker matters
This experiment shows that small local models don’t have to stay as “toys” or curiosities. With the right tooling, they can become practical, specialized assistants for real-world problems.
Speed: Fine-tuning a sub-1GB model took under 20 minutes with Unsloth and Docker Offload. That’s fast enough for iteration and experimentation.
Accessibility: Even on a machine without a GPU, Docker Offload unlocked GPU-backed training without extra hardware.
Portability: Once packaged, the model is easy to share, and runs anywhere thanks to Docker.
Utility: Instead of producing vague or useless answers, the fine-tuned model reliably performs one job, masking PII, something that could be immediately valuable in many workflows.
This is the power of fine-tuning models: turning small, general-purpose models into focused, reliable tools. And with Docker’s ecosystem, you don’t need to be an ML researcher with a huge workstation to make it happen. You can train, test, package, and share, all with familiar Docker workflows.
So next time you think “small models aren’t useful”, remember, with a bit of fine-tuning, they absolutely can be.
This takes small local models from “interesting demo” to practical, usable tools.
We’re building this together!
Docker Model Runner is a community-friendly project at its core, and its future is shaped by contributors like you. If you find this tool useful, please head over to our GitHub repository. Show your support by giving us a star, fork the project to experiment with your own ideas, and contribute. Whether it’s improving documentation, fixing a bug, or a new feature, every contribution helps. Let’s build the future of model deployment together!
Start with Docker Offload for GPU on demand →
Learn more
Check out Model Runner General Availability announcement
Visit our Model Runner GitHub repo!
Learn how Compose makes building AI apps and agents easier
Check out Unsloth documentation for more details on the Unsloth Docker image.
Quelle: https://blog.docker.com/feed/