Neue Regeln von Google: F-Droid warnt vor Ende von alternativen App-Stores
F-Droid befürchtet einen Missbrauch neuer Sicherheitsregeln für einen Ausbau von Googles App-Monopol. (Android, Google)
Quelle: Golem

F-Droid befürchtet einen Missbrauch neuer Sicherheitsregeln für einen Ausbau von Googles App-Monopol. (Android, Google)
Quelle: Golem

Amoled-Display, gute Akkulaufzeit und Taschenlampe: Suunto veröffentlicht mit der Vertical 2 eine preisgünstige Konkurrenz zur Garmin Fenix. (Suunto, Smartwatch)
Quelle: Golem

OpenAI integriert eine E-Commerce-Funktion in ChatGPT – Nutzer können Produkte direkt im Chat kaufen, ohne die Plattform zu verlassen. (ChatGPT, KI)
Quelle: Golem

Im Podcast reden wir über den Commodore-Computer, dessen Fähigkeiten kaum genutzt wurden. (Besser Wissen, Atari)
Quelle: Golem

Romantik bei Star Wars gab es bislang nicht in besonderem Ausmaß, aber Bryce Dallas Howard teasert an, dass sich das bei Ahsoka Staffel 2 ändert. (Star Wars, Disney)
Quelle: Golem
Today’s enterprises are entering a new phase of AI adoption—one where trust, flexibility, and production readiness aren’t optional; they’re foundational. Microsoft has collaborated closely with xAI to bring Grok 4, their most advanced model, to Azure AI Foundry—delivering powerful reasoning within a platform designed for business-ready safety and control.
Check out the Azure AI Foundry Grok 4 model card
Grok 4 undeniably has exceptional performance. With a 128K-token context window, native tool use, and integrated web search, it pushes the boundaries of what’s possible in contextual reasoning and dynamic response generation. But performance alone isn’t enough. AI at the frontier must also be accountable. Over the last month, xAI and Microsoft have worked closely to enhance responsible design. The team has evaluated from a responsible AI perspective, putting Grok 4 through a suite of safety tests and compliance checks. Azure AI Content Safety is on by default, adding another layer of protection for enterprise use. Please see the Foundry model card for more information about model safety.
In this blog, we’ll explore what makes Grok 4 stand out, how it compares to other frontier models, and how developers can access it via Azure AI Foundry.
Grok 4: Enhanced reasoning, expanded context, and real-time insights
Grok models were trained on xAI’s Colossus supercomputer, utilizing a massive compute infrastructure that xAI claims delivers a 10 times leap in training scale compared to Grok 3. Grok 4’s architecture marks a significant shift from its predecessors, emphasizing reinforcement learning (RL) and multi-agent systems. According to xAI, the model prioritizes reasoning over traditional pre-training, with a heavy focus on RL to refine its problem-solving capabilities.
Key architectural highlights include:
First-principles reasoning: “think mode”
One of Grok 4’s headline features is its first-principles reasoning ability. Essentially, the model tries to “think” like a scientist or detective, breaking problems down step by step. Instead of just blurting out an answer, Grok 4 can work through the logic internally and refine its response. It has strong proficiency in math (solving competition-level problems), science, and humanities questions. Early users have noted it excels at logic puzzles and nuanced reasoning better than some incumbent models, often finding correct answers where others get confused. Put simply, Grok 4 doesn’t just recall information—it actively reasons through problems. This focus on logical consistency makes it especially attractive if your use case requires step-by-step answers (think of research analysis, tutoring, or complex troubleshooting scenarios).
Example prompt: Explain how you would generate electricity on Mars if you had no existing infrastructure. Start from first principles: what are the fundamental resources, constraints, and physical laws you would use?
Extended context window
Perhaps one of Grok 4’s most impressive technical feats is its handling of extremely large contexts. The model is built to process and remember massive amounts of text in one go. In practical terms, this means Grok 4 can ingest extensive documents, lengthy research papers, or even a large codebase, and then reason about them without needing to truncate or forget earlier parts. For use cases like:
Document analysis: You could feed in hundreds of pages of a document and ask Grok to summarize, find inconsistencies, or answer specific questions. Grok 4 is far less likely to miss the details simply because it ran out of context window, compared to other models.
Research and academia: Load an entire academic journal issue or a very long historical text and have Grok analyze it or answer questions across the whole text. It could, for example, take in all of Shakespeare’s plays and answer a question that requires connecting info from multiple plays.
Code repositories: Developers could input an entire code repository or multiple files (up to millions of characters of code) and ask Grok 4 to find where a certain function is defined, or to detect bugs across the codebase. This is huge for understanding large legacy projects.
xAI has claimed that this is not just “memory” but “smart memory.” Grok can intelligently compress or prioritize information in very long inputs, remembering the crucial pieces more strongly. For the end user or developer, the takeaway is: Grok 4 can handle very large input texts in one shot. This reduces the need to chop up documents or code and manage context fragments manually. You can throw a ton of information at it and it can keep the whole thing “in mind” as it responds.
Example prompt: Read this Shakespeare play and find my password (password is buried in the long context text).
Data-aware responses and real-time insights
Another strength of Grok 4 is how it can integrate external data sources and trending information into its answers—effectively acting as a data analyst or real-time researcher when needed. It understands that sometimes the best answer needs to come from outside its training data, and it has mechanisms to retrieve and incorporate that external data. It turns the chatbot into more of an autonomous research assistant. You ask a question, it might go read a few things online, and come back with an answer that’s enriched by real data. Of course, caution is needed—live data can sometimes be incorrect, or the model might pick up on biased sources; one should verify critical outputs.
Example prompt: Check the latest news on global AI regulations (past 48 hours).
Summarize the top 3 developments.
Highlight which regions or governments are driving the changes.
Explain what impact these updates could have on companies deploying foundation models.
Provide the sources you referenced.
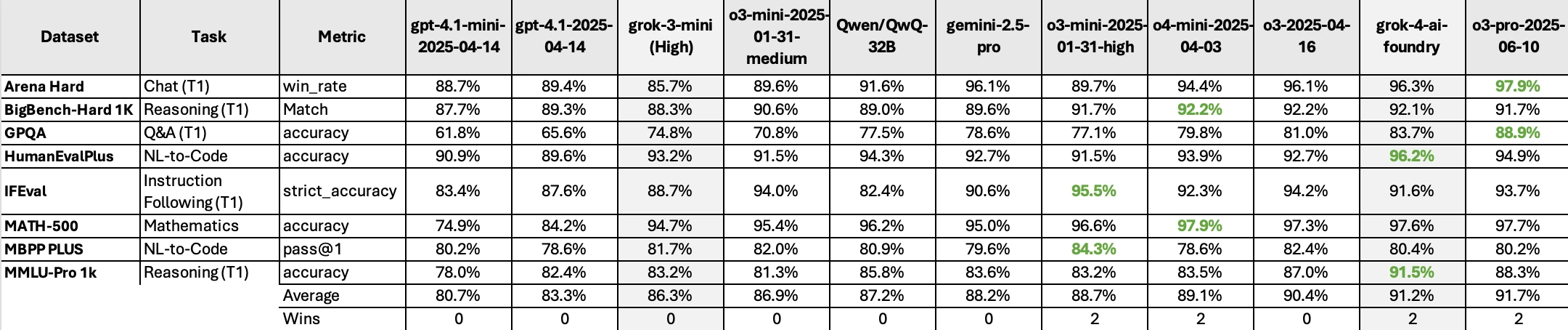
Stacking up Grok 4: How it performs against top models
Grok 4 showcases impressive capabilities on high-complexity tasks. These benchmarks underscore Grok 4’s leading-edge capabilities in high-level reasoning, STEM disciplines, complex problem-solving, and industry-specific tasks. These benchmark numbers are calculated using our own internal Azure AI Foundry benchmarking service, which we use to compare models across a set of industry standard benchmarks.
Family of Grok models
In addition to Grok 4, Azure AI Foundry also has 3 additional Grok models already available.
Grok 4 Fast Reasoning is optimized for tasks requiring logical inference, problem-solving, and complex decision-making, making it ideal for analytical applications.
Grok 4 Fast Non-Reasoning focuses on speed and efficiency for straightforward tasks like summarization or classification, without deep logical processing.
Grok Code Fast 1 is tailored specifically for code generation and debugging, excelling in programming-related tasks across multiple languages.
While all three models prioritize speed, their core strengths differ: reasoning for logic-heavy tasks, non-reasoning for lightweight operations, and code for developer workflows.
Pricing including Azure AI Content Safety:
Model Deployment Type Price $/1M tokens Grok 4 Global Standard Input- $5.5 Output- $27.5
Get started with Grok 4 in Azure AI Foundry
Lead with insight, build with trust. Grok 4 unlocks frontier‑level reasoning and real‑time intelligence, but it is not a deploy and forget model. Pair Azure’s guardrails with your own domain checks, monitor outputs against evolving standards, and iterate responsibly—while we continue to harden the model and disclose new safety scores. Please see the Azure AI Foundry Grok 4 model card for more information about model safety.
Head over to ai.azure.com, search for “Grok,” and start exploring what these powerful models can do.
Azure AI Foundry
Explore the Grok 4 model in Azure AI Foundry.
Try it now
The post Grok 4 is now available in Azure AI Foundry: Unlock frontier intelligence and business-ready capabilities appeared first on Microsoft Azure Blog.
Quelle: Azure
Today, we want to highlight Docker MCP Toolkit, a free feature in Docker Desktop that gives you access to more than 200 MCP servers. It’s the easiest and most secure way to run MCP servers locally for your AI agents and workflows. The MCP toolkit allows you to isolate MCP servers in containers, securely configure individual servers, environment variables, API keys, and other secrets, and provides security checks both for tool calls and the resulting outputs. Let’s look at a few examples to see it in action.
Get started in seconds: Explore 200+ curated MCP servers and launch them with a single click
Docker MCP Catalog includes hundreds of curated MCP servers for development, automation, deployment, productivity, and data analysis.
You can enable MCP servers and configure them with just a few clicks right in Docker Desktop. And on top of that automatically configure your AI assistants like Goose, LM Studio, or Claude Desktop and more to use MCP Toolkit too.
Here are two examples where we configure Obsidian, GitHub, and Docker Hub MCP servers from Docker MCP Toolkit to work in LM Studio and Claude Desktop.
Build advanced MCP workflows: Connect customer feedback in Notion directly to GitHub Issues
And you can of course enable setups for more complex workflows involving data analysis. In the video below, we use Docker Compose to declaratively configure MCP servers through the MCP Gateway, connected to the MCP Toolkit in Docker Desktop. The demo shows integrations with Notion, GitHub MCP servers, and our sample coding assistant, Crush by Charmbracelet.
We instruct it to inspect Notion for Customer Feedback information and summarize feature requests as issues on GitHub. Which is a nice little example of AI helping with your essential developer workflows.
Learn more about setting up your own custom MCP servers
And of course, you can add your custom MCP servers to the MCP Toolkit or mcp-gateway based setups. Check out this more involved video.
Or read this insightful article about building custom Node.js sandbox MCP server (article) and plugging it into a coding agent powered by one of the world’s fastest inference engine by Cerebras.
Conclusion
The Docker MCP Catalog and Toolkit bring MCP servers to your local dev setup, making it easy and secure to supercharge AI agents and coding assistants. With access to 200+ servers in the MCP Catalog, you can securely connect tools like Claude, LM Studio, Goose, and more, just a few clicks away in MCP Toolkit. Check out the video above for inspiration to start building your own MCP workflows! Download or open Docker Desktop today, then click MCP Toolkit to get started!
Learn more
Explore the MCP Catalog: Discover containerized, security-hardened MCP servers
Download Docker Desktop to get started with the MCP Toolkit: Run MCP servers easily and securely
Check out our MCP Horror Stories series to see common MCP security pitfalls and how you can avoid them
Quelle: https://blog.docker.com/feed/
Development teams are under growing pressure to secure their software supply chains. Teams need trusted images, streamlined deployments, and compliance-ready tooling from partners they can rely on long term. Our customers have made it clear that they’re not just looking for one-off vendors. They’re looking for true security partners across development and deployment.
That’s why we are now offering Helm charts in the Docker Hardened Images (DHI) Catalog. These charts simplify Kubernetes deployments and make Docker a trusted security partner across the development and deployment lifecycle.
Bringing security and simplicity to Helm deployments
Helm charts are the most popular way to package and deploy applications to Kubernetes, with 75% of users preferring to use them, according to CNCF surveys. With security incidents making headlines more often, confidence now depends on having security and traceability built into every deployment.
Helm charts in the DHI Catalog make it simple to deploy hardened images to production Kubernetes environments. Teams no longer need to worry about insecure configurations, unverified sources, or vulnerable dependencies. Each chart is built with our hardened build system, providing signed provenance and clear traceability so you know exactly what you are deploying every time.
Supporting customers in the wake of Broadcom changes
Broadcom recently announced changes to Bitnami’s distribution model. Most images and charts have moved into a commercial subscription, older versions are archived without updates, and only a limited set of :latest tags remain free for use.
For teams affected by this change, Docker offers a clear path forward:
Free Docker Official Images, which can be paired with upstream Helm charts for stable, open source deployments
Docker Hardened Images with Helm charts in the DHI Catalog for enterprise-grade security and compliance
Many teams have relied on Bitnami for images and charts. Helm charts in the DHI Catalog now give teams the option to partner with Docker for secure, compliant deployments, with consistent coverage from development through deployment.
If your team is evaluating alternatives, we invite you to join the beta program. Sign up through our interest form to test Helm charts in the DHI Catalog and help guide their development.
What Helm charts in the DHI Catalog offer
Helm charts in the DHI Catalog are available today in beta. Beta offerings are early versions of future functionality that give customers the opportunity to test, validate, and share feedback. Your input directly shapes how we refine these charts before general availability.
The Helm charts in the DHI Catalog include:
DHI by default: Every chart automatically references Docker Hardened Images, ensuring deployments inherit DHI’s security, compliance, and SLA-backed patching without manual intervention.
Regular updates: New upstream versions and DHI CVE fixes automatically flow into chart releases.
Enterprise-grade security: Charts are built with our SLSA Level 3 build system and include signed provenance for compliance.
Customer-driven roadmap: We are guided by your feedback, so your input has a direct impact on what we prioritize.
Docker’s Trusted Image Catalogs: DHI and more
It’s worth noting that whether you’re looking for community continuity or enterprise-grade assurance, Docker has you covered:
Docker Official Images (DOI)
Docker Hardened Images (DHI)
Free and widely available
Enterprise-ready
Maintained with upstream communities
Minimal, non-root by default, near-zero CVEs
Billions of pulls every month
SLA-backed with fast CVE patching
Stable, trustworthy foundation
Compliance-ready with signed provenance and SBOMs
Together, DOI and DHI give organizations choice: a free, stable foundation for development, or an enterprise-grade hardened catalog with charts for production. If you rely on Docker Official Images, rest assured: they remain free, stable, and community-driven. You can rely on them for a solid foundation for your open source workloads.
Join the beta: Help shape Helm charts in the DHI Catalog
Helm charts in the DHI Catalog are now in invite-only beta as of October 2025. We are working closely with a set of customers to prioritize which charts matter most and ensure migration is smooth.
Participation is open via our interest form, and we welcome your feedback.
Sign up for the beta today!
Quelle: https://blog.docker.com/feed/
Customers can now use Claude Sonnet 4.5 in Amazon Bedrock, a fully managed service that offers a choice of high- performing foundation models from leading AI companies. Claude Sonnet 4.5 is Anthropic’s most intelligent model, excelling at complex agents, coding, and long-horizon tasks while maintaining optimal speed and cost-efficiency for high-volume use-cases. Claude Sonnet 4.5 currently leads the SWE-bench Verified benchmarks with enhanced instruction following, better code improvement identification, stronger refactoring judgment, and more effective production-ready code generation. This model excels at powering long-running agents that tackle complex, multi-step tasks requiring peak accuracy—like autonomously managing multi-channel marketing campaigns or orchestrating cross-functional enterprise workflows. In cybersecurity, it can help teams shift from reactive detection to proactive defense by autonomously patching vulnerabilities. For financial services, it can handle everything from analysis to advanced predictive modeling. Through the Amazon Bedrock API, Claude can now automatically edit context to clear stale information from past tool calls, allowing you to maximize the model’s context. A new memory tool lets Claude store and consult information outside the context window to boost accuracy and performance. Claude Sonnet 4.5 is now available in Amazon Bedrock via global cross region inference in multiple locations. To view the full list of available regions, refer to the documentation. To get started with Claude Sonnet 4.5 in Amazon Bedrock, read the News Blog, visit the Amazon Bedrock console, Anthropic’s Claude in Amazon Bedrock product page, and the Amazon Bedrock pricing page.
Quelle: aws.amazon.com
Amazon Connect dashboards now supports selecting and comparing any time ranges enabling you to focus on specific, relevant data and perform in-depth analysis up to a maximum of 35 days in the last 3 months. Additionally, you can now select Week to Date and Month to Date time ranges. For example, if a new sales campaign launches at the start of the current week, a contact center manager can compare the current week’s handle time or contact volume with the same time range last week using Week to Date, to decide if additional agents are required to handle the increasing contact volume and maintain service levels. Amazon Connect Contact Lens dashboards are available in all AWS commercial and AWS GovCloud (US-West) regions where Amazon Connect is offered. To learn more about dashboards, see the Amazon Connect Administrator Guide. To learn more about Amazon Connect, the AWS cloud-based contact center, please visit the Amazon Connect website.
Quelle: aws.amazon.com