Ladekran: Pender Lift hebt mühelos E-Bikes auf Autodächer
Pender hat einen hydraulischen Kran entwickelt, der schwere E-Bikes in den Dachgepäckträger auf dem Autodach hebt. (E-Bike, Auto)
Quelle: Golem

Pender hat einen hydraulischen Kran entwickelt, der schwere E-Bikes in den Dachgepäckträger auf dem Autodach hebt. (E-Bike, Auto)
Quelle: Golem

Die Anzeichen verdichten sich, dass Tesla in Kürze eine runderneuerte Version seines Model 3 auf den Markt bringen wird. (Tesla Model 3, Elektroauto)
Quelle: Golem
The sealed class is a unique and forced construct that lets creators designate bounded class pecking orders with a bounded bunch of subclasses. It brings additional control and flexibility to the class-based paradigm, enabling the creation of strong and expressive code. We’ll go through the concept of sealed classes in detail, including their objective, use, and privileges.
The post Kotlin Sealed Class: Exploring Powerful Abstractions appeared first on ThoughtsOnCloud.
Quelle: Thoughts on Cloud

Du bist Entwickler und möchtest aktiv an der Weiterentwicklung der reichweitenstarken Webseiten und internen Tools von Computec mitwirken? Dann bewirb dich! (Aus dem Verlag, Wirtschaft)
Quelle: Golem

Oft helfen selbst starke Kühler kaum, den Prozessor auf niedriger Temperatur zu halten. Wir erklären, warum CPUs besonders sind und was man dennoch tun kann. Von Martin Böckmann (Kühlung, Prozessor)
Quelle: Golem

Bei Saturn sind aktuell jede Menge Gaming-Laptops mit AMD-Prozessoren im Angebot. Rabatte von bis zu 400 Euro sind möglich. (Spielenotebook, AMD)
Quelle: Golem
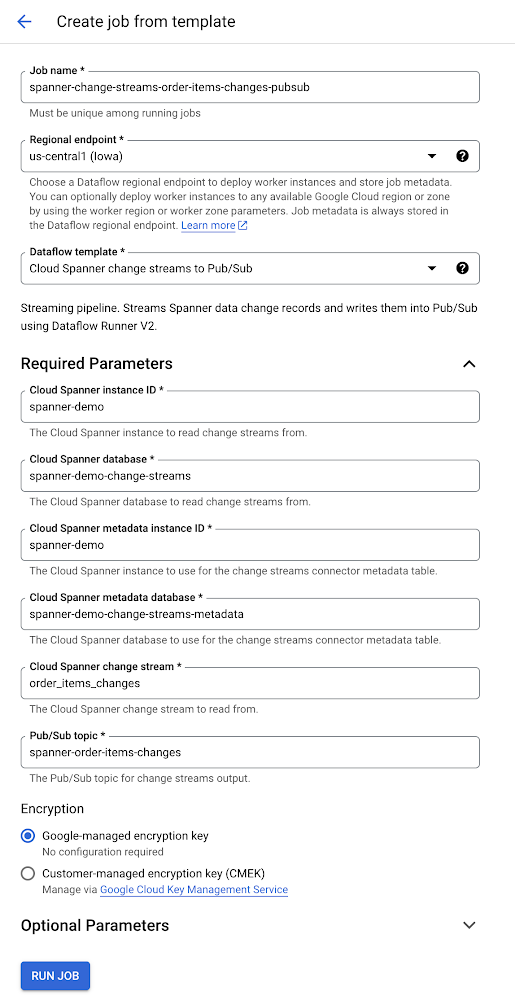
Since its launch, Cloud Spanner change streams has seen broad adoption by Spanner customers in healthcare, retail, financial services, and other industries. This blog post provides an overview of the latest updates to Cloud Spanner change streams and how they can be used to build event-driven applications.A change stream watches for changes to your Spanner database (inserts, updates, and deletes) and streams out these changes in near real-time. One of the most common uses of change streams is replicating Spanner data to BigQuery for analytics. With change streams, it’s as easy as writing Data definition language (DDL) to create a change stream on the desired tables and configuring Dataflow to replicate these changes to BigQuery so that you can take advantage of BigQuery’s advanced analytic capabilities.Yet analytics is just the start of what change streams can enable. Pub/Sub and Apache Kafka are asynchronous and scalable messaging services that decouple the services that produce messages from the services that process those messages. With support for Pub/Sub and Apache Kafka, Spanner change streams now lets you use Spanner transactional data to build event-driven applications.An example of an event-driven architecture is an order system that triggers inventory updates to an inventory management system whenever orders are placed. In this example, orders are saved in a table called order_items. Consequently, changes on this table will trigger events in the inventory system. To create a change stream that tracks all changes made order_items, run the following DDL statement:code_block[StructValue([(u’code’, u’CREATE CHANGE STREAM order_items_changes FOR order_items’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3ef9f6d0c6d0>)])]Once the order_items_changes change stream is created, you can create event streaming pipelines to Pub/Sub and Kafka.Creating an event streaming pipeline to Pub/SubThe change streams Pub/Sub Dataflow template lets you create Dataflow jobs that send change events from Spanner to Pub/Sub and build these kinds of event streaming pipelines.Once the Dataflow job is running, we can simulate inventory changes by inserting and updating order items in the Spanner database:code_block[StructValue([(u’code’, u”INSERT INTO order_items (order_item_id, order_id, article_id, quantity)rnVALUES (rn ‘5fb2dcaa-2513-1337-9b50-cc4c56a06fda’,rn ‘b79a2147-bf9a-4b66-9c7f-ab8bc6c38953′, rn ‘f1d7f2f4-1337-4d08-a65e-525ec79a1417′, rn 5rn);”), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3efa0d3d6450>)])]code_block[StructValue([(u’code’, u”UPDATE order_items rnSET quantity = 10 rnWHERE order_item_id = ‘5fb2dcaa-2513-1337-9b50-cc4c56a06fda';”), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3efa0d3d6b90>)])]This causes two change records to be streamed out through Dataflow and published as messages to the given Pub/Sub topic, as shown below:The first Pub/Sub message contains the inventory insert, and the second message contains inventory update.From here, the data can be consumed using any of the many integration options Pub/Sub offers.Creating an event streaming pipeline to Apache KafkaIn many event-driven architectures, Apache Kafka is the central event store and stream-processing platform. With our newly added Debezium-based Kafka connector, you can build event streaming pipelines with Spanner change streams and Apache Kafka. The Kafka connector produces a change event for every insert, update, and delete. It sends groups change event records for each Spanner table into a separate Kafka topic. Client applications then read the Kafka topics that correspond to the database tables of interest, and can react to every row-level event they receive from those topics.The connector has built-in fault-tolerance. As the connector reads changes and produces events, it records the last commit timestamp processed for each change stream partition. If the connector stops for any reason (e.g. communication failures, network problems, or crashes), it simply continues streaming records where it last left off once it restarts.To learn more about the change streams connector for Kafka, see Build change streams connections to Kafka. You can download the change streams connector for Kafka from Debezium.Fine-tuning your event messages with new value capture typesIn the example above, the stream order_items_changed that uses the default value capture type OLD_AND_NEW_VALUES. This means that the Change streams change record includes both the old and new values of a row’s modified columns, along with the primary key of the row. Sometimes, however, you don’t need to capture all that change data. For this reason, we added two new value capture types: NEW_VALUES and NEW_ROW, described below:To continue with our existing example, let’s create another change stream that contains only the new values of changed columns. This is the value capture type with the lowest memory and storage footprint.code_block[StructValue([(u’code’, u”CREATE CHANGE STREAM order_items_changed_values rnFOR order_itemsrnWITH ( value_capture_type = ‘NEW_VALUES’ )”), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3ef9f6e7bf90>)])]The DDL above creates a change stream using the PostgreSQL interface syntax. Read Create and manage change streams to learn more about the DDL for creating change streams for both PostgreSQL and GoogleSQL Spanner databases.SummaryWith change streams, your Spanner data follows you wherever you need it, whether that’s for analytics with BigQuery, for triggering events in downstream applications, or for compliance and archiving. And because change streams are built into Spanner, there’s no software to install, and you get external consistency, high scale, and up to 99.999% availability.With support for Pub/Sub and Kafka, Spanner change streams makes it easier than ever to build event-driven pipelines with whatever flexibility you need for your business.To get started with Spanner, create an instance or try it out for free, or take a Spanner QwiklabTo learn more about Spanner change streams, check out About change streams To learn more about the change streams Dataflow template for Pub/Sub, go to Cloud Spanner change streams to Pub/Sub template To learn more about the change streams connector for Kafka, go to Build change streams connections to Kafka
Quelle: Google Cloud Platform

Memgraph is an open source, in-memory graph database designed with real-time analytics in mind. Providing a high-performance solution, Memgraph caters to developers and data scientists who require immediate, actionable insights from complex, interconnected data.
What sets Memgraph apart is its high-speed data processing ability, delivering performance that makes it significantly faster than other graph databases. This, however, is not achieved at the expense of data integrity or reliability. Memgraph is committed to providing accurate and dependable insights as fast as you need them.
Built entirely on a C++ codebase, Memgraph leverages in-memory storage to handle complex real-time use cases effectively. Support for ACID transactions guarantees data consistency, while the Cypher query language offers a robust toolset for data structuring, manipulation, and exploration.
Graph databases have a broad spectrum of applications. In domains as varied as cybersecurity, credit card fraud detection, energy management, and network optimization, Memgraph can efficiently analyze and traverse complex network structures and relationships within data. This analytical prowess facilitates real-time, in-depth revelations across a broad spectrum of industries and areas of study.
In this article, we’ll show how using Memgraph as a Docker Extension offers a powerful and efficient way to leverage real-time analytics from a graph database.
Architecture of Memgraph
The high-speed performance of Memgraph can be attributed to its unique architecture (Figure 1). Centered around graph models, the database represents data as nodes (entities) and edges (relationships), enabling efficient management of deeply interconnected data essential for a range of modern applications.
In terms of transactions, Memgraph upholds the highest standard. It uses the standardized Cypher query language over the Bolt protocol, facilitating efficient data structuring, manipulation, and exploration.
Figure 1: Components of Memgraph’s architecture.
The key components of Memgraph’s architecture are:
In-memory storage: Memgraph stores data in RAM for low-latency access, ensuring high-speed data retrieval and modifications. This is critical for applications that require real-time insights.
Transaction processing: Memgraph supports ACID (Atomicity, Consistency, Isolation, Durability) transactions, which means it guarantees that all database transactions are processed reliably and in a way that ensures data integrity, including when failures occur.
Query engine: Memgraph uses Cypher, a popular graph query language that’s declarative and expressive, allowing for complex data relationships to be easily retrieved and updated.
Storage engine: While Memgraph primarily operates in memory, it also provides a storage engine that takes care of data durability by persisting data on disk. This ensures that data won’t be lost even if the system crashes or restarts.
High availability and replication: Memgraph’s replication architecture can automatically replicate data across multiple machines, and it supports replication to provide high availability and fault tolerance.
Streaming and integration: Memgraph can connect with various data streams and integrate with different types of data sources, making it a versatile choice for applications that need to process and analyze real-time data.
To provide users with the utmost flexibility and control, Memgraph comprises several key components, each playing a distinct role in delivering seamless performance and user experience:
MemgraphDB — MemgraphDB is the heart of the Memgraph system. It deals with all concurrency problems, consistency issues, and scaling, both in terms of data and algorithm complexity. Using the Cypher query language, MemgraphDB allows users to query data and run algorithms. It also supports both push and pull operations, which means you can query data and run algorithms and get notified when something changes in the data.
Mgconsole — mgconsole is a command-line interface (CLI) used to interact with Memgraph from any terminal or operating system.
Memgraph Lab — Memgraph Lab is a visual user interface for running queries and visualizing graph data. It provides a more interactive experience, enabling users to apply different graph styles, import predefined datasets, and run example queries. It makes data analysis and visualization more intuitive and user-friendly.
MAGE (Memgraph Advanced Graph Extensions) — MAGE is an open source library of graph algorithms and custom Cypher procedures. It enables high-performance processing of demanding graph algorithms on streaming data. With MAGE, users can run a variety of algorithms, from PageRank or community detection to advanced machine learning techniques using graph embeddings. Moreover, MAGE does not limit users to a specific programming language.
Based on those four components, Memgraph offers four different Docker images:
memgraph-platform — Installs MemgraphDB, mgconsole, Memgraph Lab, and MAGE
memgraph-mage — Installs MemgraphDB, mgconsole, and MAGE
memgraph — Installs MemgraphDB and mgconsole
MAGE × NVIDIA cuGraph — Installs everything that you need to run MAGE in combination with NVIDIA cuGraph
With more than 10K downloads from Docker Hub, Memgraph Platform is the most popular Memgraph Docker image, so the team decided to base the Memgraph Docker extension on it. Instructions are available in the documentation if you want to use any of the other images. Let’s look at how to install Memgraph Docker Extension.
Why run Memgraph as a Docker Extension?
Running Memgraph as a Docker Extension offers a streamlined experience to users who are already familiar with Docker Desktop, simplifying the deployment and management of the graph database. Docker provides an ideal environment to bundle, ship, and run Memgraph in a lightweight, isolated setup. This encapsulation not only promotes consistent performance across different systems but also simplifies the setup process.
Moreover, Docker Desktop is the only prerequisite to run Memgraph as an extension. This means that once you have Docker installed, you can easily set up and start using Memgraph, eliminating the need for additional software installations or complex configuration steps.
Getting started
Working with Memgraph as a Docker Extension begins with opening the Docker Desktop (Figure 2). Here are the steps to follow:
Choose Extensions in the left sidebar.
Switch to the Browse tab.
In the Filters drop-down, select the Database category.
Find Memgraph and then select Install.
Figure 2: Installing Memgraph Docker Extension.
That’s it! Once the installation is finished, select Connect now (Figure 3).
Figure 3: Connecting to Memgraph database using Memgraph Lab.
What you see now is Memgraph Lab, a visual user interface designed for running queries and visualizing graph data. With a range of pre-prepared datasets, Memgraph Lab provides an ideal starting point for exploring Memgraph, gaining proficiency in Cypher querying, and effectively visualizing query results.
Importing the Pandora Papers datasets
For the purposes of this article, we will import the Pandora Papers dataset. To import the dataset, choose Datasets in the Memgraph Lab sidebar and then Load Dataset (Figure 4).
Figure 4: Importing the Pandora Papers dataset.
Once the dataset is loaded, select Explore Query Collection to access a selection of predefined queries (Figure 5).
Figure 5: Exploring the Pandora Papers dataset query collection.
Choose one of the queries and select Run Query (Figure 6).
Figure 6: Running the Cypher query.
And voilà! Welcome to the world of graphs. You now have the results of your query (Figure 7). Now that you’ve run your first query, feel free to explore other queries in the Query Collection, import a new dataset, or start adding your own data to the database.
Figure 7: Displaying the query result as a graph.
Conclusion
Memgraph, as a Docker Extension, offers an accessible, powerful, and efficient solution for anyone seeking to leverage real-time analytics from a graph database. Its unique architecture, coupled with a streamlined user interface and a high-speed query engine, allows developers and data scientists to extract immediate, actionable insights from complex, interconnected data.
Moreover, with the integration of Docker, the setup and use of Memgraph become remarkably straightforward, further expanding its appeal to both experienced and novice users alike. The best part is the variety of predefined datasets and queries provided by the Memgraph team, which serve as excellent starting points for users new to the platform.
Whether you’re diving into the world of graph databases for the first time or are an experienced data professional, Memgraph’s Docker Extension offers an intuitive and efficient solution. So, go ahead and install it on Docker Desktop and start exploring the intriguing world of graph databases today. If you have any questions about Memgraph, feel free to join Memgraph’s vibrant community on Discord.
Learn more
Install Memgraph’s Docker Extension.
Get the latest release of Docker Desktop.
Vote on what’s next! Check out our public roadmap.
Have questions? The Docker community is here to help.
New to Docker? Get started.
Quelle: https://blog.docker.com/feed/
Amazon OpenSearch Service bietet jetzt eine einfache, skalierbare und leistungsstarke Vektor-Engine für Amazon OpenSearch Serverless. Ihre Entwickler können diese Vektor-Engine verwenden, um mit Machine Learning (ML) erweiterte Sucherlebnisse und generative Anwendungen für künstliche Intelligenz (KI) zu erstellen, ohne die Vektordatenbankinfrastruktur verwalten zu müssen. Sie können sich auf die Vector Engine für eine kosteneffiziente, sichere serverlose Umgebung verlassen, die Ihren Entwicklern den nahtlosen Übergang vom Anwendungsprototyping zur Produktion ermöglicht.
Quelle: aws.amazon.com
Heute kündigt Amazon AppStream 2.0 Graphics G5-Instances an, die auf der EC2 G5-Familie aufbauen und für grafikintensive Anwendungen und Machine-Learning-Workloads konzipiert sind. Amazon EC2 G5-Instances verfügen über NVIDIA A10G Tensor Core-GPUs und AMD EPYC-Prozessoren der zweiten Generation. Diese Instances können für grafikintensive Anwendungen und Machine-Learning-Inferenz verwendet werden und bieten im Vergleich zu Amazon EC2 G4dn-Instances eine höhere Leistung für das Training einfacher bis mäßig komplexer Modelle für maschinelles Lernen.
Quelle: aws.amazon.com