P41 Plus: Solidigms erste Client-SSD ist da
Einst Intel, heute Tochter von SK Hynix: Mit der P41 Plus gibt es eine erste Client-SSD von Solidigm, die trotz PCIe Gen4 aber eher langsam ist. (Hynix, Intel)
Quelle: Golem

Einst Intel, heute Tochter von SK Hynix: Mit der P41 Plus gibt es eine erste Client-SSD von Solidigm, die trotz PCIe Gen4 aber eher langsam ist. (Hynix, Intel)
Quelle: Golem

In der Gas- und Energiekrise soll in Spanien im öffentlichen Leben Energie eingespart werden. Einen Aufruf zum Homeoffice gibt es auch. (Ukrainekrieg, GreenIT)
Quelle: Golem

Um einen Beschleuniger oder ein Speichermodul an die CPU anzubinden, ist künftig der CXL (Compute Express Link) das Mittel der Wahl. (Prozessor, Intel)
Quelle: Golem

Die App einer Kaffeehauskette hat illegal die Standorte seiner Nutzer gesammelt. Diese sollen nun mit einem Heißgetränk und einer Backware abgespeist werden. (Tracking, Datenschutz)
Quelle: Golem

Google bereitet eine neue Zurück-Geste für Android vor, bei der Nutzer erkennen sollen, wohin diese sie führt. (Android 13, Google)
Quelle: Golem

Der Onexplayer Mini Pro soll in Games durch Alder Lake überzeugen. Zusammen mit viel RAM und einer großen SSD ist er aber nicht billig. (Spielehandheld, Mini-Notebook)
Quelle: Golem
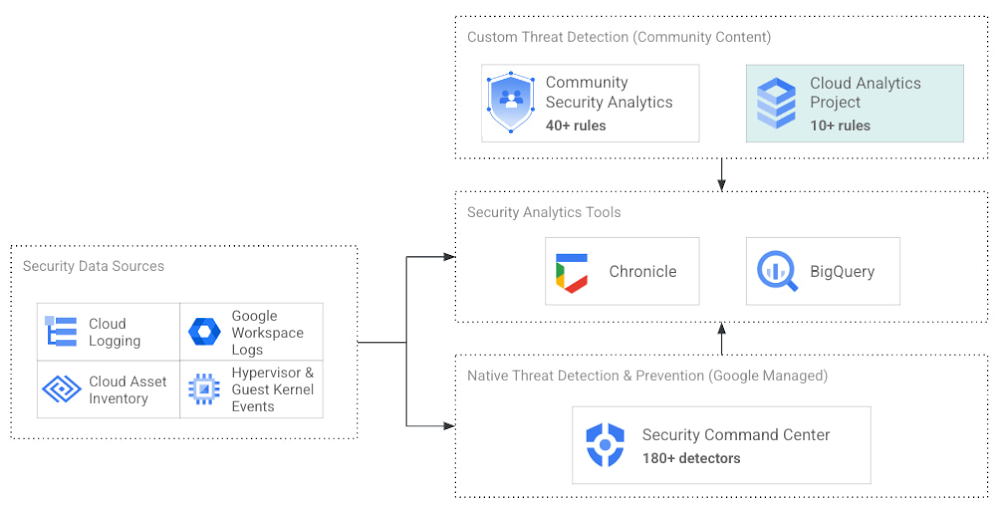
The cybersecurity industry is faced with the tremendous challenge of analyzing growing volumes of security data in a dynamic threat landscape with evolving adversary behaviors. Today’s security data is heterogeneous, including logs and alerts, and often comes from more than one cloud platform. In order to better analyze that data, we’re excited to announce the release of the Cloud Analytics project by the MITRE Engenuity Center for Threat-Informed Defense, and sponsored by Google Cloud and several other industry collaborators.Since 2021, Google Cloud has partnered with the Center to help level the playing field for everyone in the cybersecurity community by developing open-source security analytics. Earlier this year, we introduced Community Security Analytics (CSA) in collaboration with the Center to provide pre-built and customizable queries to help detect threats to your workloads and to audit your cloud usage. The Cloud Analytics project is designed to complement CSA.The Cloud Analytics project includes a foundational set of detection analytics for key tactics, techniques and procedures (TTPs) implemented as vendor-agnostic Sigma rules, along with their adversary emulation plans implemented with CALDERA framework. Here’s a overview of Cloud Analytics project, how it complements Google Cloud’s CSA to benefit threat hunters, and how they both embrace Autonomic Security Operations principles like automation and toil reduction (adopted from SRE) in order to advance the state of threat detection development and continuous detection and response (CD/CR).Both CSA and the Cloud Analytics project are community-driven security analytics resources. You can customize and extend the provided queries, but they take a more do-it-yourself approach—you’re expected to regularly evaluate and tune them to fit your own requirements in terms of threat detection sensitivity and accuracy. For managed threat detection and prevention, check out Security Command Center Premium’s realtime and continuously updated threat detection services including Event Threat Detection, Container Threat Detection, and Virtual Machine Threat Detection. Security Command Center Premium also provides managed misconfiguration and vulnerability detection with Security Health Analytics and Web Security Scanner.Google Cloud Security Foundation: Analytics Tools & ContentCloud Analytics vs Community Security AnalyticsSimilar to CSA, Cloud Analytics can help lower the barrier for threat hunters and detection engineers to create cloud-specific security analytics. Security analytics is complex because it requires:Deep knowledge of diverse security signals (logs, alerts) from different cloud providers along with their specific schemas;Familiarity with adversary behaviors in cloud environments;Ability to emulate such adversarial activity on cloud platforms;Achieving high accuracy in threat detection with low false positives, to avoid alert fatigue and overwhelming your SOC team.The following table summarizes the key differences between Cloud Analytics and CSA:Target platforms and language support by CSA & Cloud Analytics projectTogether, CSA and Cloud Analytics can help you maximize your coverage of the MITRE ATT&CK® framework, while giving you the choice of detection language and analytics engine to use. Given the mapping to TTPs, some of these rules by CSA and Cloud Analytics overlap. However, Cloud Analytics queries are implemented as Sigma rules which can be translated to vendor-specific queries such as Chronicle, Elasticsearch, or Splunk using Sigma CLI or third party-supported uncoder.io, which offers a user interface for query conversion. On the other hand, CSA queries are implemented as YARA-L rules (for Chronicle) and SQL queries (for BigQuery and now Log Analytics). The latter could be manually adapted to specific analytics engines due to the universal nature of SQL.Getting started with Cloud AnalyticsTo get started with the Cloud Analytics project, head over to the GitHub repo to view the latest set of Sigma rules, the associated adversary emulation plan to automatically trigger these rules, and a development blueprint on how to create new Sigma rules based on lessons learned from this project.The following is a list of Google Cloud-specific Sigma rules (and their associated TTPs) provided in this initial release; use these as examples to author new ones covering more TTPs.Sigma rule exampleUsing the canonical use case of detecting when a storage bucket is modified to be publicly accessible, here’s an example Sigma rule (copied below and redacted for brevity):The rule specifies the log source (gcp.audit), the log criteria (storage.googleapis.com service and storage.setIamPermissions method) and the keywords to look for (allUsers, ADD) signaling that a role was granted to all users over a given bucket. To learn more about Sigma syntax, refer to public Sigma docs.However, there could still be false positives such as a Cloud Storage bucket made public for a legitimate reason like publishing static assets for a public website. To avoid alert fatigue and reduce toil on your SOC team, you could build more sophisticated detections based on multiple individual Sigma rules using Sigma Correlations.Using our example, let’s refine the accuracy of this detection by correlating it with another pre-built Sigma rule which detects when a new user identity is added to a privileged group. Such privilege escalation likely occurred before the adversary gained permission to modify access of the Cloud Storage bucket. Cloud Analytics provides an example of such correlation Sigma rule chaining these two separate events.What’s nextThe Cloud Analytics project aims to make cloud-based threat detection development easier while also consolidating collective findings from real-world deployments. In order to scale the development of high-quality threat detections with minimum false positives, CSA and Cloud Analytics promote an agile development approach for building these analytics, where rules are expected to be continuously tuned and evaluated.We look forward to wider industry collaboration and community contributions (from rules consumers, designers, builders, and testers) to refine existing rules and develop new ones, along with associated adversary emulations in order to raise the bar for minimum self-service security visibility and analytics for everyone.AcknowledgementsWe’d like to thank our industry partners and acknowledge several individuals across both Google Cloud and the Center for Threat-Informed Defense for making this research project possible:- Desiree Beck, Principal Cyber Operations Engineer, MITRE- Michael Butt, Lead Offensive Security Engineer, MITRE- Iman Ghanizada, Head of Autonomic Security Operations, Google Cloud- Anton Chuvakin, Senior Staff, Office of the CISO, Google CloudRelated ArticleIntroducing Community Security AnalyticsIntroducing Community Security Analytics, an open-source repository of queries for self-service security analytics to help you get starte…Read Article
Quelle: Google Cloud Platform

Iteration and innovation fuel the data-driven culture at Mercado Libre. In our first post, we presented our continuous intelligence approach, which leverages BigQuery and Looker to create a data ecosystem on which people can build their own models and processes. Using this framework, the Shipping Operations team was able to build a new solution that provided near real-time data monitoring and analytics for our transportation network and enabled data analysts to create, embed, and deliver valuable insights.The challengeShipping operations are critical to success in e-commerce, and Mercado Libre’s process is very complex since our organization spans multiple countries, time zones, and warehouses, and includes both internal and external carriers. In addition, the onset of the pandemic drove exponential order growth, which increased pressure on our shipping team to deliver more while still meeting the 48-hour delivery timelines that customers have come to expect.This increased demand led to the expansion of fulfillment centers and cross-docking centers, doubling and tripling the nodes of our network (a.k.a. meli-net) in the leading countries where we operate. We also now have the largest electric vehicle fleet in Latin America and operate domestic flights in Brazil and Mexico. We previously worked with data coming in from multiple sources, and we used APIs to bring it into different platforms based on the use case. For real-time data consumption and monitoring, we had Kibana, while historical data for business analysis was piped into Teradata. Consequently, the real-time Kibana data and the historical data in Teradata were growing in parallel, without working together. On one hand, we had the operations team using real-time streams of data for monitoring, while on the other, business analysts were building visualizations based on the historical data in our data warehouse. This approach resulted in a number of problems:The operations team lacked visibility and required support to build their visualizations. Specialized BI teams became bottlenecks.Maintenance was needed, which led to system downtime. Parallel solutions were ungoverned (the ops team used an Elastic database to store and work with attributes and metrics) with unfriendly backups and data bounded for a period of time.We couldn’t relate data entities as we do with SQL. Striking a balance: real-time vs. historical dataWe needed to be able to seamlessly navigate between real-time and historical data. To address this need, we decided to migrate the data to BigQuery, knowing we would leverage many use cases at once with Google Cloud.Once we had our real-time and historical data consolidated within BigQuery, we had the power to make choices about which datasets needed to be made available in near real-time and which didn’t. We evaluated the use of analytics with different time windows tables from the data streams instead of the real-time logs visualization approach. This enabled us to serve near real-time and historical data utilizing the same origin. We then modeled the data using LookML, Looker’s reusable modeling language based on SQL, and consumed the data through Looker dashboards and Explores. Because Looker queries the database directly, our reporting mirrored the near real-time data stored in BigQuery. Finally, in order to balance near real-time availability with overall consumption costs, we analyzed key use cases on a case-by-case basis to optimize our resource usage.This solution prevented us from having to maintain two different tools and featured a more scalable architecture. Thanks to the services of GCP and the use of BigQuery, we were able to design a robust data architecture that ensures the availability of data in near real-time.Streaming data with our own Data Producer Model: from APIs to BigQuery To make new data streams available, we designed a process which we call the “Data Producer Model” (“Modelo Productor de Datos” or MPD) where functional business teams can serve as data creators in charge of generating data streams and publishing them as related information assets we call “data domains”. Using this process, the new data comes in via JSON format, which is streamed into BigQuery. We then use a 3-tiered transformation process to convert that JSON into a partitioned, columnar structure.To make these new data sets available in Looker for exploration, we developed a Java utility app to accelerate the development of LookML and make it even more fun for developers to create pipelines.The end-to-end architecture of our Data Producer Model.The complete “MPD” solution results in different entities being created in BigQuery with minimal manual intervention. Using this process, we have been able to automate the following:The creation of partitioned, columnar tables in BigQuery from JSON samplesThe creation of authorized views in a different GCP BigQuery project (for governance purposes)LookML code generation for Looker viewsJob orchestration in a chosen time windowBy using this code-based incremental approach with LookML, we were able to incorporate techniques that are traditionally used in DevOps for software development, such as using Lams to validate LookML syntax as a part of the CI process and testing all our definitions and data with Spectacles before they hit production. Applying these principles to our data and business intelligence pipelines has strengthened our continuous intelligence ecosystem. Enabling exploration of that data through Looker and empowering users to easily build their own visualizations has helped us to better engage with stakeholders across the business.The new data architecture and processes that we have implemented have enabled us to keep up with the growing and ever-changing data from our continuously expanding shipping operations. We have been able to empower a variety of teams to seamlessly develop solutions and manage third party technologies, ensuring that we always know what’s happening – and more critically – enabling us to react in a timely manner when needed. Outcomes from improving shipping operations:Today, data is being used to support decision-making in key processes, including:Carrier Capacity OptimizationOutbound MonitoringAir Capacity MonitoringThis data-driven approach helps us to better serve you -and everyone- who expects to receive their packages on-time according to our delivery promise. We can proudly say that we have improved both our coverage and speed, delivering 79% of our shipments in less than 48 hours in the first quarter of 2022.Here is a sneak peek into the data assets that we use to support our day-to-day decision making:a. Carrier Capacity: Allows us to monitor the percentage of network capacity utilized across every delivery zone and identify where delivery targets are at risk in almost real time.b. Outbound Places Monitoring: Consolidates the number of shipments that are destined for a place (the physical points where a seller picks up a package), enabling us to both identify places with lower delivery efficiency and drill into the status of individual shipments.c. The Air Capacity Monitoring: Provides capacity usage monitoring for our aircrafts running each of our shipping routes.Costs into the equationThe combination of BigQuery and Looker also showed us something we hadn’t seen before: overall cost and performance of the system. Traditionally, developers maintained focus on metrics like reliability and uptime without factoring in associated costs.By using BigQuery’s information schema, Looker Blocks, and the export of BigQuery logs, we have been able to closely track data consumption, quickly detect underperforming SQL and errors, and make adjustments to optimize our usage and spend. Based on that, we know the Looker Shipping Ops dashboards generate a concurrency of more than 150 queries, which we have been able to optimize by taking advantage of BigQuery and Looker caching policies.The challenges aheadUsing BigQuery and Looker has enabled us to solve numerous data availability and data governance challenges: single point access to near real-time data and to historical information, self-service analytics & exploration for operations and stakeholders across different countries & time zones, horizontal scalability (with no maintenance), and guaranteed reliability and uptime (while accounting for costs), among other benefits.However, in addition to having the right technology stack and processes in place, we also need to enable every user to make decisions using this governed, trusted data. To continue achieving our business goals, we need to democratize access not just to the data but also to the definitions that give the data meaning. This means incorporating our data definitions with our internal data catalog and serving our LookML definitions to other data visualizations tools like Data Studio, Tableau or even Google Sheets and Slides so that users can work with this data through whatever tools they feel most comfortable using.If you would like a more indepth look at how we made new data streams available from a process we designed called the “Data Producer Model” (“Modelo Productor de Datos” or MPD) register to attend our webcast on August 31. While learning and adopting new technologies can be a challenge, we are excited to tackle this next phase, and we expect our users will be too, thanks to a curious and entrepreneurial culture. Are our teams ready to face new changes? Are they able to roll out new processes and designs? We’ll go deep on this in our next post.
Quelle: Google Cloud Platform
Du kannst jetzt bei der Verwendung von AWS Identity and Access Management (IAM) für die Verbindung zu Amazon Neptune eine präzise Zugriffskontrolle für Aktionen auf der Datenebene konfigurieren.
Quelle: aws.amazon.com
Geräte von AWS Snowball Edge (SBE) Storage Optimized unterstützen jetzt die leistungsstarke NFS-Datenübertragung in den Regionen AWS GovCloud (USA). Mit dieser Markteinführung können Kunden von AWS GovCloud (USA) nun bis zu 80 TB an Daten über Datei- oder Objektschnittstellen auf Geräte von Snowball Edge Storage Optimized übertragen. Die Dateischnittstelle stellt einen NFS (Network File System)-Einhängepunkt für jeden Amazon-S3-Bucket auf Ihrem Gerät von AWS Snowball Edge Storage Optimized zur Verfügung. Nachdem Sie die Dateifreigabe aktiviert haben, können Sie Dateien von Ihrem Computer per Drag & Drop in S3-Buckets auf dem Snowball-Edge-Gerät ablegen.
Quelle: aws.amazon.com