Raumfahrt: Russland stellt Konzept für eigene Raumstation vor
Roskosmos hat den Entwurf einer eigenen Raumstation gezeigt, deren Aufbau in der zweiten Hälfte des Jahrzehnts beginnen soll. (Roskosmos, Technologie)
Quelle: Golem

Roskosmos hat den Entwurf einer eigenen Raumstation gezeigt, deren Aufbau in der zweiten Hälfte des Jahrzehnts beginnen soll. (Roskosmos, Technologie)
Quelle: Golem
We’re all looking for ways to grow our audiences for our sites. Sometimes, we change our content to optimize it for search engines (here’s a shameless plug for our new SEO course). Other times, we find ways to reach new people, such as using tags so our blog posts show up in the Reader.
Now, WordPress.com creators are getting access to an all-new tool to increase their audience.
Originally released as Microsoft News, the revamped Microsoft Start is a global news and information feed that currently syndicates content from over 4,500 premium publishers to about a billion people! In an effort to expand and diversify this network, Microsoft has started an exclusive pilot program — and is looking for 500 highly qualified, independent creators in the U.S. to apply.
Yes, this means you.
Using the Microsoft Start plugin to connect your site to the platform, you’ll be able to build your brand and gain exposure by delivering your content throughout Microsoft Start’s ecosystem, which includes MSN, Bing, and Microsoft Edge. Additionally, you’ll be able to earn ad-sharing revenue via the platform, as well as 100% direct support through readers and your affinity links. Creators on the Microsoft Start platform act as their own syndicator and will maintain 100% ownership of their content. Even better, previously published posts can be repurposed as evergreen content using the built-in WordPress.com feed functionality.
Do you qualify?
Desired applicants are reputable topic specialists publishing content at least 5 times per month. Priority will be given to the following genres: food and drink; travel; health and wellness (which includes nutrition and fitness); relationships; parenting; demystifying science and tech; career and personal finance; the craft of writing; and DIY how-tos. Ideally, you also have an archive of at least 25 blog posts.
If you’re interested in applying, Microsoft will sweeten the deal by paying 500 accepted candidates a $100 bonus upon publishing regularly for 60 days. (To qualify, candidates must submit their application by 11:59pm PDT on Sunday August 28, 2022 and enter “WordPress” as your referral.) Please note that there are terms and conditions all participating publishers must agree to in order to work directly with Microsoft Start. This opportunity is not an affiliate program between Microsoft Start and WordPress.com; it’s simply a special, limited-time opportunity we’ve helped to leverage for WordPress.com creators.
Apply Now
Quelle: RedHat Stack

“Ninety percent of all data today was created in the last two years—that’s 2.5 quintillion bytes of data per day,” according to business data analytics company Domo. That would be a mind-bending statistic, except that it’s already five years old. As data usage has undergone drastic expansion and changes in the past five years, so have your business needs for data. Technology such as cloud computing and AI have changed how we use data, derive value from data, and glean insights from data. Your organization is no longer just crunching and re-crunching the same data sets. Data moves, shifts, and replicates, as you mingle data sets and gain new value in the process, as we say in our Data Cloud story. All the while, your data resides in—and is being created in—new places.Data lives in a myriad of locations now and requires access from different locations and mediums, yet many of today’s security models are not geared towards this. In short, your data has fallen out of love with your security model, but attackers have not. So, how do we realign data and security so they are once again in a healthy relationship?Google Cloud, as a leader in cloud data management and cloud security, is positioned uniquely to define and lead this effort. We’ve identified some challenges around the classic approach to data security and the changes triggered by the near-ubiquity of the cloud. The case is compelling for adopting a modern approach to data security. We contend that the optimal way forward is with autonomic data security. A relatively new concept, autonomic data security is security that’s been integrated with data throughout its lifecycle. It can make things easier on users by freeing them from defining and redefining myriad rules about who can do what, when, where. It’s an approach that keeps pace with constantly evolving cyberthreats and business changes. Autonomic data security can help you keep your IT assets more secure and can make your business and IT processes speedier. For example, data sharing with partners and data access decisions simultaneously becomes faster and more secure. This may sound like magic, but in fact relies on a constant willingness to change and adapt to both business changes and threat evolution.Taking the precepts, concepts, and forward-looking solutions presented in this paper into consideration, we strongly believe that now is the right time to assess where you and your business are when it comes to data security. Cloud also brings an incredible scale of computing. Where gigabytes once roamed, petabytes are now common. This means that many data security approaches, especially the manual ones, are no longer practical. To prepare for the future of data security, we recommend you challenge your current model and assumptions and ask critical questions, evaluate where you are, and then start to put a plan in place of how you could start incorporating the autonomic data security pillars into your data security model.There are two sets of questions organizations need to discover the answers to as they start this journey. The first set of questions will help you identify the nature and status of your data, and inform the answers to the second set.What data do I have?Who owns it?Is it sensitive?How is it used?What is the value in storing the data?The second set focuses on higher-level problems:What is my current approach to data security? Where does it fail to support the business and counter the threats?Does it support my business? Should I consider making a change? And if yes, in what direction?The path to improved data security starts by asking the right questions. You can read the full Autonomic Data Security paper for a more in-depth exploration here and learn more about the idea in this podcast episode.Related Article[Infographic] Achieving Autonomic Security Operations: Why metrics matter (but not how you think)Metrics can be a vital asset – or a terrible failure – for keeping organizations safe. Follow these tips to ensure security teams are tra…Read Article
Quelle: Google Cloud Platform
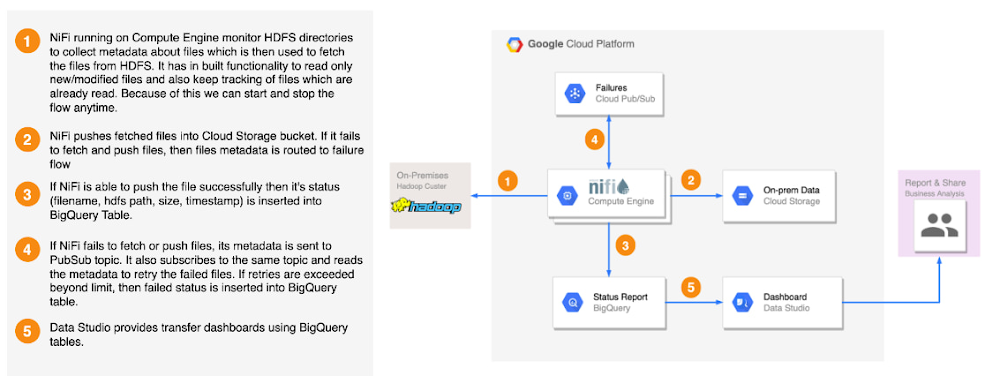
Are you looking to migrate a large amount of Hive ACID tables to BigQuery? ACID enabled Hive tables support transactions that accept updates and delete DML operations. In this blog, we will explore migrating Hive ACID tables to BigQuery. The approach explored in this blog works for both compacted (major / minor) and non-compacted Hive tables. Let’s first understand the term ACID and how it works in Hive.ACID stands for four traits of database transactions: Atomicity (an operation either succeeds completely or fails, it does not leave partial data)Consistency (once an application performs an operation the results of that operation are visible to it in every subsequent operation)Isolation (an incomplete operation by one user does not cause unexpected side effects for other users)Durability (once an operation is complete it will be preserved even in the face of machine or system failure)Starting in Version 0.14, Hive supports all ACID properties which enables it to use transactions, create transactional tables, and run queries like Insert, Update, and Delete on tables.Underlying the Hive ACID table, files are in the ORC ACID version. To support ACID features, Hive stores table data in a set of base files and all the insert, update, and delete operation data in delta files. At the read time, the reader merges both the base file and delta files to present the latest data. As operations modify the table, a lot of delta files are created and need to be compacted to maintain adequate performance. There are two types of compactions, minor and major.Minor compaction takes a set of existing delta files and rewrites them to a single delta file per bucket.Major compaction takes one or more delta files and the base file for the bucket and rewrites them into a new base file per bucket. Major compaction is more expensive but is more effective.Organizations configure automatic compactions, but they also need to perform manual compactions when automated fails. If compaction is not performed for a long time after a failure, it results in a lot of small delta files. Running compaction on these large numbers of small delta files can become a very resource intensive operation and can run into failures as well. Some of the issues with Hive ACID tables are:NameNode capacity problems due to small delta files.Table Locks during compaction.Running major compactions on Hive ACID tables is a resource intensive operation.Longer time taken for data replication to DR due to small files.Benefits of migrating Hive ACIDs to BigQuerySome of the benefits of migrating Hive ACID tables to BigQuery are:Once data is loaded into managed BigQuery tables, BigQuery manages and optimizes the data stored in the internal storage and handles compaction. So there will not be any small file issue like we have in Hive ACID tables.The locking issue is resolved here as BigQuery storage read API is gRPC based and is highly parallelized. As ORC files are completely self-describing, there is no dependency on Hive Metastore DDL. BigQuery has an in-built schema inference feature that can infer the schema from an ORC file and supports schema evolution without any need for tools like Apache Spark to perform schema inference. Hive ACID table structure and sample dataHere is the sample Hive ACID table “employee_trans” Schemacode_block[StructValue([(u’code’, u”hive> show create table employee_trans;rnOKrnCREATE TABLE `employee_trans`(rn `id` int, rn `name` string, rn `age` int, rn `gender` string)rnROW FORMAT SERDE rn ‘org.apache.hadoop.hive.ql.io.orc.OrcSerde’ rnSTORED AS INPUTFORMAT rn ‘org.apache.hadoop.hive.ql.io.orc.OrcInputFormat’ rnOUTPUTFORMAT rn ‘org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat’rnLOCATIONrn ‘hdfs://hive-cluster-m/user/hive/warehouse/aciddb.db/employee_trans’rnTBLPROPERTIES (rn ‘bucketing_version’=’2′, rn ‘transactional’=’true’, rn ‘transactional_properties’=’default’, rn ‘transient_lastDdlTime’=’1657906607′)”), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3eda26dc94d0>)])]This sample ACID table “employee_trans” has 3 records.code_block[StructValue([(u’code’, u’hive> select * from employee_trans;rnOKrn1 James 30 Mrn3 Jeff 45 Mrn2 Ann 40 FrnTime taken: 0.1 seconds, Fetched: 3 row(s)’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3eda26dc9310>)])]For every insert, update and delete operation, small delta files are created. This is the underlying directory structure of the Hive ACID enabled table.code_block[StructValue([(u’code’, u’hdfs://hive-cluster-m/user/hive/warehouse/aciddb.db/employee_trans/delete_delta_0000005_0000005_0000rnhdfs://hive-cluster-m/user/hive/warehouse/aciddb.db/employee_trans/delete_delta_0000006_0000006_0000rnhdfs://hive-cluster-m/user/hive/warehouse/aciddb.db/employee_trans/delta_0000001_0000001_0000rnhdfs://hive-cluster-m/user/hive/warehouse/aciddb.db/employee_trans/delta_0000002_0000002_0000rnhdfs://hive-cluster-m/user/hive/warehouse/aciddb.db/employee_trans/delta_0000003_0000003_0000rnhdfs://hive-cluster-m/user/hive/warehouse/aciddb.db/employee_trans/delta_0000004_0000004_0000rnhdfs://hive-cluster-m/user/hive/warehouse/aciddb.db/employee_trans/delta_0000005_0000005_0000′), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3eda26a28c50>)])]These ORC files in an ACID table are extended with several columns:code_block[StructValue([(u’code’, u’struct<rn operation: int,rn originalTransaction: bigInt,rn bucket: int,rn rowId: bigInt,rn currentTransaction: bigInt,rn row: struct<…>rn>’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3eda26a28810>)])]Steps to Migrate Hive ACID tables to BigQueryMigrate underlying Hive table HDFS dataCopy the files present under employee_trans hdfs directory and stage in GCS. You can use either HDFS2GCS solution or Distcp. HDFS2GCS solution uses open source technologies to transfer data and provide several benefits like status reporting, error handling, fault tolerance, incremental/delta loading, rate throttling, start/stop, checksum validation, byte2byte comparison etc. Here is the high level architecture of the HDFS2GCS solution. Please refer to the public github URL HDFS2GCS to learn more about this tool.The source location may contain extra files that we don’t necessarily want to copy. Here, we can use filters based on regular expressions to do things such as copying files with the .ORC extension only.Load ACID Tables as-is to BigQueryOnce the underlying Hive acid table files are copied to GCS, use the BQ load tool to load data in BigQuery base table. This base table will have all the change events.Data verificationRun “select *” on the base table to verify if all the changes are captured. Note: Use of “select * …” is used for demonstration purposes and is not a stated best practice.Loading to target BigQuery tableThe following query will select only the latest version of all records from the base table, by discarding the intermediate delete and update operations.You can either load the results of this query into a target table using scheduled query on-demand with the overwrite option or alternatively, you can also create this query as a view on the base table to get the latest records from the base table directly.code_block[StructValue([(u’code’, u’WITHrn latest_records_desc AS (rn SELECTrn Row.*,rn operation,rn ROW_NUMBER() OVER (PARTITION BY originalTransaction ORDER BY originalTransaction ASC, bucket ASC, rowId ASC, currentTransaction DESC) AS rownumrn FROMrn `hiveacid-sandbox.hivetobq.basetable` )rnSELECT id,name,age,genderrnFROMrn latest_records_descrnWHERErn rownum=1rn AND operation != 2′), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3eda2680bc90>)])]Once the data is loaded in target BigQuey table, you can perform validation using below steps:a. Use the Data Validation Tool to validate the Hive ACID table and the target BigQuery table. DVT provides an automated and repeatable solution to perform schema and validation tasks. This tool supports the following validations:Column validation (count, sum, avg, min, max, group by)Row validation (BQ, Hive, and Teradata only)Schema validationCustom Query validationAd hoc SQL explorationb. If you have analytical HiveQLs running on this ACID table, translate them using the BigQuery SQL translation service and point to the target BigQuery table. Hive DDL Migration (Optional)Since ORC is self-contained, leverage BigQuery’s schema inference feature when loading. There is no dependency to extract Hive DDLs from Metastore. But if you have an organization-wide policy to pre-create datasets and tables before migration, this step will be useful and will be a good starting point. a. Extract Hive ACID DDL dumps and translate them using BigQuery translation service to create equivalent BigQuery DDLs. There is a Batch SQL translation service to bulk translate exported HQL (Hive Query Language) scripts from a source metadata bucket in Google Cloud Storage to BigQuery equivalent SQLs into a target GCS bucket. You can also use BigQuery interactive SQL translator which is a live, real time SQL translation tool across multiple SQL dialects to translate a query like HQL dialect into a BigQuery Standard SQL query. This tool can reduce time and effort to migrate SQL workloads to BigQuery. b. Create managed BigQuery tables using the translated DDLs. Here is the screenshot of the translation service in the BigQuery console. Submit “Translate” to translate the HiveQLs and “Run” to execute the query. For creating tables from batch translated bulk sql queries, you can use Airflow BigQuery operator (BigQueryInsertJobOperator) to run multiple queriesAfter the DDLs are converted, copy the ORC files to GCS and perform ELT in BigQuery. The pain points of Hive ACID tables are resolved when migrating to BigQuery. When you migrate the ACID tables to BigQuery, you can leverage BigQuery ML and GeoViz capabilities for real-time analytics. If you are interested in exploring more, please check out the additional resources section. Additional ResourcesHive ACIDACID ORC FormatHDFS2GCS SolutionDistCpData Validation ToolBigQuery Translation ServiceRelated ArticleScheduling a command in GCP using Cloud Run and Cloud SchedulerHow to efficiently and quickly schedule commands like Gsutil using Cloud Run and Cloud Scheduler.Read Article
Quelle: Google Cloud Platform

Many IT organizations must choose between giving developers the flexibility they need to be productive and keeping developer workstations managed and secure. Supply chain challenges have led to developers waiting weeks or months to get the hardware they need, forcing them to use aging hardware or unsecured personal devices. At the same time, hybrid work has forced IT to open access to corporate and on-premises resources to developers around the world. With access to sensitive source code and customer data, developers are increasingly becoming the target of more sophisticated cyberattacks.
Today, we’re excited to announce the preview of Microsoft Dev Box is now available to the public. Microsoft Dev Box is a managed service that enables developers to create on-demand, high-performance, secure, ready-to-code, project-specific workstations in the cloud. Sign in to the Azure portal and search for “dev box” to begin creating dev boxes for your organization.
Focus on code—not infrastructure
With Microsoft Dev Box, developers can focus on writing the code only they can write instead of trying to get a working environment that can build and run the code. Dev boxes are ready-to-code and preconfigured by the team with all the tools and settings developers need for their projects and tasks. Developers can create their own dev boxes whenever they need to quickly switch between projects, experiment on a proof-of-concept, or kick off a full build in the background while they move on to the next task.
Microsoft Dev Box supports any developer IDE, SDK, or tool that runs on Windows. Developers can target any development workload that can be built from Windows including desktop, mobile, IoT, and web applications. Microsoft Dev Box even supports building cross-platform apps thanks to Windows Subsystem for Linux and Windows Subsystem for Android. Remote access gives developers the flexibility to securely access dev boxes from any device, whether it’s Windows, MacOS, Android, iOS, or a web browser.
Tailor dev boxes to the needs of the team
With Microsoft Dev Box, developer teams create and maintain dev box images with all the tools and dependencies their developers need to build and run their applications. Developer leads can instantly deploy the right size dev box for specific roles in a team anywhere in the world, selecting from 4 vCPU / 16GB to 32 vCPU / 128GB SKUs to scale to any size application. By deploying dev boxes in the closest Azure region and connecting via the Azure Global Network, dev teams ensure a smooth and responsive experience with gigabit connection speeds for developers around the world.
Using Azure Active Directory groups, IT admins can grant access to sensitive source code and customer data for each project. With role-based permissions and custom network configurations, developer leads can give vendors limited access to the resources they need to contribute to the project—eliminating the need to ship hardware to short-term contractors and helping keep development more secure.
Centralize governance and management
Developer flexibility and productivity can’t come at the expense of security or compliance. Microsoft Dev Box builds on Windows 365, making it easy for IT administrators to manage dev boxes together with physical devices and Cloud PCs through Microsoft Intune and Microsoft Endpoint Manager. IT admins can set conditional access policies to ensure users only access dev boxes from compliant devices while keeping dev boxes up to date using expedited quality updates to deploy zero-day patches across the organization and quickly isolate compromised devices. Endpoint Manager’s deep device analytics make it easy to audit application health, device utilization, and other critical metrics, giving developers the confidence to focus on their code knowing they’re not exposing the organization to any unnecessary risk.
Microsoft Dev Box uses a consumption-based compute and storage pricing model, meaning organizations only pay for what they use. Automated schedules can warm up dev boxes at the start of the day and stop them at the end of the day while they sit idle. With hibernation, available in a few weeks, developers can resume a stopped dev box and pick up right where they left off.
Get started now
Microsoft Dev Box is available today as a preview from the Azure Portal. During this period, organizations get the first 15 hours of the dev box 8vCPU and 32 GB Memory SKU for free every month, along with the first 365 hours of the dev box Storage SSD 512 GB SKU. Beyond that, organizations pay only for what they use with a consumption-based pricing model. With this model, organizations are charged on a per-hour basis depending on the number of Compute and Storage that are consumed.
To learn more about Microsoft Dev Box and get started with the service, visit the Microsoft Dev Box page or find out how to deploy your own Dev Box from a pool.
Quelle: Azure

Das Gaming-System von Aldi kombiniert acht Alder-Lake-Kerne mit einer Ampere-Grafikkarte und 32 GByte RAM, dazu ein Inwin-Gehäuse. (Aldi-PC, Intel)
Quelle: Golem

Ein Forscher hat im Dezember 2021 eine Lücke an Zoom gemeldet. Acht Monate später ist das Problem nicht behoben. Jetzt hat er sie veröffentlicht. (Zoom, Mac)
Quelle: Golem

Endlich hat 1&1 Mobilfunk eine erste 5G-Mobilfunkstation errichtet und einen Friendly User Test durchgeführt. Doch es gab nur Fixed Wireless Access. (United Internet, NEC)
Quelle: Golem

Android 13 bringt unter anderem Verbesserungen bei der Sicherheit, der Personalisierung und der Medienausgabe. (Android 13, Smartphone)
Quelle: Golem

Während Sony weit über 100 Millionen der PS4-Konsolen verkauft hat, erreichte Microsoft nicht einmal halb so viele Xbox-One-Geräte. (Xbox One, Microsoft)
Quelle: Golem