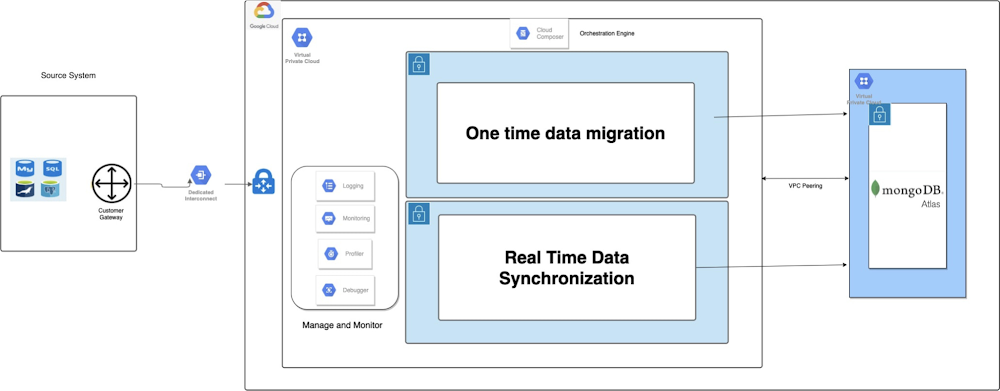
What does modernization mean?As an IT leader or architect, you may notice that your software architecture is encountering performance issues. You may be considering moving your datastore from a mainframe or a traditional relational database (RDBMS) to a more modern database to take advantage of advanced analytics, scale at a faster rate, and opportunities to cut costs. Such is the impetus for modernization.An approach to modernization can be defined as, “An open, cross-functional collaboration dedicated to building new design systems and patterns that support evolving computing capabilities, information formats, and user needs.”Within the same spirit of modernization we can say that MongoDB works along with Google Cloud technologies to provide joint solutions and some reference architectures to help our customers leverage this partnership.Principles of modern technology solutionsA point of view to Modernization is understood through four basic principles that focus on outcomes for our customers. These principles can be applied to envision what a modern solution should achieve or to identify whether a given solution is modern or not.Help users get more done. Bring quality information forward and make it actionable in context. Actions are the new blue links.Feed curiosity. Open doorways to rich, endless discovery. Remove dead ends for users who want to engage more.Reflect the world, in real time. Surface fresh, dynamic content. Help users be in the know.Be personal, then personalize. Encourage the user’s personal touch to surface personal content and personalized experiences. Be stateful and contextual.Modern applications should be capable of presenting information in a way that enables users to not only make decisions, but also transform those decisions into actions. This requires the use of variable data formats and integration mechanisms that will allow the end user to interact with various systems and produce real-time results, without the need to log in to each one of them.MongoDB Atlas, a modern database management systemIf we are to use the four principles of modernization as a reference to identify modern solutions, then MongoDB Atlas reflects these directly. Altas helps database and infrastructure administrators get more done faster and with less effort than managing MongoDB on premises. It is a fully managed database service that takes care of the most critical and time-consuming tasks related to providing a continuous and reliable service, including security and compliance features out of the box, freeing administrators’ and developers’ time to focus on innovation.The third principle talks about reflecting the world in real time. This is the most cumbersome and daunting task for anybody who is responsible for the design of a modern technology system, since it requires an architecture capable of receiving, processing, storing, and producing results from data streams originated by different systems, at different velocity rates, and in different formats. Atlas frees the solution architect from this burden. As a managed service, it takes care of the networking, processing, and storage resources allocation, so it will scale as needed, when needed. And as a document-based database, it also allows for flexibility in regards to the format and organization of incoming data, Developers can focus on the actual process rather than spend their time modeling the information to make it fit into the RDBMS, as so often happens with traditional relational database schemas. It also provides real-time data processing features that allow for the execution of code or the consumption of external APIs residing in separate applications or even in various clouds.Of course, the combination of the first three principles leads to the fourth, which is to personalize the experience to the end user. Businesses must be able to solve specific user needs, rather than limit their processes solely to what their database or application is capable of. Putting the user first invariably leads to a better and modern experience—and that starts with choosing the best cloud provider and a database that aligns with these principles.A reference architecture for data modernizationLet’s dive into a general view of the migration reference architecture that enables the four aforementioned principles.An Operational Data Layer (or ODL) is an architectural pattern that centrally integrates and organizes siloed enterprise data, making it available to consuming applications. It enables a range of board-level strategic initiatives such as Legacy Modernization and Data as a Service, and use cases such as single view, real-time analytics and mainframe offload.An Operational Data Layer is an intermediary between existing data sources and consumers that need to access that data. An ODL deployed in front of legacy systems can enable new business initiatives and meet new requirements that the existing architecture can’t handle— without the difficulty and risk of a full rip and replace of legacy systems.For an initial migration that will keep the current architecture in place while replicating records that are produced over the production system, the following reference shows some components that can be taken into account to achieve a starting point in time backup and restore on MongoDB Atlas, while at the same time enabling real time synchronization.Figure 1. One-time data migration and real-time data syncThe above solution architecture shows both general views for one-time data migration and real-time data synchronization using Google Cloud technologies. A one-time data migration involves initial bulk ETL of data from the source relational database to MongoDB. Google Cloud Data Fusion can be used along with Apache Sqoop or Spark SQL’s JDBC connector powered by Dataproc to extract data from the source and store it in Google Cloud Storage temporarily. Custom Spark jobs powered by Dataproc are deployed to transform the data and load into MongoDB Atlas. MongoDB has a native spark connector which will allow storing Spark DataFrame as collections.Figure 2. One-time data migrationIn most of the migrations, the source database will not be retired for a few weeks to months. In such cases, MongoDB Atlas needs to be up to date with the source database. We can use Change Data Capture (CDC) tools like Google Cloud Datastream or Debezium on Dataflow to capture the changes, which can then be pushed to message queues like Google Cloud Pub/Sub. We can write custom transformation jobs using Apache beam powered by Dataflow, Java, or Python, which can consume the data from the message queue, transform it, and push it to MongoDB Atlas using native drivers. Google Cloud Composer will help orchestrate all the workflows.Figure 3. Real-time data synchronizationCommon use cases for MongoDBBelow are some observed common patterns of MongoDB. (For a more general treatment of more patterns please check out the MongoDB use case page.)Monolith to microservice – With its flexible schema and capabilities for redundancy, automation, and scalability, MongoDB (and MongoDB Atlas, its managed services version) is very well suited for microservices architecture. Together, MongoDB Atlas and microservices on Google Cloud can help organizations better align teams, innovate faster, and meet today’s demanding development and delivery requirements with full sharding across regions and globally.Legacy modernization – Relationship databases impose a tax on a business—a Data and Innovation Recurring Tax (DIRT). By modernizing with MongoDB, you can build new business functionality 3-5x faster, scale to millions of users wherever they are on the planet, and cut costs by 70% and more—all by unshackling yourself from legacy systems and, at the same time, taking advantage of the Google Cloud ecosystem. Mainframe offload – MongoDB can help offload key applications from the mainframe to a modern data platform without impacting your core systems, and help achieve agility while also reducing costs.Real-time analytics – MongoDB makes it easy to scale to the needs of real-time analytics with Atlas on Google Cloud; coupled with Google cloud analytics, such as BigQuery, the sky’s the limit.Mobile application development- MongoDB Realm helps companies build better apps faster with edge-to-cloud sync and fully managed backend services, including triggers, functions, and GraphQL.Other reference architecturesBelow are some reference architectures that can be applied to particular requirements. For more information, visit:MongoDB Use CasesGoogle Cloud Architecture CenterAn Operational Data Warehouse requires swift response times to keep data updated to the most recent state possible, with the final goal to produce near-real-time analytics. It also has to be scalable, robust, and secure to adapt to the highest standards and be compliant with various regulations.Figure 4. Operationalized Data Warehouse (ODS + EDW)The above referenced architecture describes which Google Cloud components can be combined to ingest data from any source into an ODS supported by MongoDB Atlas and how to integrate this ODS with an Enterprise Data Warehouse (BigQuery) that enables structured data for analytical tools like Looker.Shopping Cart AnalysisFigure 5 illustrates an implementation example of the Operationalized Data Warehouse reference architecture shown previously. In this scenario, several data sources (including shopping cart information) are replicated in real time to MongoDB through the Spark Connector. Information is then processed using Dataflow as a graphical interface to generate data processing jobs that are executed over an ephemeral, managed Hadoop & Spark cluster (Dataproc). Finally, processed data can be structured and stored for fast querying in BigQuery, supporting Shopping Cart, Product Browsing, and Outreach applications.Figure 5. Shopping cart analysisRecommendation EnginesFigure 6 presents a continuation of the idea presented in the last example. Now the objective is to use MongoDB Atlas as an Operational Data Warehouse that combines structured and semistructured data (SQL and noSQL data) in real time. This works as a centralized repository that enables machine learning tools such as Spark Mlib running on Dataproc, Cloud Machine Learning (now Vertex AI), and Prediction API to analyze data and produce personalized recommendations for customers visiting an online store in real time.Data from various systems can be ingested as-is and stored and indexed in JSON format in MongoDB. Dataproc would then use MongoDB Apache Spark Connector to perform the analysis. The insight would be stored in BigQuery and distributed to applications downstream.Learn more about MongoDB and Google Cloud at cloud.google.com/mongodbRelated ArticleLooker lets you choose what works best for your dataEmbrace platform freedom with Looker. Learn about how we are expanding our features as a cloud platform to meet the unique needs of every…Read Article
Quelle: Google Cloud Platform