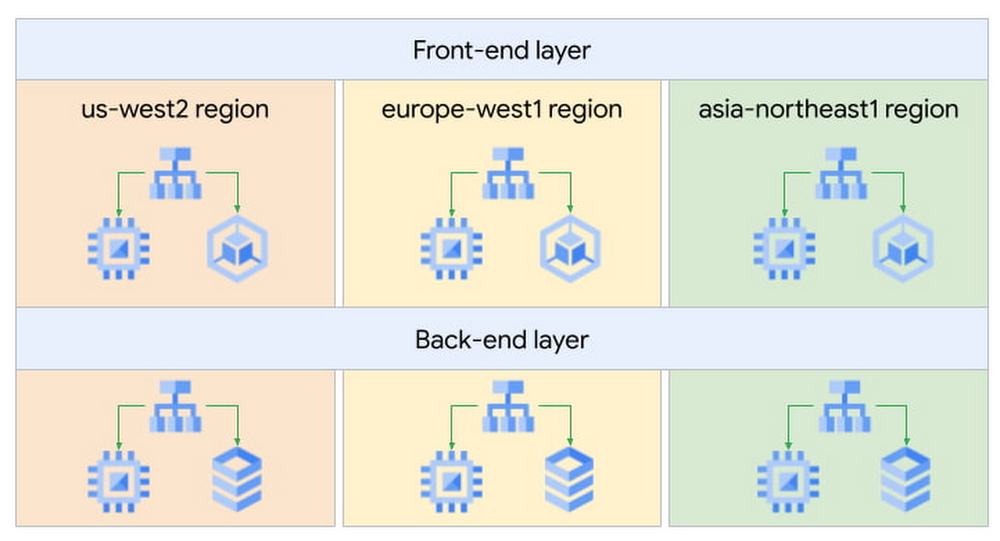
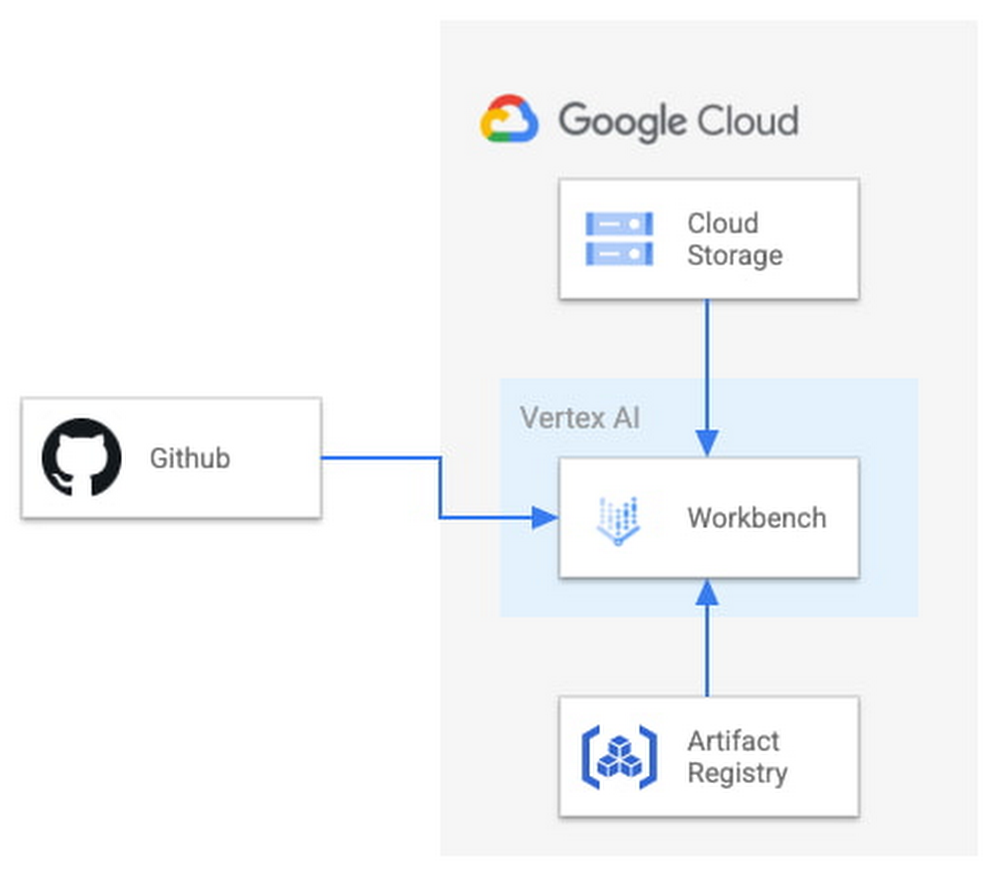
In an industry as highly regulated as healthcare, building a single secure and compliant application that tracks patient care and appointments at a clinic requires a great deal of planning from development and security teams. So, imagine what it would be like to build a solution that includes almost everything related to a patient’s healthcare, including insurance and billing. That’s what Highmark Health (Highmark)—a U.S. health and wellness organization that provides millions of customers with health insurance plans, a physician and hospital network, and a diverse portfolio of businesses–decided to do. Highmark is developing a solution called Living Health to re-imagine healthcare delivery, and it is using Google Cloud and the Google Cloud Professional Services Organization (PSO) to build and maintain the innovation platform supporting this forward thinking experience. Considering all the personal information that different parties like insurers, specialists, billers and coders, clinics, and hospitals share, Highmark must build security and compliance into every part of the solution. In this blog, we look at how Highmark Health and Google are using a technique called “secure-by-design” to address the security, privacy, and compliance aspects of bringing Living Health to life.Secure-by-design: Preventive care for developmentIn healthcare, preventing an illness or condition is the ideal outcome. Preventive care often involves early intervention—a course of ideas and actions to ward off illness, permanent injury, and so on. Interestingly, when developing a groundbreaking delivery model like Living Health, it’s a good idea to take the same approach to security, privacy, and compliance. That’s why Highmark’s security and technology teams worked with their Google Cloud PSO team to implement secure-by-design for every step of design, development, and operations. Security is built into the entire development process rather than waiting until after implementation to reactively secure the platform or remediate security gaps. It’s analogous to choosing the right brakes for a car before it rolls off the assembly line instead of having an inspector shut down production because the car failed its safety tests. The key aspect of secure-by-design is an underlying application architecture created from foundational building blocks that sit on top of a secure cloud infrastructure. Secure-by-design works to ensure that these building blocks are secure and compliant before moving on to development.The entire approach requires security, development, and cloud teams to work together with other stakeholders. Most importantly, it requires a cloud partner, cloud services, and a cloud infrastructure that can support it. Finding the right cloud and services for secure-by-design Highmark chose Google Cloud because of its leadership in analytics, infrastructure services, and platform as a service. In addition, Google Cloud has made strategic investments in healthcare interoperability and innovation, which was another key reason Highmark decided to work with Google. As a result, Highmark felt that Google Cloud and the Google Cloud PSO were best suited for delivering on the vision of Living Health—its security and its outcomes. “Google takes security more seriously than the other providers we considered, which is very important to an organization like us. Cloud applications and infrastructure for healthcare must be secure and compliant,” explains Highmark Vice President and Chief Information Security Officer, Omar Khawaja. Forming a foundation for security and complianceHow does security-by-design with services work? It starts with the creation and securing of the foundational platform, allowing teams to harden and enforce specified security controls. It’s a collaborative process that starts with input from cross-functional teams—not just technology teams—using terms they understand, so that everyone has a stake in the design. A strong data governance and protection program classifies and segments workloads based on risk and sensitivity. Teams build multiple layers of defense into the foundational layers to mitigate against key industry risks. Google managed services such as VPC Service Controls help prevent unauthorized access. Automated controls such as those in Data Loss Prevention help teams quickly classify data and identify and respond to potential sources of data risk. Automation capabilities help ensure that security policies are enforced.After the foundational work is done, it’s time to assess and apply security controls to the different building blocks, which are Google Cloud services such as Google Kubernetes Engine, Google Compute Engine, and Google Cloud Storage. The goal is to make sure that these and similar building blocks, or any combination of them, do not introduce additional risks and to ensure any identified risks are remediated or mitigated. Enabling use cases, step by stepAfter the foundational security is established, the security-by-design program enables the Google Cloud services that developers then use to build use cases that form Living Health. The service enablement approach allows Highmark to address complexity by providing the controls most relevant for each individual service. For each service, the teams begin by determining the risks and the controls that can reduce them. The next step is enforcing preventive and detective controls across various tools. After validation, technical teams can be granted an authorization to operate, also called an ATO. An ATO authorizes the service for development in a use case.For use cases with greater data sensitivity, the Highmark teams validate the recommended security controls with an external trust assessor, who uses the HITRUST Common Security Framework, which maps to certifications and compliance such as HIPAA, NIST, GDPR, and more. A certification process follows that can take anywhere from a few weeks to a few months. In addition to certification, there is ongoing monitoring of the environment for events, behavior, control effectiveness, and control lapses or any deviation from the controls.The approach simplifies compliance for developers by abstracting compliance requirements away. The process provides developers a set of security requirements written in the language of the cloud, rather than in the language of compliance, providing more prescriptive guidance as they build solutions. Through the secure-by-design program, the Highmark technology and security teams, Google, the business, and the third-party trust assessor all contribute to a secure foundation for any architectural design with enabled Google Cloud services as building blocks. Beating the learning curve Thanks to the Living Health project, the Highmark technology and security teams are trying new methods. They are exploring new tools for building secure applications in the cloud. They are paying close attention to processes and the use case steps and, when necessary, aligning different teams to execute. Because everyone is working together collaboratively toward a shared goal, teams are delivering more things on time and with predictability, which has reduced volatility and surprises. The secrets to success: Bringing everyone to the table early and with humilityTogether, Highmark and Google Cloud PSO have created over 24 secure-by-design building blocks by bringing everyone to the table early and relying on thoughtful, honest communication. Input for the architecture design produced for Highmark came from privacy teams, legal teams, security teams, and the teams that are building the applications. And that degree of collaboration ultimately leads to a much better product because everyone has a shared sense of responsibility and ownership of what was built. Delivering a highly complex solution like Living Health takes significant, more purposeful communication and execution. It is also important to be honest and humble. The security, technology, and Google teams have learned to admit when something isn’t working and to ask for help or ideas for a solution. The teams are also able to accept that they don’t have all the answers, and that they need to figure out solutions by experimenting. Khawaja puts it simply, “That level of humility has been really important and enabled us to have the successes that we’ve had. And hopefully that’ll be something that we continue to retain in our DNA.”
Quelle: Google Cloud Platform