DSGVO: Noyb geht gegen rechtswidrige Cookie-Banner vor
Trotz Warnung blieben viele Firmen bei ihren rechtswidrigen Cookie-Bannern. Die Datenschutzorganisation Noyb hat über 400 Beschwerden eingereicht. (Cookies, Datenschutz)
Quelle: Golem

Trotz Warnung blieben viele Firmen bei ihren rechtswidrigen Cookie-Bannern. Die Datenschutzorganisation Noyb hat über 400 Beschwerden eingereicht. (Cookies, Datenschutz)
Quelle: Golem
As organizations think about IT modernization, they also have to consider the impact of new processes and technology on their partners, vendors, and customers. This month, we’ll highlight success stories from organizations in banking and telecommunications—dynamic industries that are facing rapidly changing customer demands. Let’s see how Banco Original and HKT built efficient, flexible IT foundations with Red Hat to better meet customer and market needs.
Quelle: CloudForms

Since the start of the COVID-19 pandemic, there’s been a rapid acceleration of digital transformation across the entire healthcare industry. Telehealth has become a more mainstream and safe way for patients and caregivers to connect. Machine learning modeling has helped speed up innovation and drug discovery. And new levels of integration and data portability have helped enable greater vaccine availability and equitable access to those who need it.Data has been at the crux of this digital transformation — helping people stay healthy, accelerating life sciences research and delivering more personalized and equitable care. We recently unveiled partial results from our research with The Harris Poll, which revealed that nearly all physicians (95%) believe increased data interoperability will ultimately help improve patient outcomes. Today, we’re unveiling the second part of that research. In February 2020, we commissioned The Harris Poll to survey 300 physicians in the U.S. about their biggest pain points — this was just before the COVID-19 pandemic strained the entire healthcare system and made us all hyper-aware of the risks we take in going to the hospital. In June 2021, we followed-up with those same questions and more. What it unveiled was just how much COVID-19 reshaped technology’s role in the healthcare field and how it’s changing day-to-day operations for physicians. Here are some of the highlights: Healthcare organizations accelerated technological upgrades over the course of the pandemic. After a year shaped primarily by the COVID-19 pandemic, use of telehealth saw substantial YOY growth, jumping nearly threefold from 32% in February 2020 to 90% this year. Forty-five percent of physicians say the COVID-19 pandemic accelerated the pace of their organization’s adoption of technology. In fact, more than 3 in 5 physicians (62%) say the pandemic has forced their healthcare organization to make technology upgrades that normally would have taken years. For example, 48% of physicians would like to have access to telehealth capabilities in the next five years. Before the COVID-19 pandemic, about half of physicians (53%) say their healthcare organization’s approach to the adoption of technology would best be described as “neutral” (i.e., willing to try new technologies only if they have been in the market for awhile or others have tried and recommended them). Despite the technological leaps this year, most physicians still believe the industry lags behind in technology adoption but recognize the opportunity for technological support and advancement. The majority of physicians don’t view the healthcare industry as a leader when it comes to digital adoption. More than half of physicians describe the healthcare industry as lagging behind the gaming (64%), telecommunications (56%), and financial services industries (53%). However, the healthcare industry is not seen to be trailing as much as it was last year behind retail (54% in 2020; 44% in 2021); hospitality and travel (53% in 2020; 43% in 2021); and the public sector (39% in 2020; 26% in 2021). Better interoperability alleviates physician burnout, improves health outcomes and speeds up diagnoses. The majority of physicians say increased data interoperability will cut the time to diagnosis for patients significantly (86%) and will ultimately help improve patient outcomes (95%.) In addition to better patient experiences and outcomes, more than half of physicians (54%) believe increased access to data via technology has had a positive impact on their healthcare organization overall. A majority believe that technology can alleviate the likelihood of physician “burn-out” (57%) and that efficient tools help decrease friction and stress (84%). And, as a result, 6 in 10 physicians say access to better technology and clinical data systems would allow them to have better work/life balance (60%) and that better access to/more complete patient data would reduce administrative burdens (61%). It is therefore not surprising that nearly 9 in 10 physicians (89%) say they are increasingly looking for ways to bring together all patient data into a single place for a more complete view of health. Familiarity with new Department of Health and Human Services (DHHS) interoperability rules grows, and many physicians are in favor. Most physicians (74%) say they have at least heard of the new DHHS rules (launched in 2019) to improve the interoperability of electronic health information. This is a clear rise from 2020 (64%), but deeper knowledge is fairly low. Only 30% of physicians say they are somewhat or very familiar with the new rules (though, again, this is a rise from 2020, when only 18% said they were very/somewhat familiar). Similar to in 2020, among those who have heard of the new rules, nearly half are in favor (48% in 2021; 45% in 2020) but a similar proportion remain unsure (46% in 2021; 50% in 2020). And like in 2020, by far the top potential benefit of the rules is thought to be forcing EHRs to be more interoperable with other systems (70%).Google was founded on the idea that bringing more information to more people improves lives on a vast scale. In healthcare, that means creating tools and solutions that make data available in real time to help streamline operations and improve quality of care and patient outcomes. For example, our recently announced Healthcare Data Engine makes it easier for healthcare and life sciences leaders to make smart real-time decisions through clinical, operational, & groundbreaking scientific insights. To find out more about the Healthcare Data Engine, click here.Survey methodology: The 2021 survey was conducted online within the United States by The Harris Poll on behalf of Google Cloud from June 9 – 29, 2021 among 303 physicians who specialize in Family Practice, General Practice, or Internal Medicine, who treat patients, and are duly licensed in the state they practice. The 2020 survey was conducted from February 18 – 25, 2020 among 300 physicians who specialize in Family Practice, General Practice, or Internal Medicine, who treat patients, and are duly licensed in the state they practice. Physicians practicing in Vermont were excluded from the research. This online survey is not based on a probability sample and therefore no estimate of theoretical sampling error can be calculated. For complete survey methodology, including weighting variables and subgroup sample sizes, please contact press@google.com.Related ArticleAdvancing healthcare with the Healthcare Interoperability Readiness ProgramHow Google Cloud is helping healthcare organizations achieve interoperability.Read Article
Quelle: Google Cloud Platform
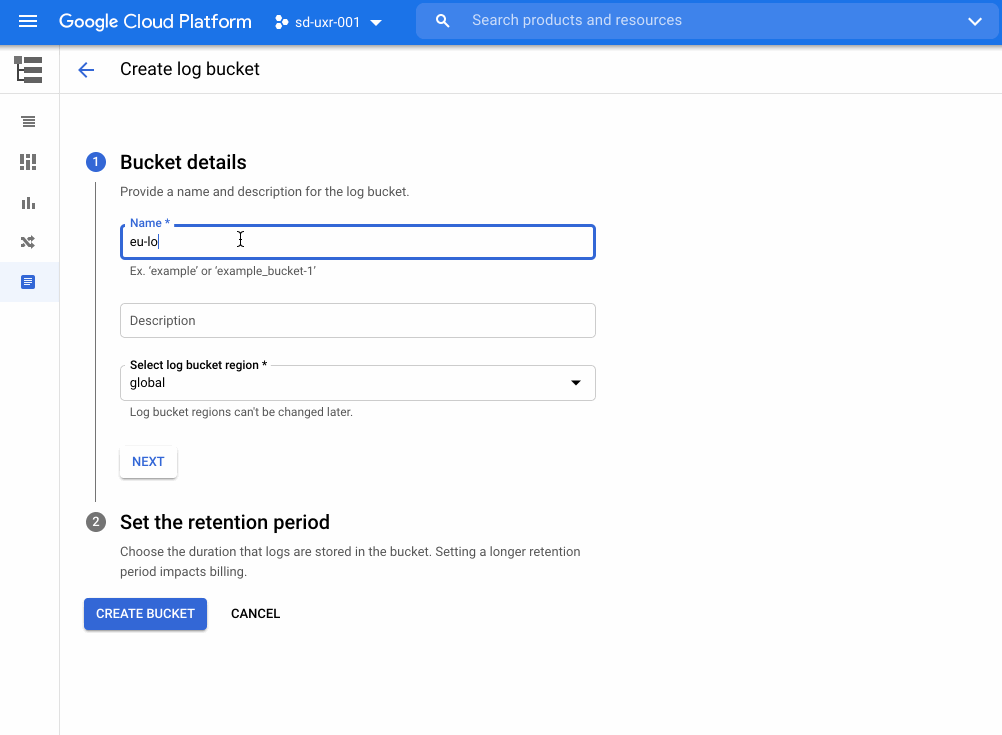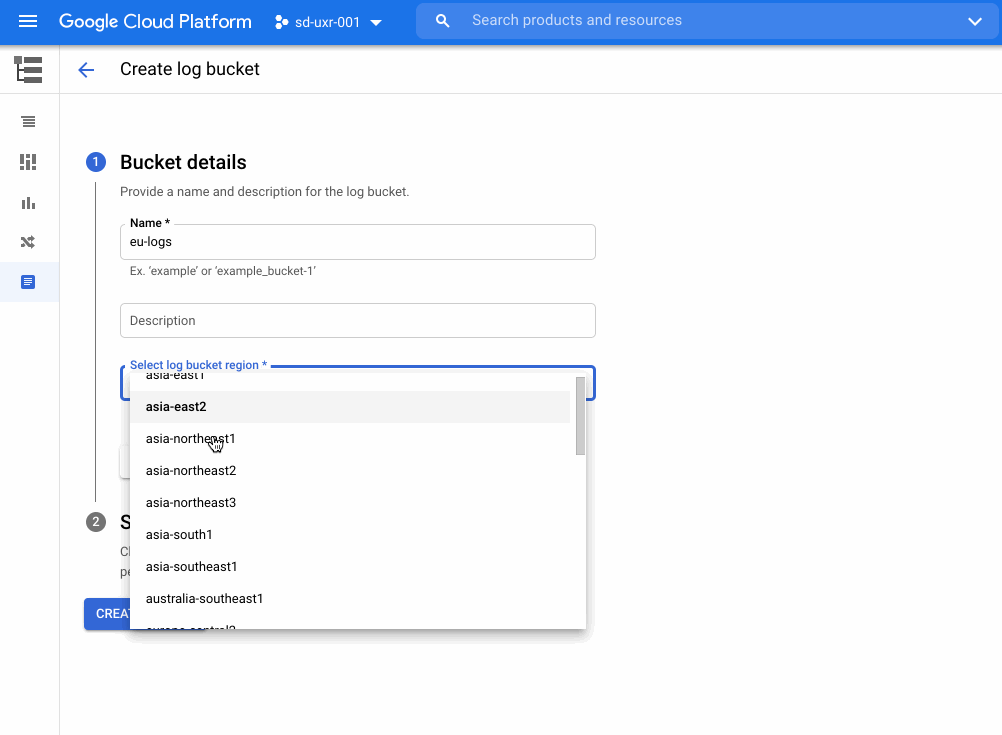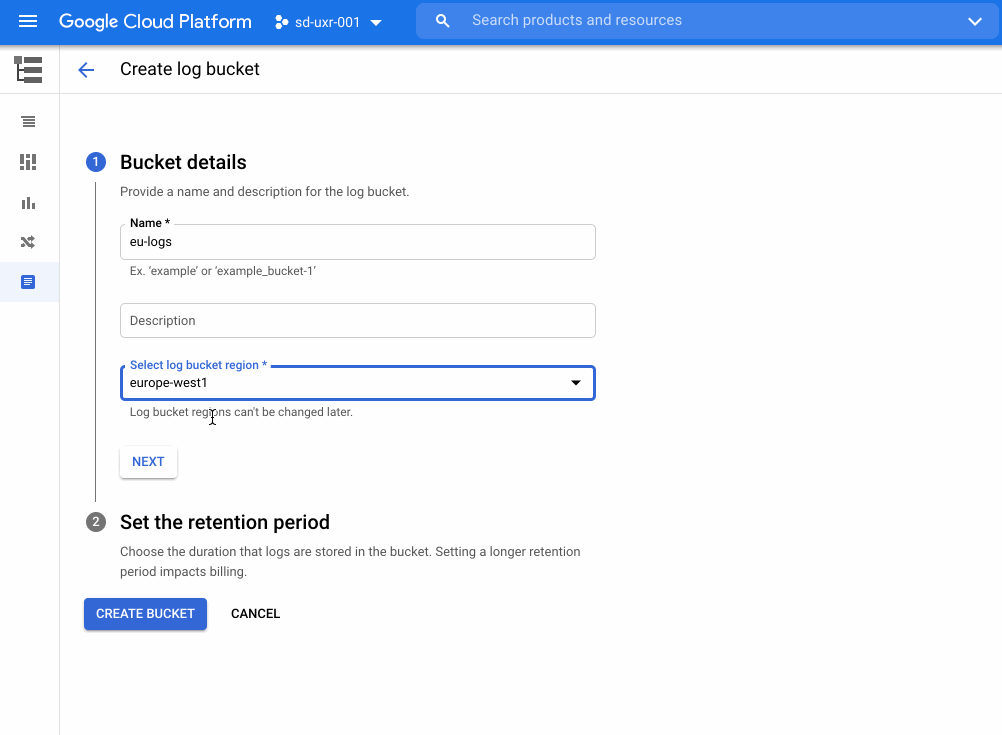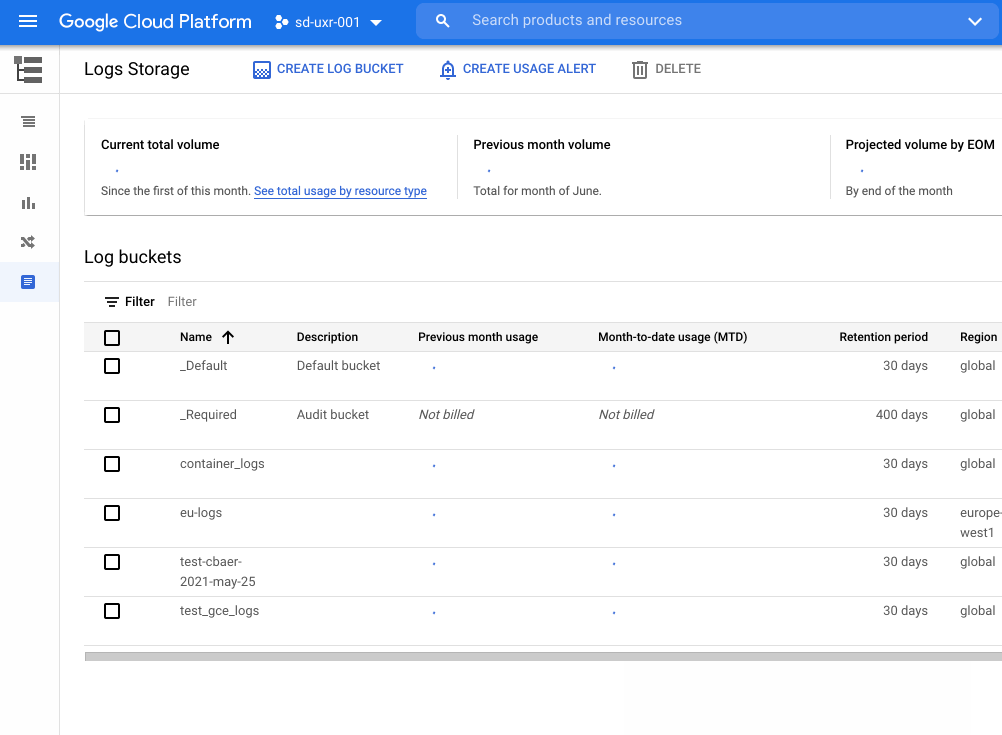
Logs are an essential part of troubleshooting applications and services. However, ensuring your developers, DevOps, ITOps, and SRE teams have access to the logs they need, while accounting for operational tasks such as scaling up, access control, updates, and keeping your data compliant, can be challenging. To help you offload these operational tasks associated with running your own logging stack, we offer Cloud Logging. If you don’t need to worry about data residency, Cloud Logging will pick a region to store and process your logs. If you do have data governance and compliance requirements, we’re excited to share that Cloud Logging now offers even more flexibility and control by providing you a choice of which region to store and process your logging data. In addition to the information below, we recently published a whitepaper that details compliance best practices for logs data.Choose from 23 regions to help keep your logs data compliantLog entries from apps and services running on Google Cloud will automatically be received by Cloud Logging within the region where the resource is running. From there, logs will be stored in log buckets. Log buckets have many attributes in common with Cloud Storage buckets, including the ability to:Set retention from 1 day to 10 yearsLock a log bucket to prevent anyone from deleting logs or reducing the retention period of the bucketChoose a region for your log bucket. We recently introduced support for 23 regions to host your log buckets:Europe – europe-central2, europe-north1, europe-west1, europe-west2, europe-west3, europe-west4, europe-west6Americas – us-central1, us-east1, us-east4, us-west1, us-west2, us-west3, northamerica-northeast1, southamerica-east1Asia Pacific – asia-east1, asia-east2, asia-northeast1, asia-northeast2, asia-northeast3, asia-south1, asia-southeast1, australia-southeast1 How to create a log bucketYou can get started with regionalized log storage in less than five minutes.Go to the Cloud Console and go to LoggingNavigate to Logs Storage and click on “Create logs bucket”Name the log bucket and choose the desired region. Note that the region cannot be changed later. Set the retention period and then click Create Bucket.Once you have created the bucket, you need to point the incoming logs to that bucket. To complete this:Go to the Logs Router section of the Cloud Console and click on the dots to the right of the _Default sink. Select “Edit Sink”Under Sink Destination, change the log bucket selected from “projects/…/_Default” to “projects/…/ (name of newly created bucket)”. Scroll to the bottom and select “Update sink” to save the changesIf you need more detailed information on this topic, please see our step by step getting started guide for overcoming common logs data compliance challenges. More about data residency in Cloud LoggingWe have covered a lot of information about logs in this blog. For more on this topic and other best practices for compliance with logs data, please download this whitepaper. We hope this helps you focus on managing your apps rather than your operations. If you would like to pose a question or join the conversation about Google Cloud operations with other professionals, please visit our new community page. Happy Logging!Related ArticleRead Article
Quelle: Google Cloud Platform

ML pipelines are great at automating end-to-end ML workflows, but what if you want to go one step further and automate the execution of your pipeline? In this post I’ll show you how to do exactly that. You’ll learn how to trigger your Vertex Pipelines runs in response to data added to a BigQuery table.I’ll focus on automating pipeline executions rather than building pipelines from scratch. If you want to learn how to build ML pipelines, check out this codelab or this blog post.What are ML pipelines? A quick refresherIf the term ML pipeline is throwing you for a loop, you’re not alone! Let’s first understand what that means and the tools we’ll be using to implement it. ML pipelines are part of the larger practice of MLOps, which is concerned with productionizing ML workflows in a reproducible, reliable way. When you’re building out an ML system and have established steps for gathering and preprocessing data, and model training, deployment, and evaluation, you might start by building out these steps as ad-hoc, disparate processes. You may want to share the workflow you’ve developed with another team and ensure they get the same results as you when they go through the steps. This will be tricky if your ML steps aren’t connected, and that’s where pipelines can help. With pipelines, you define your ML workflow as a series of steps or components. Each step in a pipeline is embodied by a container, and the output of each step will be fed as input to the next step. How do you build a pipeline? There are open source libraries that do a lot of this heavy lifting by providing tooling for expressing and connecting pipeline steps and converting them to containers. Here I’ll be using Vertex Pipelines, a serverless tool for building, monitoring, and running ML pipelines. The best part? It supports pipelines built with two popular open source frameworks: Kubeflow Pipelines (which I’ll use here) and Tensorflow Extended (TFX).Compiling Vertex Pipelines with the Kubeflow Pipelines SDKThis post assumes you’ve already defined a pipeline that you’d like to automate. Let’s imagine you’ve done this using the Kubeflow Pipelines SDK. Once you’ve defined your pipeline, the next step is to compile it. This will generate a JSON file with your pipeline definition that you’ll use when running the pipeline.With your pipeline compiled, you’re ready to run it. If you’re curious what a pipeline definition looks like, check out this tutorial.Triggering a pipeline run from data added to BigQueryIn MLOps, it’s common to retrain your model when new data is available. Here, we’ll look specifically at how to trigger a pipeline run when more data is added to a table in BigQuery. This assumes your pipeline is using data from BigQuery to train a model, but you could use the same approach outlined below and replace BigQuery with a different data source. Here’s a diagram of what we’ll build:To implement this, we’ll use a Cloud Function to check for new data, and if there is we’ll execute our pipeline. The first step here is to determine how many new rows of data should trigger model retraining. In this example we’ll use 1000 as the threshold, but you can customize this value based on your use case. Inside the Cloud Function, we’ll compare the number of rows in our BigQuery table to the amount of data last used to train our model. If it exceeds our threshold, we’ll kick off a new pipeline run to retrain our model.There are a few types of Cloud Functions to choose from. For this we’ll use an HTTP function so that we can trigger it with Cloud Scheduler. The function will take two parameters: the name of the BigQuery dataset where you’re storing model training data, along with the table containing that data. The function then creates a table called count in that dataset, and uses it to keep a snapshot of the number of rows used last time you ran your retraining pipeline:If the current number of rows in the table exceeds the latest value in the count table by your predetermined threshold, it’ll kick off a pipeline run and update count to the new number of rows with the Kubeflow Pipelines SDK method create_run_from_job_spec:The resulting count table will show a running log of the size of your data table each time the function kicked off a pipeline run:You can see the full function code in this gist, where the check_table_size function is the Cloud Functions entrypoint. Note that you’ll want to add error handling based on your use case to catch scenarios where the pipeline run fails.When you deploy your function, include a requirements.txt file with both the kfp and google-cloud-bigquery libraries. You’ll also need your compiled pipeline JSON file. Once your function is deployed, it’s time to create a Cloud Scheduler job that will run this function on a recurring basis. You can do this right from the Cloud Scheduler section of your console. First, click Create job and give the job a name, frequency, and time zone. The frequency will largely depend on how often new data is added in your application. Setting this won’t necessarily run your pipeline with the frequency you specify, it’ll only be checking for new data in BigQuery[1]. In this example we’ll run this function weekly, on Mondays at 9:00am EST:Next, set HTTP as the target type and add the URL of the Cloud Function you deployed. In the body, add the JSON with the two parameters this function takes: your BigQuery dataset and table name:Then create a service account that has the Cloud Functions Invoker role. Under Auth header, select Add OIDC token and add the service account you just created:With that, you can create the Scheduler job, sit back, and relax with the comforting thought that your retraining pipeline will run when enough new data becomes available. Want to see everything working? Go to the Cloud Scheduler in your console to see the last time your job ran:You can also click the Run Now button on the right if you don’t want to wait for the next scheduled time. To test out the function directly, you can go to the Functions section of your console and test it right in the browser, passing in the two parameters the function expects:Finally, you can see the pipeline running in Vertex AI. Here’s an example of what a completed pipeline run looks like:What’s next?In this post I showed you how to trigger your pipeline when new data is added to a BigQuery table. To learn more about the different products I covered here, check out these resources:Vertex Pipelines intro codelabCloud Scheduler quickstartCloud Functions quickstartDo you have comments on this post or ideas for more ML content you’d like to see? Let me know on Twitter at @SRobTweets.[1] Note that if you’d like to run your pipeline on a recurring schedule you can use the create_schedule_from_job_spec method as described in the docs. This will create a Cloud Scheduler job that runs your pipeline at the specified frequency, rather than running it only in response to changes in your Cloud environment.Thank you to Marc Cohen and Polong Lin for their feedback on this post.Related ArticleUse Vertex Pipelines to build an AutoML classification end-to-end workflowHow you can use Vertex Pipelines to build an end-to-end ML workflow for training a custom model using AutoMLRead Article
Quelle: Google Cloud Platform
Amazon Keyspaces (für Apache Cassandra), ein skalierbarer, hochverfügbarer und vollständig verwalteter Apache Cassandra-kompatibler Datenbankdienst, optimiert jetzt automatisch die über AWS PrivateLink hergestellten Client-Verbindungen, um die Verfügbarkeit und den Lese-/Schreibdurchsatz zu verbessern.
Quelle: aws.amazon.com
Amazon Rekognition Custom Labels bietet eine vereinfachte Einführungserfahrung mit der Möglichkeit, Bilder, Etiketten und Datensätze durch die Erstellung von Beispielprojekten mit einem Klick zu erkunden. Amazon Rekognition Custom Labels bietet sofort einsatzbereite Video-Tutorials und Beispielprojekte mit Hunderten von Bildern für die Klassifizierung in einer Klasse, die Klassifizierung in mehreren Klassen, die Objekterkennung und die Logoerkennung.
Quelle: aws.amazon.com
Der Amazon DynamoDB Accelerator (DAX) SDK für Java 2.x ist jetzt erhältlich und kompatibel mit dem AWS SDK for Java 2.x. Sie können Java-Applikationen mit beschleunigtem Zugriff auf DynamoDB erstellen und von der blocking I/O und anderen Funktionen des neuesten AWS SDK for Java profitieren.
Quelle: aws.amazon.com
Wir freuen uns, die Verfügbarkeit kleinerer Amazon EC2 G4ad instances anzukündigen, die eine bis zu 40% bessere Preisleistung als vergleichbare GPU-basierte Instanzen für grafikintensive Anwendungen wie virtuelle Workstations und Game-Streaming bieten. Wie die anderen G4ad instances werden auch diese neuen Größen von AMD Radeon Pro V520-Grafikprozessoren und AMD EPYC-Prozessoren der zweiten Generation angetrieben. Sie sind so konzipiert, dass sie kosteneffizient für Arbeitslasten sind, die nicht die hohe vCPU und den großen Systemspeicher benötigen, die die aktuellen größeren G4ad-Instanzgrößen bieten, und stellen die kostengünstigste GPU-Instanz in der AWS Cloud dar.
Quelle: aws.amazon.com
Das AWS Solutions-Team hat kürzlich die AWS-Streaming-Daten-Lösung für Amazon MSK aktualisiert. Die AWS-Lösungsimplementierung bietet eine automatisierte Konfiguration der AWS-Services, die für die einfache Erfassung, Speicherung, Verarbeitung und Bereitstellung von Streaming-Daten erforderlich sind.
Quelle: aws.amazon.com