Elektroautos: Fiat will nach 2030 keine Verbrenner mehr produzieren
Zwischen 2025 und 2030 will der italienische Autohersteller Fiat komplett auf die Produktion elektrischer Autos umstellen. (Fiat Chrysler, Elektroauto)
Quelle: Golem

Zwischen 2025 und 2030 will der italienische Autohersteller Fiat komplett auf die Produktion elektrischer Autos umstellen. (Fiat Chrysler, Elektroauto)
Quelle: Golem

Das neue Topmodell der Golem-Systeme nutzt eine schnelle Ryzen-CPU, dazu eine PCIe-Gen4-SSD von Samsung und eine Geforce RTX 3080. (Aus dem Verlag, Grafikhardware)
Quelle: Golem

Heizen in Gebäuden verursacht mit am meisten CO2-Emissionen. Um sie zu senken, versucht man nun, Erdgas mit grünem Wasserstoff zu mischen. Ein Bericht von Monika Rößiger (Wasserstoff, Klima)
Quelle: Golem

Nvidia kündigt an und DHL kassiert. Die Woche im Video. (Golem-Wochenrückblick, Onlinewerbung)
Quelle: Golem
According to the American Cancer Society, roughly 4,950 new cases get diagnosed each day, in the United States alone. No matter what type or stage, cancer is a devastating disease that has an impact on not just the individual diagnosed, but also their family, friends and colleagues. The sad reality is that at some point in your career, you may be in the challenging position of either navigating a cancer diagnosis or supporting a friend or colleague with their cancer journey.
Quelle: CloudForms
Site Reliability Engineering (SRE), initially popularized by Google, is an operating model to solve complex operational issues associated with scalable and highly reliable data center sites. As a development practice founded in engineering, SRE has been a method helpful in industries such as banking align business objectives with technical development and operations goals.
Quelle: CloudForms
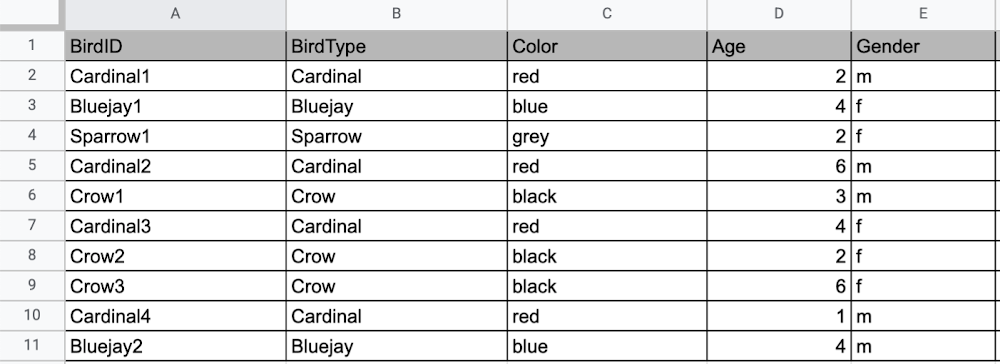
Learning to use a new database can be daunting, even more so if you don’t already have technical knowledge about databases. In this article, I will break down some database basics, terms you should know, what Firestore is, how it works, how it stores data, and how to get started using it with the assumption that you don’t have any existing database knowledge.Before we dive into what Cloud Firestore is, let’s discuss some key database terms you should know. Feel free to skip this section if you are already familiar with the basics of Relational and non-relational databases. What is a database? A database is software that allows you to easily access, manage, modify, update, control and organize data. The way you want to store information can impact what type of database you choose. There are two major categories of databases, Relational and non-relational. Relational DatabaseA relational database can be thought of like a spreadsheet. You can store information in your spreadsheet like this: Now, what happens if I want to store information about where Sparrow1 lives, in my spreadsheet, but I don’t care about where the other birds live? I would have to add another column to my spreadsheet, called home, that would only contain data for the sparrow. That would look like this:Even though I only want to know information about where the sparrow lives, I am required to have blank spaces in the column for all of the other animals. This is because in a relational database, you have a specific structure of your data called a schema. Just like in a spreadsheet, every item you are storing information on must have a place to put information about the bird’s home, even if you only want that information for one bird. This is enforced by the schema, which is essentially the column headers you put in the sheet and dictates a strict structure for the data, which has pros and cons.The strict structure of a relational database allows your application to know what kind of data exists, to know what the data type is, and to enforce rules such as requiring data to be unique, or enforcing type of data stored etc. A schema, by design, forces the data in each row to have the same characteristics, which means it is not very flexible, unless you change the schema for the database. That means if you want to add different data that doesn’t fit your existing schema, you have to change the schema. As we discussed above, if you want to change the schema we are using to store information, such as Home, there is some information that will be stored for all rows, even if you don’t want to store anything. The amount of wasted storage is different between database engines, data types etc. Another thing to consider about Relational databases is that at scale, some traditional Relational databases will require more advanced deployments to handle the scale.Changing the schema of a relational database can be highly disruptive, especially for busy workloads because it requires running scripts to change the schema and coordinating it carefully with the code changes in the app. Due to locking, you might even experience downtime in some cases. Now contrast that with a non-relational document database like Firestore, where you don’t have to worry about schema changes in the databases or downtime as a result of it.Also, when you have a lot of data that you want to collect and it only applies to a few things in your database, having extra space with no information in it can become wasteful because it uses up storage space in many cases. A non-relational database can help get around this problem. Non-relational databasesGenerally speaking, a non-relational database stores information in a different format than a Relational database. There are 4 major categories of non-relational databases that you will hear most frequently.Column-Family Document (Firestore) Key-Value Graph Since this post is focusing on Firestore, in this section we will dive into what a document database is, how it is used, and when to use it.Document database (Firestore) A document database can be thought of as a multi layered collection of entities, such as this: As you can see, when the list is all collapsed, you can only see the information at the top; in this case, that is the BirdID (Cardinal1, Bluejay1, Sparrow1, Cardinal2, Crow1 etc. When I open the list I see “word: word”. For example, the document ID Sparrow1, points to a document with “Type: Sparrow”. I also see “Color: grey”, “Age: 2”, “Gender: f” and “Home: Birdhouse #3”This is known as a key value pair. For “Type: Sparrow”, Type is the key and Sparrow is the value. All of the keys in the Sparrow1 document are: Type, Color, Age, Gender, House. All of the values in the Sparrow1 document are: Sparrow, grey, 2, f, Birdhouse #3.Similarly to how the key gives you context, it allows you to ask the computer for a specific piece of information, such as the age of the bird. It is important to decide on a specific key term you will use for each piece of data you collect so your data can be easily read programmatically. This is called an implicit schema, an implied understanding of how data is stored that is not enforced by the database. Let’s go over what happens when we use an implicit schema.Under Cardinal1, you see Type, Color, Age, and Gender; however, under Sparrow1 you also see House. This is possible because in a non-relational database you don’t have a schema that requires you to store the same information about every bird in your database; instead, you can store the specific information that you need for each bird, regardless of what is stored for other birds. This is a great benefit in terms of flexibility, but because of this flexibility, maintaining standard naming conventions is very important.Now, let’s discuss why using standard naming conventions is so important. In the example above, if I ask a human: “What is the age of Cardinal1?”, they would probably tell me 2. If I asked them: “What is the Age of Bluejay1?”, they would probably tell me 4. These are both correct answers, but they are only correct because a human is able to assume what Age means. A computer, on the other hand, can’t make assumptions. If I ask a computer: “What is the Age of Cardinal1?” it would say 2, but if I ask it: “What is the Age of Bluejay1?” it would not know. This is because the computer is looking for the keyword Age and it isn’t able to use any context clues to determine what other words might mean Age. However, if I asked the computer: “What is the BirdAge of Bluejay1?”, the computer would tell me 4. Why do I care that I need to tell the computer to look for BirdAge to get the age of blujay one, but to look for Age to get the age of Cardinal one? I care because it means I would have to write two entirely different sets of instructions (i.e software code) to get the age of Cardinal1 and the age of Bluejay1 if I am not careful in how I structure my data. But when I structure my data well, this is not an issue and is infact a benefit by adding added flexibility. What we see from this example, is that even without a strict schema, we can (and should) define conventions for document formats. If conventions aren’t defined, things can get unwieldy quickly. How information is accessedNow, let’s discuss how the information is accessed. If I wanted to know information about which birds are blue in our drop down list example, I would need to expand every section of the list to check if the bird is blue or not. As you can imagine, once you start to get a lot of birds in your database, it becomes cumbersome to open every drop down and see if the bird is blue. Luckily, Firestore lets you run these types of queries against the data (See more here) and receive all the documents that satisfy your conditions. On the other hand, if I wanted to know all of the information about Cardinal1, I could just open the drop down for Cardinal1 and I would have all of the information about that bird. Now let’s start using some Firestore specific terminology. For the example we just discussed:CollectionsIn Firestore, your data lives in collections. You can think of collections as tabs in a spreadsheet.Collections can be used to organize data. For example, if I decide that I want to collect data about birds and fish, the data about birds could be put in a birds collection, and the data about fish could be put in a Fish collection. ex:DocumentsThis is the unit of storage that Firestore uses. In our example, each bird is its own document. Documents reside in collections. This is what one document would contain:Each Document corresponds to a row in the sheet. The following diagram demonstrates that each column header maps to a property name in the document and that each value in a row maps to a value in the document.Each document must be identified by a unique identifier. In our example, that is BirdID. Notice that the value for BirdID is stored at the top level of the list, so when the document is closed, you can only see Cardinal1 and Cardinal1 is not also stored within the document. ReferencesAll documents can be uniquely identified by their location. Let’s think through this in words first before we move to code. If I want to tell someone to get data about the sparrow from the drop down lists, I would need to tell them:In the bird drop down list, can you please get all the information under Sparrow1 and put it on a piece of paper called sparrow1Info?Now let’s try that again using Firestore terms. From the birds collection, can you please get the document for sparrow1 from the Firestore database (db) and save it as sparrow1Info?Now let’s try it in code.var sparrow1Info = db.collection(‘birds’).doc(‘sparrow1′);SubcollectionsA subcollection is a collection associated with a document. Using our example of the drop down list, we can add a collection called sightings that stores documents about each sighting of the specific bird. This is what that would look like: It is important to note that you don’t need to have the same subcollections on all documents. For example, Cardinal1 can be the only document that has a subcollection of Sightings. How to search on Google about FirestoreThe hardest part of learning a new technology can often be knowing the right terms to put into Google search to get the answers you are looking for. Here are some key terms that can help you get startedYour question: How should I arrange my data to store it in Firestore?Search: Document database implicit schema designYour Question:What other databases are similar to firestore?Search:What are some document databases Your Question:How do I get all documents in the Birds collection?Search:How to use wildcards in Firestore What next?Try this guide to get started building your first application that uses Firestore: https://firebase.google.com/docs/firestore/quickstart
Quelle: Google Cloud Platform
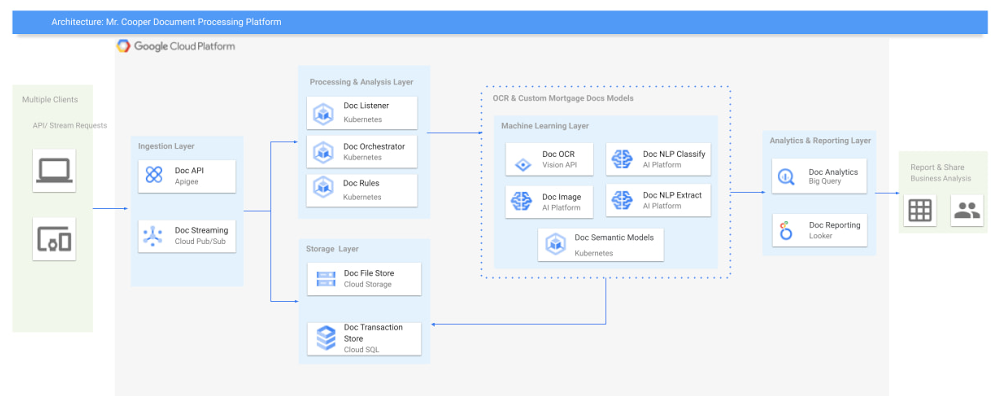
Editor’s note: Mr. Cooper Group is an industry-leading mortgage services provider serving customers through servicing, originations, and digital real estate solutions. Using Google Cloud AI and ML solutions, they created a highly reliable, cloud native document analysis and processing platform to process lending documents and unlocked new levels of accuracy and operational efficiency that help them to scale and control the cost at the same time. Read on to hear how they did it. Mr. Cooper is one of the largest home loan servicers in the country focused on delivering a variety of servicing and lending products, services and technologies to homeowners. Our goal is to shorten the time for loan servicing to increase efficiency and customer satisfaction and are looking for technologies that go beyond typical OCR to identify, classify and extract value out of the document. This would enable getting the right document and document data, to the right person, at the right time thereby improving the overall digital experience for the end customerTo realize these goals, we have to innovate and evolve with at least 3 key metrics: throughput (amount of document pages processed /minute), accuracy (accurately identify and extract information) and cost savings (cost per document page). Additionally, to address both internal customers and external partners, we have to provide an API based integration and a seamless search experience for documents and extracted data.After several pilot verifications and technology spikes, we decided to zero in on the following technology stack: Document AI (including Vision AI, Cloud AutoML), Cloud Storage, Vertex AI, Google Kubernetes Engine (GKE), Cloud SQL, BigQuery, Looker and Apigee on Google Cloud. Here are the advantages we discovered with Google Cloud machine learning services that allowed us to improve performance, better manage our costs, and gain critical smart analytics capabilities: Document AI: The Document AI technology stack, which includes Vision AI and AutoML Natural Language, provides high precision in data processing and helps us understand the documents early in the supply chain, thereby reducing cost and improving efficiency of a highly reliable pipeline.Cloud Storage: This provides us with a landing zone to ingress and egress the documents in a safe and efficient manner, and with Interconnect and VPC Service Controls to ensure that the pipeline is secure.Cost-optimized Kubernetes apps: We were very impressed by GKE’s cost optimizations. We were able to run the nodes at >90% CPU load and managed GKE also provided us with PCI compliance.Fully managed relational database service for MySQL: With Cloud SQL, we were able to scale our databases effortlessly, without compromising performance or availability. We also saw a significant reduction in maintenance costs. Serverless, highly scalable, and cost-effective data warehouse: By integrating BigQuery into our new architecture, we have the analytics capabilities we need, with zero operational overhead.Vertex AI (formerly AI Platform): Helped us to craft various models that are specific to the mortgage documents we need to process.Apigee: The API management platform helped us by providing a common layer to consume the data as APIs, and provided monitoring and monetization functionality.Looker: Integration into Looker provided us with a unified surface to access data across the platform.Building a container-based document pipelineTo start, we kept our architecture modular and designed around lightweight containers and managed services from Google Cloud AI, so that the care and feeding of the server infrastructure was taken care of. To avoid significant manual refactoring and to handle rapid changes in workloads, we built everything as code (Infrastructure as Code). We jived with the Google Cloud AI team to help us validate the architecture and to bring the best of Google to Mr. Cooper.The design to use containers was based on more efficient resource utilization of container-based artifacts and IaaC (using terraform) was already a part of our technology stack, so it was relatively easy to spin up an entire pipeline in a short period of time.Google’s expertise with regards to developing and running artificial intelligence at scale using managed services was a key differentiator in choosing them as a partner. It was through this deep partnership and tight collaboration that we were able to build and execute the right strategy and achieve our desired outcomes.Our team at Mr. Cooper was able to develop and train state-of-the-art machine learning models on mortgage specific documents with very high accuracy along with opportunities to retrain the models using humans in the loop as appropriate.From there, we strived to improve the accuracy of our models by either training the models with additional documents, using models in ensemble fashion and decoupling various parts of the application using an async approach to processing. To achieve this, we mainly relied on these Google Cloud AI services:Google Cloud Vertex AI GKE with Cluster Autoscaling and cluster multi-tenancy to run the codeCloud SQL to manage the databasesClick to enlargeWhile there are more components in our new architecture, because we chose managed services, this did not add additional overhead to our teams. Instead, we focused on achieving our goal of maximizing throughput, improving accuracy and decreasing the cost of the platform.The whole platform was based on an API-first approach. Through Apigee, we exposed these APIs for internal as well as external use to unlock cost savings and improve customer experiences for homeowners.How does Vertex AI and Document AI fit in the picture?Once the documents came into the platform, the Kubernetes Engine at Google with Asynchronous events managed the whole process from landing of the documents through the whole supply chain including state management and any user inputs.There were various classification and extraction cycles that needed to be done on these documents once in the pipeline, where Document AI and Vertex AI from Google Cloud helped us manage multiple versions of custom mortgage models that would extract, classify and store the metadata at scale.To continue to improve accuracy, our team at Mr. Cooper continues to update existing ML models and train new ML models as document format changes or data drift occurs from heterogeneous sources.Building a successful partnershipLooking back, this initiative was incredibly beneficial because it provided us with a wealth of information that, when cross referenced, has the opportunity to open up new monetization opportunities, unlock cost savings, and improve customer experiences, especially during these unprecedented times. In terms of data, we ended up with accuracy of over 95% for critical documents, a peak throughput of 4000 pages/min, an average throughput of 2000 pages/min. This increased our document processing efficiency by 400%, which significantly reduced our costs.It was not only the incredible technology that drove us to choose Google Cloud, but also their team’s unique knowledge of what it takes to scale. Google has nine products with over one billion users each and is uniquely positioned to offer expertise in achieving peak performance at scale. This collaborative partnership with their teams helped guide us on our journey to accomplish this critical strategic initiative.Related ArticleCustomers cut document processing time and costs with DocAI solutions, now generally availableDocument AI platform, Lending DocAI and Procurement DocAI are generally available.Read Article
Quelle: Google Cloud Platform
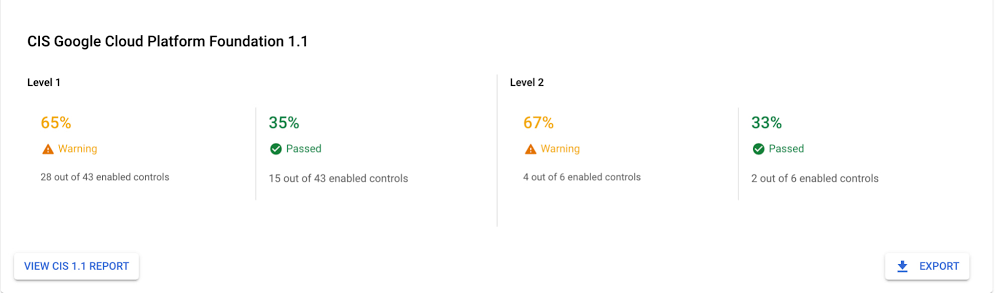
Security Command Center (SCC) is our native Google Cloud product that helps manage and improve your cloud security and risk posture. As a native offering, SCC is constantly evolving and adding new capabilities that deliver more insight to security practitioners. We’ve just released new capabilities in Security Command Center Premium that enable organizations to improve their security posture and efficiently manage risk for their Google Cloud environment. SCC now supports CIS benchmarks for Google Cloud Platform Foundation v1.1, enabling you to monitor and address compliance violations against industry best practices in your Google Cloud environment. Additionally, SCC now supports fine-grained access control for administrators that allows you to easily adhere to the principles of least privilege – restricting access based on roles and responsibilities to reduce risk and enabling broader team engagement to address security.Security Command Center with its native security and risk management capabilities is used by enterprises across the world to protect their environment by gaining visibility into cloud assets, discovering misconfigurations and vulnerabilities in resources, detecting threats targeting Google Cloud assets, and maintaining compliance based on industry standards and benchmarks. These new capabilities further enhance enterprise security teams’ ability to demonstrate accountability and transparency of their Cloud compliance stance and gain operational efficiency with scoped access.Improve your security posture with CIS Google Cloud Foundation 1.1 benchmarkOrganizations can now monitor and see how their Google Cloud environment stacks up against CIS Google Cloud Computing Foundations Benchmark v1.1. The CIS benchmark provides guidance for securing the GCP environment that can help organizations protect from common cyber threats and improve their overall security posture. CIS 1.1 expands coverage to additional Google Cloud services and refines instructions and guidance. With this release in SCC, you can continuously monitor resources and policy violations against common security controls described in the CIS Google Cloud Foundation 1.1 and certified by the Center for Internet Security for alignment with CIS Google Cloud Computing Foundations Benchmark v1.1.0. Security Health Analytics is a built-in service in Security Command Center that provides misconfiguration findings across your GCP environment along with recommendations to remediate those findings. These findings are mapped to the supported compliance standards and industry best practices, giving you the ability to prioritize actions based on the compliance regime applicable to your organization. SCC provides a one-click compliance dashboard, making it seamless to get a complete view of where your environment is passing and failing against the CIS 1.1 benchmarks. It gives you quick posture stance metrics against the different levels in CIS 1.1 benchmarks – Level 1 is considered as a base recommendation to lower the attack surface and Level 2 is considered as a best practice for security conscious organizations. The CIS 1.1 report indicates the number of controls that are passed, how many need to be addressed, and remediation steps for addressing the failed controls against the standard. It also provides an export capability that lets you easily demonstrate your compliance stance to internal and external audit teams.Click to enlargeIn addition to CIS, SCC also supports Payment Card Industry Data Security Standard (PCI DSS v3.2.1), International Organization for Standardization (ISO 27001), and National Institute of Standards and Technology (NIST 800-53). Manage assets and findings within an assigned scope.With the new fine-grained access control capability, you can grant access to assets and findings at the folder and project level. This enables you to isolate projects and folders and restrict employee access to only those who need to do their jobs. If you need to delegate SCC findings to specific teams without having to give those teams a view of the entire organization or need to restrict specific folders for compliance regimes, you can now achieve this using the access control capability. Many organizations are looking to ensure security is addressed earlier on in the development and their application roll out lifecycle. Organizations can use this capability to engage development teams and line-of-businesses to take ownership for addressing the security findings for the assets their teams own. Enabling fine-grained access control at the folder and project level provides individual teams to review findings and quickly act on the ones they are responsible to address. These fine-grained access controls enable your security teams to scale, help reduce the security risk, and achieve compliance goals by limiting access as needed within your organization.If you are already using SCC Premium, you can get started with these new capabilities today using our product documentation. If you don’t yet have an SCC Premium subscription, contact your Google Cloud Platform sales team.
Quelle: Google Cloud Platform
Amazon DocumentDB (mit MongoDB-Kompatibilität) ist ein schneller, skalierbarer, hochverfügbarer und vollständig verwalteter Service für Dokumentdatenbanken, der MongoDB-Workloads unterstützt. Als Dokumentendatenbank macht es Amazon DocumentDB einfach, JSON-Daten jeder Größe zu speichern, abzufragen und zu indizieren.
Quelle: aws.amazon.com