New Lens 5 for Kubernetes adds new features for you to securely access shared clusters from anywhere
Lens 5 includes Lens Spaces, a centralized cloud-based service that lets teams collaborate on cloud-native development.
Quelle: Mirantis
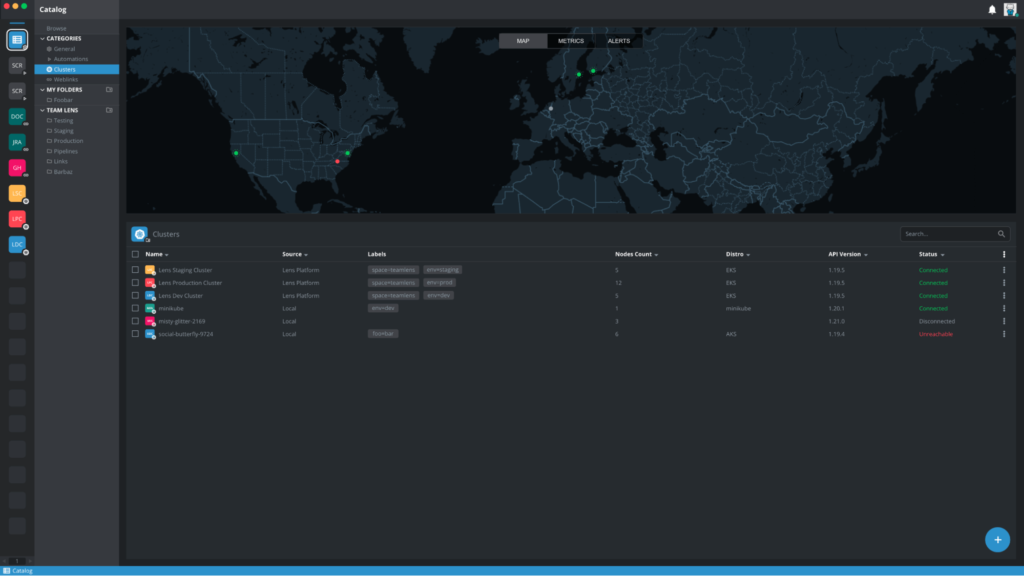
Lens 5 includes Lens Spaces, a centralized cloud-based service that lets teams collaborate on cloud-native development.
Quelle: Mirantis
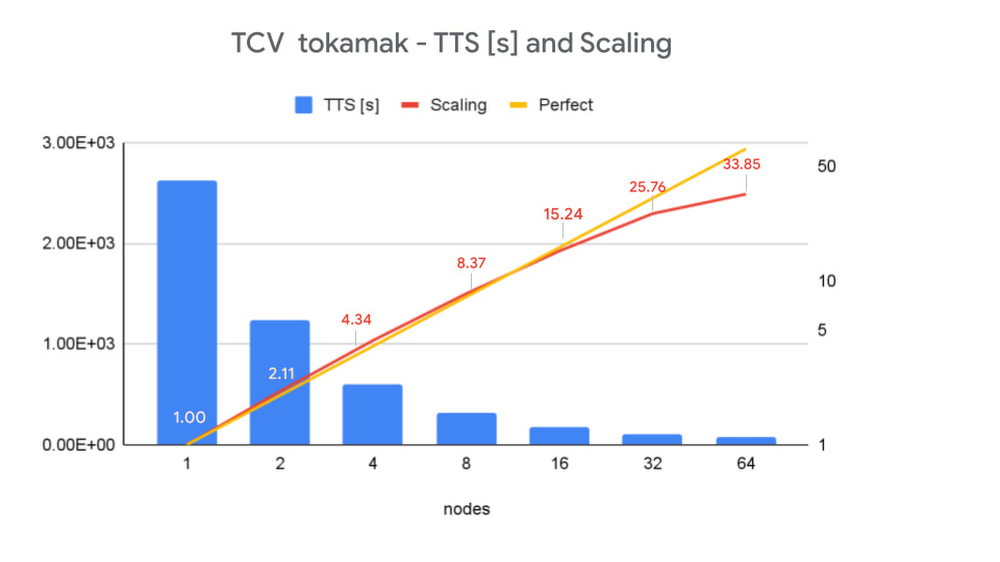
The development of a new clean energy source has the potential to revolutionize our world. The The Swiss Plasma Center at EPFL (École polytechnique fédérale de Lausanne) is trying to do just that: Using intense magnetic fields to confine hydrogen at temperatures up to 100 million degrees, scientists aim to create the conditions for fusion reactions to occur, such as in the stars, thus releasing a huge amount of clean energy—and solving the world’s energy problems in the process. As part of the EUROfusion program, the Swiss Plasma Center is involved in the development of the ITER, the world’s largest scientific experiment under construction, to prove the feasibility of large-scale fusion reactions and pave the way for DEMO, the demonstration fusion reactor. If it succeeds, fusion could solve the world’s energy problems without generating any greenhouse gas or any long-term radioactive waste. The physical simulations that run on these experiments are an essential part of this process.My job as director of operations for Scientific IT and Applications Support at EPFL is to provide High Performance Computing (HPC) resources to scientific projects like this one. Paolo Ricci, a professor at the Swiss Plasma Center, explains that “the field of fusion power entails not just building massive experiments such as ITER that are at the forefront of technology, but also performing cutting-edge theoretical research to better understand, interpret and predict physical phenomena. These predictions are based on large-scale simulations that require the world’s most powerful computers. Researchers need operational support to perform such calculations.” Starting on July 1, EPFL will host a EUROfusion’s Advanced Computing Hub, that will support Europe in the development of the software to carry out the simulation for fusion in Europe, and I will direct its operations.To run these massive simulations, Professor Ricci and his group developed software called GBS. The goal of GBS simulations is to describe and understand the physics of the narrow layer, just a few centimeters thick, that separates the 100-million-degrees plasma core from the machine walls that must be kept at a much lower temperature—just a few hundreds degrees. This temperature gradient, probably the strongest in the universe, is dominated by extremely complex nonlinear multiscale and multiphysics phenomena. An accurate description of this region is crucial to understanding the performance of tokamaks and is thus required for the optimal operation of ITER.Deploying large-scale energy simulations on Google CloudAccurately simulating medium to large tokamaks, the devices where fusion reactions occur, is computationally very demanding and requires a Tier-0 (or currently petaflops-capable) supercomputer. However, resources and access to Tier-0 supercomputers are limited. It is therefore crucial to understand the performance of simulation codes like GBS on Google Cloud, to give the broader scientific community access to the technology.Using Google Cloud’s HPC VM images, we are able to deploy a fully-localized compute cluster using TerraForm recipes from the slurm-gcp project maintained by SchedMD. Users access the cluster’s front end with their EPFL LDAP account and, using Spack, a widely-used package manager for supercomputers, we install the same computing environment as the one we provide on-premises. Overall, we can now deploy a flexible and powerful HPC infrastructure that is virtually identical to the one we maintain at EPFL in less than 15 minutes and dynamically offload on-prem workloads in times of high demand.We tested the performance of GBS with two tokamaks, TCV and JT60-SA, using Google Cloud’s HPC VM images and observed excellent scaling, even with the very demanding large-size tokamak. In terms of ‘time to solution,’ we compared one iteration of the solver running on a Tier-0 supercomputer vs. on Google Cloud. Using the Google Cloud HPC VM Images, we achieved comparable results up to 150 nodes, which is very impressive considering the added flexibility Google Cloud offers. Using Tokamak Configuration Variable (TCV) geometry, our results show excellent scalability: we managed to get a 33X speedup for the TCV tokamak simulation, with a near-perfect scale up to 32 nodes.To test the performance of the HPC VM images, we also performed the same turbulence simulation using a configuration based on JT60-SA, a large-scale advanced tokamak that will operate in Japan with a geometry similar to ITER. Because of its size, simulations on this tokamak become very demanding at around one billion unknowns, but we managed to get very good results up to 150 nodes. Solving the world’s energy problems is a complex problem, and to solve it, our work must be scalable, adaptable, and take advantage of the most advanced computing technologies. Google Cloud provides the needed performance and flexibility to complement the powerful Tier-0 supercomputers we use today.You can learn more about HPC on Google Cloud here.Related ArticleCloud against the storm: Clemson’s 2.1 million VCPU experimentClemson used 2.1 million VCPUs on Google Cloud for hurricane preparednessRead Article
Quelle: Google Cloud Platform
Nordeus’ flagship football team-management simulation, Top Eleven, reached the top of the mobile game charts nearly a decade ago, and it’s been there ever since.Nordeus clearly knows a thing or two about creating exceptional game experiences that keep players coming back. And with a recently completed cloud migration that includes Google Cloud CDN, the Nordeus infrastructure team created a simpler, smarter, and more cost-effective way to sustain its success.According to Strahinja Kustudić, head of infrastructure and data engineering at Nordeus, there are now more than 220 million registered players around the world that play Top Eleven on a very regular basis, and millions more are now playing two other game titles on the company’s active roster. Nordeus itself has emerged as one of Europe’s fastest-growing game developers, with new game titles currently in the works and more than 180 employees working at the company’s headquarters in Belgrade, Serbia.Leaving behind an unscalable, unsustainable on-prem systemUntil 2019, the company delivered all of its gaming content using self-managed, on-premises systems. Their infrastructure included a UK-based data center with more than 400 dedicated servers running a virtual machine-based private cloud production environment, along with a sizable production Hadoop cluster.Keeping everything on-prem gave the Nordeus infrastructure team control and visibility. But for their small and overstretched team, a status quo approach was no longer sustainable.”For a long time, the infrastructure team was just me and one other person,” Kustudić said. “We were doing some extreme over-provisioning, which is something you have to do when you’re running dedicated servers. But we were paying a lot for nothing, and it didn’t make any sense.” At the same time, he added, the team’s challenges with scaling its compute capacity separately from storage meant that a much-needed Hadoop upgrade was unlikely to occur.A legacy CDN with little room for growthThe company’s content delivery network (CDN) comprised another piece of its infrastructure puzzle. Previously, Nordeus relied on a single CDN provider that delivered acceptable performance, Kustudić said, but the process for adding new domains or other management tasks was complex and inefficient.”You had to contact [the CDN provider], talk with them, send them a certificate, and then they had to set it up,” Kustudić stated. “It’s not that easy.”The Nordeus on-prem storage cluster was another potential barrier to growth. While it performed as expected, the server’s high-maintenance, custom storage and file system requirements combined to create yet another source of complexity and inefficiency.According to Kustudić, Nordeus wasn’t eager to take on the potential complexities of a cloud migration project. But moving to the cloud made sense not just from a cost perspective, but from a scalability perspective, too; supporting current and future growth had become unsustainable with on-prem infrastructure.”It wasn’t just about the cost,” Kustudić explained. “We needed a platform that would be much easier to scale, administer, and monitor. We needed a platform that would be flexible and that would allow us to develop faster, move faster, and be a lot more agile.”Going all-in with a cloud migration strategyIn April 2019, Nordeus started its Google Cloud migration project. Over the next six months, and with support from Google Cloud engineers from the outset, Nordeus moved its entire on-prem technology stack into Google Cloud.After taking some initial steps to strengthen the performance of its network, the Nordeus team learned to take advantage of tools like Terraform, which was new to them, and Ansible, which they already had been using to manage their on-prem environment for years. Both contributed to greater efficiency and scalability in their game development, test and launch processes. By January 2020, Nordeus was ready to migrate its final piece of infrastructure: its CDN.Kustudić and his team were impressed by the simplicity of the Google Cloud CDN setup process. “We couldn’t imagine a CDN would be that easy to set up,” Kustudić said. “We don’t want to think about CDN — and that was a big problem with our on-prem system. Over the past year, since we did the migration, it’s not something we ever think about. . . . we know it works and can scale indefinitely.”A CDN strategy designed to scaleAccording to Kustudić, Nordeus achieved both scalability and simplicity while revamping its entire approach to using a CDN. Whenever Nordeus launches a new game, the infrastructure team and any necessary dev teams are able to use a simple Terraform script to launch a CDN environment on demand which includes a Google Cloud Platform project, Cloud Load Balancer, Google Cloud Storage bucket, and Cloud CDN instances. Using this code-based approach allows Nordeus to easily set up multiple test environments to efficiently test games during the development cycle, launch new games quickly, and scale game infrastructure efficiently based on user demands.Cloud Storage also played an important part in solving the company’s CDN challenges. Gone are the custom storage requirements and the inefficiency of storing vast numbers of small files within their filesystem. Instead, CDN origin storage became a non-issue with GCS. “The simplicity of CDN and Cloud Storage was mind-blowing,” Kustudić said. “We don’t have to worry about scaling at all — it just works.” Yet another advantage of using GCS instead of a home-grown on-prem storage cluster is that the infrastructure team doesn’t have to worry about user errors and backing up files anymore — GCS built-in versioning takes care of it.Freeing up the infrastructure team to focus on enabling growthIn terms of bottom-line impact, Kustudić pointed out that Google Cloud CDN delivered clear improvements in latency — especially in Europe, where latency has dropped by 15-20 percent. And while Kustudić pointed out that Nordeus didn’t go into its Google Cloud migration to lower costs, that’s exactly what happened. Its monthly CDN operating costs have declined by about 50%.For Nordeus, saving money with Google Cloud CDN is less important than simply being able to focus on more important things like enabling growth, empowering dev teams to support a faster cadence of releases, and keeping the company on its fast track to global gaming prominence. “It’s insane how good this is, and how easy it is to set up,” Kustudić said. “We got a faster and more flexible platform, with more features than we ever could have had with a private cloud.” Those are important capabilities for any business, but for a fast-growing company working to stay on top of a hotly competitive industry, they can make a critical difference.Learn More About Cloud CDNTo learn more about Cloud CDN, visit the Google Cloud CDN solution page which includes features, documentation, customer stories and more. To get started with Cloud CDN, take a look at our how-to guides and review our best practices here.Related ArticleHTTP/3 gets your content there QUIC, with Cloud CDN and Load BalancingCloud CDN and Load Balancing customers can now serve clients HTTP/3, for better performance for streaming video, image serving and API sc…Read Article
Quelle: Google Cloud Platform
When ATB Financial decided to migrate its vast SAP landscape to the cloud, the primary goal was to focus on things that matter to customers as opposed to IT infrastructure. Based in Alberta, Canada, ATB Financial serves over 800,000 customers through hundreds of branches as well as digital banking options. To keep pace with competition from large banks and FinTech startups and to meet the increasing 24/7 demands of customers, digital transformation was a must. To support this new mandate, in 2019, ATB migrated its extensive SAP backbone to Google Cloud. In addition to SAP S/4 HANA, ATB runs SAP financial services, core banking, payment engine, CRM and business warehouse on Google Cloud. In parallel, changes were needed to ATB’s legacy data platform. The platform had stability and reliability issues and also suffered from a lack of historical data governance. Analytics processes were ad hoc and manual. The legacy data environment was also not set up to tackle future business requirements that come with a high dependency on real-time data analysis and insights.After evaluating several potential solutions, ATB choseBigQuery as a serverless data warehouse and data lake for its next-generation, cloud-native architecture. “BigQuery is a core component of what we call our data exposure enablement platform, or DEEP,” explains Dan Semmens, Head of Data and AI at ATB Financial. According to Semmens, DEEP consists of four pillars, all of which depend on Google Cloud and BigQuery to be successful:Real-time data acquisition: ATB uses BigQuery throughout its data pipeline, starting with sourcing, processing, and preparation, moving along to storage and organization, then discovery and access, and finally consumption and servicing. So far, ATB has ingested and classified 80% of its core SAP banking data as well as data from a number of its third-party partners, such as its treasury and cash management platform provider, its credit card provider, and its call center software. Data enrichment: Before migrating to Google Cloud, ATB managed a number of disconnected technologies that made data consolidation difficult. The legacy environment could handle only structured data, whereas Google Cloud and BigQuery lets the bank incorporate unstructured data sets, including sensor data, social network activity, voice, text, and images. ATB’s data enrichment program has enabled more than 160 of the bank’s top-priority insights running on BigQuery, including credit health decision models, financial reporting, and forecasting, as well as operational reporting for departments across the organization. Jobs such as marketing campaigns and month-end processes that used to take five to eight hours now run in seconds, saving over CA$2.24 million in productivity. Self-service analytics: Data for self-service reporting, dashboarding, and visualization is now available for ATB’s 400+ business users and data analysts. Previously, bringing data and analytics to the business users who needed it while ensuring security was burdensome for IT, fraught with recurrent data preparation and other highly manual elements. Now, ATB automates much of its data protection and governance controls through the entire data lifecycle management process. Data access is not only open to more team members but it is faster and easier to acquire without compromising security. And it’s not just raw data that users can access. ATB uses BigQuery to define its enterprise data models and create what it calls its data service layer to make it easier for team members to visualize their data.AI-assisted analytics and automation: Through Google Cloud and BigQuery, ATB has been able to publish data and ML models that provide alerts and notifications via APIs to customer service agents. These real-time recommendations allow customer service agents to provide more tailored service with contextualized advice and suggested new services. So far, the company has deployed more than 40 ML models to generate over 20,000 AI-assisted conversations per month. Thanks to improved customer advocacy and less churn, the bank has realized more than CA$4 million in operating revenue. During the ongoing COVID crisis, the system was also able to predict when business and personal banking customers were experiencing financial distress so that a relationship manager could proactively reach out to offer support, such as payment deferral or loan restructuring. The AI tools provided by BigQuery are also helping ATB detect fraud that previously evaded rules-based fraud detection by using broader sets of timely and accurate data. Thanks to the speed and ease of moving data from SAP to BigQuery, ATB is using artificial intelligence (AI) and machine learning (ML) to do things it previously hadn’t thought possible, including sophisticated fraud prevention models, product recommendations, and enriched CRM data that improves the customer experience. Using the power of Google Cloud and BigQuery, ATB Financial has been able to draw more value from its SAP data while lowering cost and improving security and reliability. Speed to provide data sets and insights to internal team members has improved 30%. The bank also has seen a 15x reduction in performance incidents while improving data governance and security. Dan Semmens projects that the digital transformation strategy built on Google Cloud and BigQuery has both saved millions compared to its on-premises environment and has also realized millions in new business opportunities. Semmens is looking toward the future that includes initiatives like Open Banking and greater ability to provide real time personalized advice for customers to drive revenue growth. “We see our data platform as foundational to ATB’s 10-year strategy,” he says. “The work we’ve undertaken over the past 18 months has enabled critical functionality for that future.” Learn more about how ATB Financial is leveraging BigQuery to gain more from SAP data. Visit us here to explore how Google Cloud, BigQuery, and other tools can unlock the full value of your SAP enterprise data.Related ArticleRead Article
Quelle: Google Cloud Platform
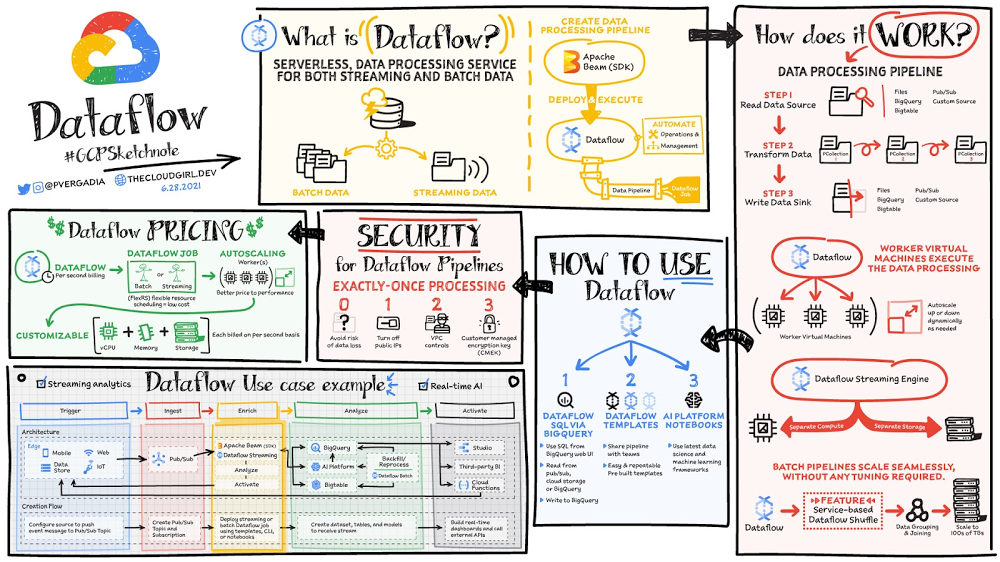
Data is generated in real-time from websites, mobile apps, IoT devices,and other workloads. Capturing, processing and analyzing this data is a priority for all businesses. But, data from these systems is not often in the format that is conducive for analysis or for effective use, by downstream systems. That’s where Dataflow comes in! Dataflow is used for processing & enriching batch or stream data for use cases such as analysis, machine learning or data warehousing. Dataflow is a serverless, fast and cost-effective service that supports both stream and batch processing. It provides portability with processing jobs written using the open source Apache Beam libraries and removes operational overhead from your data engineering teams by automating the infrastructure provisioning and cluster management. Click to enlargeHow does data processing work?In general a data processing pipeline involves three steps: You read the data from a source, transform it and write the data back into a sink.The data is read from the source into a PCollection. The ‘P’ stands for “parallel” because a PCollection is designed to be distributed across multiple machines.Then it performs one or more operations on the PCollection, which are called transforms. Each time it runs a transform, a new PCollection is created. That’s because PCollections are immutable. After all of the transforms are executed, the pipeline writes the final PCollection to an external sinkOnce you have created your pipeline using Apache beam SDK in the language of your choice – Java or Python. You can use Dataflow to deploy and execute that pipeline which is called a Dataflow job. Dataflow then assigns the worker virtual machines to execute the data processing, you can customize the shape and size of these machines. And, if your traffic pattern is spiky, Dataflow autoscaling automatically increases or decreases the number of worker instances required to run your job. Dataflow streaming engine separates compute from storage and moves parts of pipeline execution out of the worker VMs and into the Dataflow service backend. This improves autoscaling and data latency! How to use DataflowYou can create dataflow jobs using the cloud console UI, gcloud CLI or the API. There are multiple options to create a job. Dataflow templates offer a collection of pre-built templates with an option to create your own custom ones! You can then easily share them with others in your organization. Dataflow SQL lets you use your SQL skills to develop streaming pipelines right from the BigQuery web UI. You can join streaming data from Pub/Sub with files in Cloud Storage or tables in BigQuery, write results into BigQuery, and build real-time dashboards for visualization.Using Vertex AI notebooks from the Dataflow interface, you can build and deploy data pipelines using the latest data science and machine learning frameworks. Dataflow inline monitoring lets you directly access job metrics to help with troubleshooting pipelines at both the step and the worker level. Dataflow governanceWhen using Dataflow, all the data is encrypted at rest and in transit. To further secure data processing environment you can:Turn off public IPs to restrict access to internal systems.Leverage VPC Service Controls that help mitigate the risk of data exfiltrationUse your own custom encryption keys customer-managed encryption key (CMEK)ConclusionDataflow is a great choice for batch or stream data that needs processing and enrichment for the downstream systems such as analysis, machine learning or data warehousing. For example: Dataflow brings streaming events to Google Cloud’s Vertex AI and TensorFlow Extended (TFX) to enable predictive analytics, fraud detection, real-time personalization, and other advanced analytics use cases. For a more in-depth look into Dataflow check out the documentation. Want to explore further? Take Dataflow specialization on Coursera& Pluralsight.For more #GCPSketchnote, follow the GitHub repo. For similar cloud content follow me on Twitter @pvergadia and keep an eye out on thecloudgirl.dev.Related ArticleDataflow Under the Hood: Comparing Dataflow with other toolsSee how fully managed streaming service Dataflow helps make stream and batch processing and data analytics easier.Read Article
Quelle: Google Cloud Platform

Die Anwendungsschnittstelle ARM64EC wird native ARM64-Apps für Windows 11 ermöglichen. Ein Teil der Apps kann weiterhin auf x86-64 basieren. (Windows 11, Microsoft)
Quelle: Golem

Die Corona-Pandemie hat zahlreichen Beschäftigten mehr Homeoffice ermöglicht. Laut einer aktuellen Umfrage fühlen sich viele gut damit. (Homeoffice, Internet)
Quelle: Golem

Weil Microsoft bei Windows 11 auf TPM 2.0 setzt, decken sich Scalper mit Modulen ein. Für die meisten Desktop-CPUs ist das aber unnötig. Ein IMHO von Marc Sauter (Windows 11, Microsoft)
Quelle: Golem

Félix “Xqc” Lengyel ist einer der bekanntesten Streamer auf Twitch. Das sorgte für regelmäßigen Besuch von Sondereinsatzkommandos. (Twitch, Games)
Quelle: Golem

Elon Musk jammert in Barcelona ein bisschen über die hohen Investitionen für Starlink und lobt die eigene Entwicklung des Satelliteninternets. (Starlink, Technologie)
Quelle: Golem