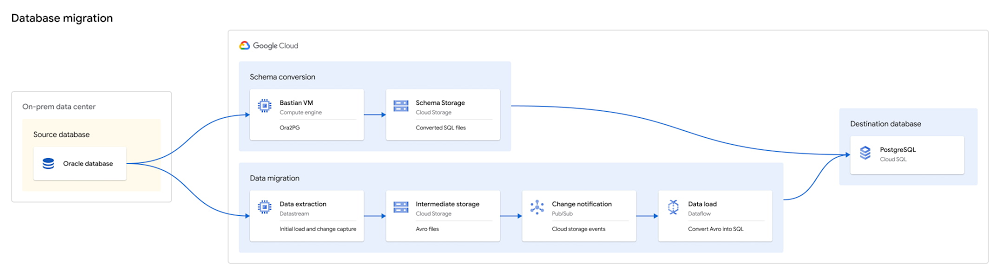
Migrate from Oracle to PostgreSQL with minimal downtime with Datastream
One of the biggest obstacles faced by enterprises pursuing digital transformation is the challenge of migrating off of legacy databases. These databases are typically locked into on-premises data centers, expensive to upgrade and difficult to maintain. We want to make it easier. To that end, we’ve built an open source toolkit that can help you migrate Oracle databases into Cloud SQL for PostgreSQL, and do so with minimal downtime and friction.Click to enlargeThe Oracle to Postgres toolkit uses a mix of existing open source and Google Cloud services, and our own Google-built tooling to support the process of converting schema, setting up low-latency, ongoing data replication, and finally performing migration validation from Oracle to Cloud SQL for PostgreSQL.Migrations are a multi-step process, and can be complex and iterative. We have worked to simplify them, and created a detailed process with stages that are well-documented and easy to run.The stages of a database migration typically include:Deploying and preparing resources, where required resources are deployed and the docker images are built that will be used during the subsequent stages.Converting the schema with Ora2Pg, which is often an iterative process of converting, rebuilding, reviewing, and revising the schema until it aligns with your needs.Continuously migrating the data, which leverages Datastream and Dataflow.Datastream ingests the data from Oracle by reading the log using LogMiner, then stages the data in Google Cloud Storage. As new files are written, a Pub/Sub notification is emitted, and the files are picked up by Dataflow using a custom template to load the data into Cloud SQL for PostgreSQL. This allows you to migrate your data in a consistent fashion using CDC for low downtime.Validating the data migration, which can be used to ensure all data was migrated correctly and it is safe to begin using the destination database. It can also be used to ensure downstream objects (like views or PL/SQL) have been translated correctly.Cutting over to use PostgreSQL, where the application switches from reading Oracle to Postgres.Following these steps will help to ensure a reliable migration with minimal business impact.Since the process of migration tends to be iterative, try migrating a single table or single schema in a test environment before approaching production. You can also use the toolkit to migrate partial databases. For instance, you can migrate one specific application’s schema, while leaving the remainder of your application in Oracle.This post will walk you through each stage in more detail, outlining the process and considerations we recommend for the best results.Deploying and Preparing ResourcesInstalling the Oracle to Postgres toolkit requires a VM with Docker installed. The VM will be used as a bastion and will require access to the Oracle and PostgreSQL databases. This bastion will be used to deploy resources, run Ora2Pg, and run data validation queries.The toolkit will deploy a number of resources used in the migration process. It will also build several Docker images which are used to run Dataflow, Datastream, Ora2Pg, and Data Validation.The Google Cloud resources which are deployed initially are:Any required APIs for Datastream, Dataflow, Cloud Storage, and Pub/Sub which are currently disabled are enabledA Cloud SQL for PostgreSQL destination instanceA Cloud Storage bucket to stage the data as it is transferred between Datastream and DataflowA Pub/Sub topic and subscription setup with Cloud Storage notifications to notify on the availability new filesThe migration preparation steps are:Docker images are built forOra2PgData validationDatastream managementConnectivity is tested to both the Oracle DB and the Cloud SQL for PostgreSQL instanceBefore you begin, ensure that the database you’d like to migrate is compatible with the usage of Datastream. Converting schemas with Ora2Pg Migrating your schema can be a complex process and may sometimes involve manual adjustment to fix issues originating from usage of non-standard Oracle features. Since the process is often iterative, we have divided this into two stages, one to build the desired PostgreSQL schema and a second to apply the schema.The toolkit defines a base Ora2pg configuration file which you may wish to build on. The features selected by default align with the data migration template as well, particularly regarding the use of Oracle’s ROWID feature to reliably replicate tables to PostgreSQL, and the default naming conventions from Ora2Pg (that is, changing all names to lowercase). These options should not be adjusted if you intend to use the Data Migration Dataflow template, as it assumes they have been used.The Oracle ROWID feature, which maintains a consistent and unique identifier per row, is used in the migration as a default replacement for primary keys, in the event that the table does not have a primary key. This is required for data migration using the toolkit, though the field can be removed after the migration is finished if the field is not required by the application. The design converts an Oracle ROWID value into an integer, and then the column is defined as a sequence in PostgreSQL. This allows you to continue to use the original ROWID field as a primary key in PostgreSQL even after the migration is complete.The final stage of the Ora2Pg template applies the desired SQL files which were built in the previous step to PostgresQL. To run this multiple times as you iterate, make sure to clear previous schema iterations from PostgreSQL before re-applying. Since the goal of the migration toolkit is to support migration of Oracle tables and data to PostgreSQL, it does not convert or create all Oracle objects by default. However, Ora2Pg does support a much broader set of object conversions. In the event that you’d like to convert additional objects beyond tables and their data, the docker image can be used to convert any Ora2Pg supported types; however, this is likely to require varying degrees of manual fixes depending on the complexity of your Oracle database. Please refer to the Ora2Pg documentation for support in these steps.Continuously migrating the dataThe data migration phase will require deploying two resources for replication, Datastream and Dataflow. A Datastream stream that pulls the desired data from Oracle is created, and the initial table snapshots (“backfills”) will begin replicating as soon as the stream is started. This will load all the data into Cloud Storage, then leveragingDataflow and the Oracle to PostgreSQL template to replicate from Cloud Storage into PostgreSQL.Datastream utilizes LogMiner for CDC replication of all changes for the selected tables from Oracle, and aligns backfills and ongoing changes automatically. The advantage of the fact that this pipeline buffers data in Cloud Storage is that it allows for easy redeployment in the event that you’d like to re-run the migration, if, say, a PostgreSQL schema changes, without requiring you to re-run backfills against Oracle.The Dataflow job is customized with a pre-built, Datastream-aware template to ensure consistent, low-latency replication between Oracle and Cloud SQL for PostgreSQL. The template uses Dataflow’s stateful API to track and consistently enforce order at a primary key granularity. As mentioned above, this leverages the Oracle ROWID for tables which do not have a primary key, for reliable replication of all desired tables. This ensures the template can scale to any desired number of PostgreSQL writers, to maintain low latency replication at scale, without losing consistent order. During the initial replication (“backfill”), it’s a best-practice to monitor and consider scaling up PostgreSQL resources if replication speeds are running slower than expected, as this phase in the pipeline has the greatest likelihood of being a bottleneck. Replication speeds can be verified using the events per second metric in the Dataflow job.Note that DDL changes on the source are not supported during migration runtime, so ensure your source schema can be stable for the duration of the migration run.Validating the data migrationDue to the inherent complexity of heterogeneous migrations, it is highly recommended to use the data validation portion of the toolkit as you prepare to complete the migration. This is to ensure that the data was replicated reliably across all tables, that the PostgreSQL instance is in a good state and ready for cutover, and to validate complex views or PL/SQL logic in the event that you used Ora2Pg to migrate additional Oracle objects beyond tables (though outside the scope of this post).We provide validation tooling which is created from the latest version of our open source Data Validator. The tool allows you to run a variety of high-value validations, including schema (column type matching), row count, and more complex aggregations.After Datastream reports that backfills are complete, an initial validation can ensure that tables look correct and that no errors which resulted in data gaps have occurred. Later in the migration process, you can build filtered validations or validate a specific subset of data for pre-cutover validation. Note that since this type of validation is run once you’ve stopped replicating from source to destination, it’s important that it runs faster than the backfill validation to minimize downtime. For this reason, it gives a variety of options to filter or limit the number of tables validated to run more quickly while still giving high confidence of the integrity of the migration.If you’ve re-written PL/SQL as part of your migration, we encourage more complex validation usage. For example, using `–sum “*”` in a validation will ensure that the values in all numeric columns add up to the same value. You can also group on a key (like a date/timestamp column) to validate slices of the tables. These will help ensure the table is not just valid, but is also accurate after SQL conversion occurs.Cutting over to use PostgreSQLThe final step in the migration is the cutover stage, when your application begins to use the destination Cloud SQL for PostgreSQL instance as its system of record. Since the time of cutover is preceded by database downtime, this should be scheduled in advance if it can cause a business disruption. As part of the process of preparing for cutover, it’s a best practice to validate that your application has been updated to be able to read from and write to PostgreSQL, and the user has all the permissions required before the final cutover occurs.The process of cutover is:Check if there are any open transactions on Oracle and ensure that the replication lag is minimal When there are no outstanding transactions, stop writes to the Oracle database – downtime beginsEnsure all outstanding changes are applied to the Cloud SQL for PostgreSQL instanceRun any final validations with the Data ValidatorPoint the application at the PostgreSQL instanceAs mentioned above, running final validations will add downtime, but is recommended as a way to ensure a smooth migration. Preparing Data Validations beforehand and timing their execution accordingly will allow you to balance downtime with confidence in the migration result.Get started todayYou can get started today with migrating your Oracle databases to Cloud SQL for PostgreSQL with the Oracle to PostgreSQL toolkit. You can find much more detail on running the toolkit in the Oracle to PostgreSQL Tutorial, or in our Oracle to PostgreSQL Toolkit repository.
Quelle: Google Cloud Platform