Chia Coin: SSD-Hersteller warnt vor Kryptomining
Eine neue Kryptowährung hat zu einem Boom bei Speichermedien geführt. Ein Hersteller warnt, durch Kryptomining könne die Garantie auf SSDs erlöschen. (Solid State Drive, Speichermedien)
Quelle: Golem

Eine neue Kryptowährung hat zu einem Boom bei Speichermedien geführt. Ein Hersteller warnt, durch Kryptomining könne die Garantie auf SSDs erlöschen. (Solid State Drive, Speichermedien)
Quelle: Golem

Apple will im Falle einer Reparatur beim iPad Pro 12,9 Zoll mit Micro-LED-Displayhintergrundbeleuchtung viel Geld verlangen. Abhilfe schafft nur eine Versicherung. (iPad Pro, Apple)
Quelle: Golem

Deutschland könnte die größte Chipfabrik Europas bekommen. Intel macht die Standortentscheidung jedoch von staatlicher Förderung abhängig. (Intel, Pat Gelsinger)
Quelle: Golem
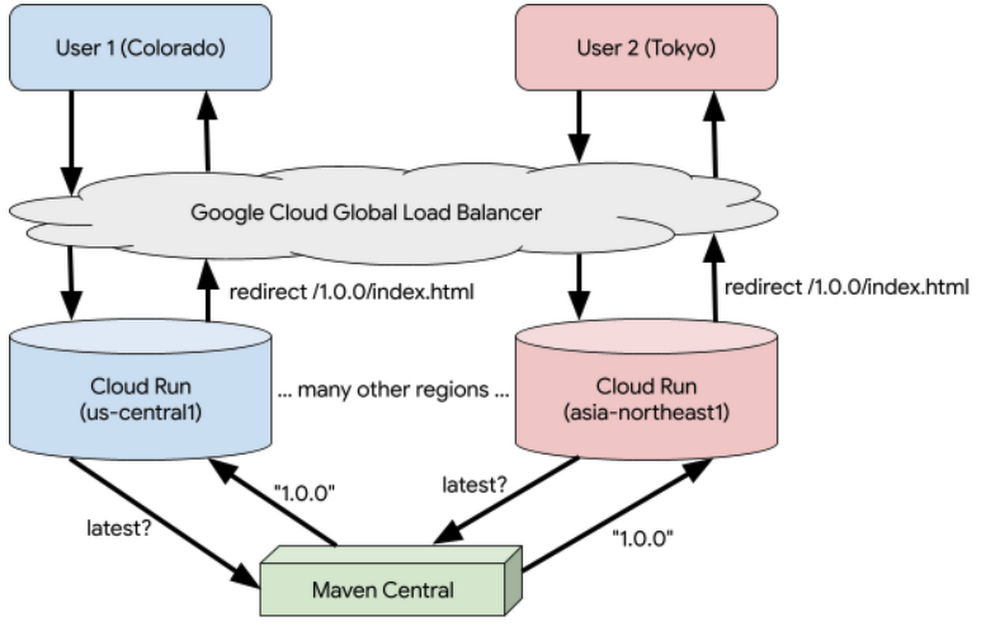
Delivering web-based software is no longer as simple as ssh’ing into a LAMP server and vi’ing a php file. For good reasons, many of us have evolved practices and adopted technologies to address growing complexities and modern needs. Recently I put together a jigsaw puzzle of various technologies and practices so that I could deploy a globally distributed, scale-on-demand, edge-cached, webapp while taking advantage of container-based portability, infrastructure automation, and Continuous Integration / Continuous Delivery.The major pieces of the puzzle include: The Java Virtual Machine (JVM), Scala, sbt, Docker, GraalVM, Cloud Native Buildpacks, bash, git, GitHub Actions, Google Cloud Run, Google Cloud Build, Google Cloud CDN, Google Container Registry, and Google Domains. That is a lot of pieces! Let’s first look at the use case that I was solving for.JavaDocs globally distributed & scale-on-demandLibraries in the JVM ecosystem (created with Java, Kotlin, Scala, etc) are typically published to a repository called Maven Central. It currently has over 6 million artifacts (a version of some library). When a library author publishes their library they typically include an artifact that contains versioned documentation (i.e. JavaDoc). These artifacts are basically ZIP files containing some generated HTML. When you use a library typically you reference its JavaDoc either in your IDE or on a webpage where it has been published.As a fun experiment I created a website that pulls JavaDocs out of Maven Central and displays them on a webpage. If you are familiar with Java libraries and can think of one, check out my website:https://javadocs.dev/As an example, check out the gRPC Kotlin stub JavaDocs:https://javadocs.dev/io.grpc/grpc-kotlin-stub/latestThat site should have loaded super fast for you, no matter where you are, because I’ve put together the puzzle of creating a scale-on-demand webapp that is globally distributed with great edge caching. Here’s what the runtime architecture looks like:1. Get latest JavaDocs for io.grpc:grpc-kotlin-stubjavadocs.dev/io.grpc/grpc-kotlin-stub/latest2. Get index.html for JavaDoc io.grpc:grpc-kotlin-stub:1.0.0javadocs.dev/io.grpc/grpc-kotlin-stub/1.0.0/index.htmlBest of all, the entire system is continuously delivered on merge to main via a few lines of Cloud Build configuration. As a spoiler, here is all the build config you need to have the same sort of globally distributed, scale-on-demand, edge-cached, webapp:To make things that easy and to make the app start super fast, I had to go on a bit of a journey putting together many different pieces. Let’s walk through everything.Super-fast startup without sacrificing developer experienceThe “JavaDoc Central” webapp is a proxy for Maven Central metadata and artifacts. It needs to query metadata from the repository like translating a version of “latest” to the actual latest version. When a user requests the JavaDoc for a given artifact it needs to pull that associated JavaDoc from Maven Central, extract it, and then serve the content.Traditionally webapp hosting relied on over-provisioning so that when a request arrives the server is ready to handle it. Scale-on-demand takes a more efficient approach where underlying resources are dynamically allocated as requests come in but are also automatically deallocated when the number of requests decreases. This is also called auto-scaling or serverless. The nice thing about scale-on-demand is that there aren’t wasted / underutilized servers. But a challenge with this approach is that applications need to startup super fast because when the demand (number of requests) exceeds the available supply (underlying servers), a new server needs to be started so the excess demand can then be handled by a freshly started server. This is called a “cold-start” and has different impacts depending on many variables: programming platform, size of application, necessity for cache hydration, connection pooling, etc.Cold-starts happen any time the demand exceeds the supply, not just when scaling up from zero servers.An easy way to deal with some cold-start issues is to use programming platforms that don’t have significant startup overhead. JVM-based applications typically take at least a few seconds to startup because the JVM has startup overhead, JAR loading takes time, classpath scanning for dependency injection can be slow, etc. For this reason technologies like Node.js, Go, and Rust have been popular with scale-on-demand approaches.Yet, I like working on the JVM for a variety of reasons including: great library & tooling ecosystem and modern high-level programming languages (Kotlin & Scala). I’m incredibly productive on the JVM and I don’t want to throw away that productivity just to better support scale-on-demand. For more details, read my blog: The Modern Java Platform – 2021 EditionLuckily there is a way to have my cake and eat it too! GraalVM Native Image takes JVM-based applications and instead of running them on the JVM, it Ahead-Of-Time (AOT) compiles them into native applications. But that process takes time (minutes, not seconds) and I wouldn’t want to wait for that to happen as part of my development cycle. The good news is that I can run JVM-based applications on the JVM as well as native images. This is exactly what I do with the JavaDoc Central code. Here is what my development workflow looks like:To create a native image with GraalVM I used a build tool plugin. Since I’m using Scala and the sbt build tool, I used the sbt-native-packager plugin but there are similar plugins for Maven and Gradle. This enables my Continuous Delivery system to run a command to create an AOT native executable from my JVM-based application:./sbt graalvm-native-image:packageBinGraalVM Native Image optionally allows native images to be statically linked so they don’t even need an operating system to run. The resulting container image for my entire statically linked JavaDoc webapp is only 15MB and starts up in well under a second. Perfect for on-demand scaling!Multi-region deployment automationWhen I first deployed the javadocs.dev site I manually created a service on Cloud Run that runs my 15MB container image but Cloud Run services are region-based so latency to them differ depending on where the user is (turns out the speed of light is fairly slow for round-the-globe TCP traffic). Cloud Run is available in all 24 Google Cloud regions but I didn’t want to manually create all those services and the related networking infrastructure to handle routing. There is a great Cloud Run doc called “Serving traffic from multiple regions” that walks through all the steps to create a Google Cloud Load Balancer in front of n-number of Cloud Run services. Yet, I wanted to automate all that so I embarked on a journey that further complicated my puzzle but resulted in a nice tool that I use to automate global deployments, network configurations, and global load balancing.There are a number of different ways to automate infrastructure setup, including Terraform support for Google Cloud. But I just wanted a container image that’d run some gcloud commands for me. Writing those commands is pretty straightforward but I also wanted to containerize them so they’d be easily reusable in automated deployments.Typically, to containerize stuff like this, a Dockerfile is used to define the steps needed to go from source to the thing that will be runnable in the container. But Dockerfiles are only reusable with copy & paste resulting in security and maintenance costs that are not evident initially. So I decided to build a Cloud Native Buildpack for gcloud scripts that anyone could reuse to create containers for gcloud automations. Buildpacks provide a way to reuse the logic for how source gets turned into runnable stuff in a container.After an hour of learning how to create a Buildpack, the gcloud-buildpack was ready! There are only a couple pieces which you don’t really need to know about since Buildpacks abstracts away the process of turning source into a container image, but let’s go into them so you can understand what is under-the-covers.Buildpack run imageBuildpacks add docker layers onto a “run image” so a Buildpack needs one of those. My gcloud-buildpack needs a run image that has the gcloud command in it. So I just created a new run image based on the gcloud base image and with two necessary labels (Docker metadata) for the Buildpacks:I also needed to setup automation so the run image would automatically be created and stored on a container registry, and any changes would update the container image. I decided to use GitHub Actions to run the build and the GitHub Container Registry to store the container image. Here is the Action’s YAML:Voila! The run image is available and continuously deployed:ghcr.io/jamesward/gcloud-buildpack-run:latestgcloud BuildpackBuildpacks participate in the Cloud Native Buildpack lifecycle and must implement at least two phases: detect & build. Buildpacks can be combined together so you can run something like:pack build –builder gcr.io/buildpacks/builder:v1 fooAnd all of the Buildpacks in the Builder Image will be asked if they know how to build the specified thing. In the case of the Google Cloud Buildpacks they know how to build Java, Go, Node.js, Python, and .NET applications. For my gcloud Buildpack I don’t have plans to add it to a Builder Image so I decided to have my detection always result in a positive result (meaning the buildpack will run no matter what). To do that my detect script just exits without an error. Note: You can create Buildpacks with any technology since they run inside the Builder Image in docker; I just decided to write mine in Bash because reasons.The next phase for my gcloud Buildpack is to “build” the source but since the Buildpack is just taking shell scripts and adding them to my run image, all that needs to happen is to copy the scripts to the right place and tell the Buildpack lifecycle that they are executables / launchable processes. Check out the build code.Since Buildpacks can be used via container images, my gcloud Buildpack needs to be built and published to a container registry. Again I used GitHub Actions:From the user’s perspective, to use the gcloud Buildpack all they have to do is:Create a project containing a .sh fileBuild your project with pack:Now with a gcloud Buildpack in place I’m ready to create a container image that makes it easy to deploy a globally load-balanced service on Cloud Run!Easy Cloud RunI created a bash script that automates the documented steps to setup a multiregion Cloud Run app so that they can all be done as part of a CI/CD pipeline. If you’re interested, check out the source. Using the new gcloud-buildpack I was able to package the command into a container image via GitHub Actions:Now anyone can use the ghcr.io/jamesward/easycloudrun container image with six environment variables, to automate the global load balancer setup and multi-region deployment. When this runs for the javadoccentral repo it looks like this:All of the networking and load balancer configuration is automatically created (if it doesn’t exist) and the Cloud Run services are deployed with the –ingress=internal-and-cloud-load-balancing option so that only the load balancer can talk to them. Even the http to https redirect is created on the load balancer. Here is what the load balancer and network endpoint groups look like in the Google Cloud Console:Setting up a serverless, globally distributed application that is backed by 24 Google Cloud regions all happens in about 1 minute as part of my CI/CD pipeline.Cloud Build CI/CDLet’s bring this all together into a pipeline that tests the javadocs.dev application, creates the GraalVM Native Image container, and does the multi-region deployment. I used Cloud Build since it has GitHub integration and uses service accounts to control the permissions of the build (making it easy to enable Cloud Run deployment, network config setup, etc). The Cloud Build definition (source on GitHub):Step 1 runs the application’s tests. Step 2 builds the application using GraalVM Native Image. Step 3 pushes the container images to the Google Cloud Container Registry. And finally Step 4 does the load balancer / network setup and deploys the application to all 24 regions. Note that I use a large machine for the build since GraalVM Native Image uses a lot of resources. The only custom value in that CI/CD pipeline is the DOMAINS which are needed to setup the load balancer. Everything else is boilerplate.The puzzle comes together!So that was quite the jigsaw puzzle with many pieces! Now that I’ve glued all the pieces together it should be pretty straightforward for you to create your own serverless, globally distributed application on Google Cloud and deploy with easycloudrun. Or maybe you want to use the gcloud Buildpack to create your own automations. Either way, let me know how I can help!Related ArticleIntroducing Cloud Run Button: Click-to-deploy your git repos to Google CloudAdding the Cloud Run button to your github source code repositories lets anyone deploy their application to Google Cloud.Read Article
Quelle: Google Cloud Platform
Here’s a round-up of the key stories we published the week of April 30, 2021.Introducing Open Saves: Open-source cloud-native storage for gamesOpen Saves is a brand-new, purpose-built single interface for multiple storage back ends that’s powered by Google Cloud and developed in partnership with 2K. Now, development teams can store game data without having to make the technical decisions on which storage solution to use. Read more.Related ArticleIntroducing Open Saves: Open-source cloud-native storage for gamesCheck out the new Open Saves interface that lets game developers manage multiple storage back ends–from Google Cloud and 2K Games.Read ArticleTurbocharge workloads with new multi-instance NVIDIA GPUs on GKEWith the launch of multi-instance GPUs in GKE, now you can partition a single NVIDIA A100 GPU into up to seven instances that each have their own high-bandwidth memory, cache and compute cores. Each instance can be allocated to one container, for a maximum of seven containers per one NVIDIA A100 GPU. Further, multi-instance GPUs provide hardware isolation between containers, and consistent and predictable QoS for all containers running on the GPU. Read more.Related ArticleTurbocharge workloads with new multi-instance NVIDIA GPUs on GKEYou can now partition a single NVIDIA A100 GPU into up to seven instances and allocate each instance to a single Google Kubernetes Engine…Read ArticleSign here! Creating a policy contract with Configuration as DataConfiguration as Data is an emerging cloud infrastructure management paradigm that allows developers to declare the desired state of their applications and infrastructure, without specifying the precise actions or steps for how to achieve it. However, declaring a configuration is only half the battle: you also want policy that defines how a configuration is to be used. Here’s how to create one.Related ArticleSign here! Creating a policy contract with Configuration as DataA declarative Configuration as Data approach improves not just configuration, but policy as well.Read ArticleSRE at Google: Our complete list of CRE life lessonsWe created Customer Reliability Engineering, an offshoot of Site Reliability Engineering (SRE), to give you more control over the critical applications you’re entrusting to us. Since then, here on the Google Cloud blog, we’ve published over two dozen blogs to help you take the best practices we’ve learned from SRE teams at Google and apply them in your own environments. Here’s a guide to all of them.Related ArticleSRE at Google: Our complete list of CRE life lessonsFind links to blog posts that share Google’s SRE best practices in one handy location.Read ArticleThe evolution of Kubernetes networking with the GKE Gateway controllerThis week we announced the Preview release of the GKE Gateway controller, Google Cloud’s implementation of the Gateway API. Over a year in the making, the GKE Gateway controller manages internal and external HTTP/S load balancing for a GKE cluster or a fleet of GKE clusters. The Gateway API provides multi-tenant sharing of load balancer infrastructure with centralized admin policy and control. Read more.Related ArticleThe evolution of Kubernetes networking with the GKE Gateway controllerThe Kubernetes Gateway API is now supported in Google Kubernetes Engine as the GKE Gateway controller for improved service networking.Read ArticleHow to transfer your data to Google CloudAny number of factors can motivate your need to move data into Google Cloud, including data center migration, machine learning, content storage and delivery, and backup and archival requirements. When moving data between locations, it’s important to think about reliability, predictability, scalability, security, and manageability. Google Cloud provides four major transfer solutions that meet these requirements across a variety of use cases. This cheat sheet helps you choose.Related ArticleHow to transfer your data to Google CloudYou’ve decided to migrate your data to the Google Cloud but where should you begin? What are the Google Cloud data transfer services avai…Read Article6 database trends to watchIn a data-driven, global, always-on world, databases are the engines that let businesses innovate and transform. As databases get more sophisticated and more organizations look for managed database services to handle infrastructure needs, there are a few key trends we’re seeing. Here’s what to watch.Related Article6 database trends to watchUsing managed cloud database services like Cloud SQL, Spanner, and more, can bring performance, scale, and more. See what’s next for mode…Read ArticleAll the posts from the weekEdTechs transform education with AI and Analytics6 database trends to watchThe modern web architecture jigsaw puzzle, made easy for youUsing TFX inference with Dataflow for large scale ML inference patternsThe evolution of Kubernetes networking with the GKE Gateway controller6 more reasons why GKE is the best Kubernetes serviceIntroducing Open Saves: Open-source cloud-native storage for gamesHow Anthos supports your multicloud needs from day oneRisk governance of digital transformation: guide for risk, compliance & audit teams4 simple steps to make the perfect spreadsheet to power your no-code appGo from Database to Dashboard with BigQuery and LookerGoogle’s research & data insights solution makes next-generation research accessibleAgent installation options for Google Cloud VMsHow to automate with AppSheet AutomationCreating safer cloud journeys with new security features and guidance for Google Cloud and WorkspaceGoogle Cloud announces new region to support growing customer base in IsraelHow capital markets can prepare for the future with AIHow to transfer your data to Google CloudSRE at Google: Our complete list of CRE life lessonsChoose the best way to use and authenticate service accounts on Google CloudGKE operations magic: From an alert to resolution in 5 stepsPartnering with NSF to advance networking innovationTurbocharge workloads with new multi-instance NVIDIA GPUs on GKESimplify your Chrome OS migration with Parallels DesktopHow to use multi-VPC networking in Google Cloud VMware EngineIntroducing new connectors for WorkflowsLa que nos une: Univision partners with Google Cloud to transform media experiencesSign here! Creating a policy contract with Configuration as DataBuild security into Google Cloud deployments with our updated security foundations blueprintHow Cloud Spanner helped Merpay easily scale to millions of usersSeven-Eleven Japan uses Google Cloud to serve up real-time data for fast business decisionsColgate-Palmolive moves to the cloud with Chrome Enterprise and Google Workspace
Quelle: Google Cloud Platform
Wir freuen uns, einen kostenlosen digitalen Kurs anzubieten: Optionen für AWS-Netzwerkkonnektivität. Der Kurs stellt Konzepte der Netzwerkkonnektivität vor, beschreibt Designmuster für Netzwerke und demonstriert, wie die Designmuster auf gängige Anwendungsfälle angewendet werden können. Dieser 150-minütige Kurs für Fortgeschrittene beinhaltet Lesemodule, Quizfragen zur Wissensabfrage und optionale praktische Übungen. Der Kurs eignet sich für Netzwerkingenieure, Unternehmensarchitekten, Infrastrukturarchitekten, Systemingenieure und Anwendungsarchitekten.
Quelle: aws.amazon.com

Wir verbinden uns per Satellit mit dem Internet und Tesla will mehr. Die Woche im Video. (Starlink, Tesla)
Quelle: Golem

Wegen vermehrten Onlineshoppings quellen die Blauen Tonnen über. Weil das offenbar ein unlösbares Problem ist, muss ich kriminell werden. Ein Feature von Achim Sawall (Onlineshop, Wirtschaft)
Quelle: Golem

In a data-driven, global, always-on world, databases are the engines that let businesses innovate and transform. As databases get more sophisticated and more organizations look for managed database services to handle infrastructure needs, there are a few key trends we’re seeing. Here’s what to watch.We’re looking forward to what’s next in databases. You can’t predict the future, but you can be prepared for it—join us at our Data Cloud Summit to learn and connect, on May 26, 2021.Related ArticleGoogle charts the course for a modern data cloudWhy Google Cloud is leading the operational database management systems (DBMS) market with an open, multi-cloud, enterprise-ready vision.Read Article
Quelle: Google Cloud Platform
Over the last year, COVID-19 presented unforeseen challenges for practically every type of business and organization—including schools, colleges, and universities. For educational institutions, the pandemic was an unapologetic agent of acceleration, shifting one billion learners from in-person to online learning within two months. The rapid transition to online learning exposed many schools’ lack of readiness for the new online learning environment. It also widened the learning equity gap for students, with fewer than 40% of students from low-income families having access to the tools required for remote learning.For those who do have online access, today’s students expect everything from engaging and collaborative digital learning experiences to skills-based training for their roles in the future workforce. Expectations are also high for 24×7 multi-channel tech support across all learning devices, applications, and platforms. In these remarkable times, education technology companies have an important role to play in supporting academic institutions and students. Indeed, this is already happening, as the EdTech (Educational Technology) market is nearly tripling, with total global expenditures expected to reach $404 billion by 2025. However, the success of these EdTech companies depends on their performance in a number of areas, including:Content and products: How quickly can they generate new content and react to learner needs with new products to additional markets for broader adoption?Personalization: How effectively can they leverage artificial intelligence (AI) to provide a personalized experience to all types of learners?Trust and security: How trusted and secure are their services when educational organizations are suffering the highest number of data breaches since 2005?Here are a few examples of how EdTech companies are successfully using AI and analytics to capture this opportunity and transform their businesses:Build better products: iSchoolConnect is an online platform that lets students explore schools, courses, and countries where they might study, and makes higher education admissions accessible to students around the globe. The company leverages AI services to help educational institutions optimize their academic operations by accelerating admission processing by greater than 90%, while saving significant costs.Launch in new markets faster: Classroom creativity tools provider Book Creator uses AI APIs to enhance accessibility and improve the learner experience. “The broad suite of intelligent APIs enables us to deliver richer experiences, faster and more easily, without having to be experts in machine learning, drawing recognition, map embeds, or other areas,” says VP of engineering Thom Leggett.Scale businesses securely: Using DevOps and CDN [content delivery network] services, Chrome browser recording extension creator Screencastify was able to support eight times growth in users overnight amid the COVID-19 pandemic, while maintaining consistent total cost of ownership. These technologies helped the company rapidly scale operations in response to the overnight increase in demand from consumers and assure student data privacy and security on a budget. “We know this is just the beginning, as more educators rely on technology to deliver richer, more interactive curricula to students,” says CEO James Francis. Provide personalized learning and support: Smart analytics and AI can provide personalized support and recommendations for students, forecast demand, and predict shifts in learners’ preferences. Online learning platform Mindvalley uses cloud-based tools to understand and make decisions based on user activity and leverage machine learning to predict behavior. Google Cloud is partnering with many of these leading EdTech companies, as well as industry-leading consortiums like Ed-Fi and Unizin, to standardize educational common data models and best practices for more agile and cost-effective integration of EdTech into existing environments.The education landscape is changing rapidly, and EdTech has a major role to play as institutions adapt to the massive shift in learners’ preferences and expectations. We’re committed to empowering EdTech companies with the tools and services they need to help expand learning for everyone, anywhere. Watch our Spotlight session with EdTechX to learn more.
Quelle: Google Cloud Platform