VW-Chef Diess: Volkswagen will eigenen Chip für seine Autos
Rund um einen eigenen Prozessor will Volkswagen das vollvernetzte und selbstlenkende Fahrzeug bauen – und es damit Tesla nachmachen. (VW, Technologie)
Quelle: Golem

Rund um einen eigenen Prozessor will Volkswagen das vollvernetzte und selbstlenkende Fahrzeug bauen – und es damit Tesla nachmachen. (VW, Technologie)
Quelle: Golem

Das Hochschulnetz versorgt tausende Schulen in Baden-Württemberg mit Lernplattform und Homepage. Jetzt will die Regierung den Stecker ziehen. (Schulen, Server)
Quelle: Golem

Der Wild One Max sieht aus wie ein RC-Spielzeug aus den 80-er Jahren – mit dem Unterschied, dass im neuen Elektroauto ein Mensch fahren kann. (Elektroauto, Technologie)
Quelle: Golem

Die Apple-Lücken in Webkit werden wohl bereits aktiv ausgenutzt. Das Unternehmen stellt Updates bereit. (iOS, Apple)
Quelle: Golem

Der ADAC hat günstige Wallboxen für Elektroautos getestet, die von Apps unterstützt werden. (Elektroauto, Technologie)
Quelle: Golem
The 5G mobile network is the latest global wireless standard developed by 3GPP. While 4G networks provide connectivity to most current cell phones, 5G can enable connectivity for an expanded set of devices, from machines to vehicles. In this post, we’ll share some advantages of 5G, provide an overview of edge computing and look at some potential use cases.
Quelle: CloudForms

Core to Google Cloud’s efforts to be the industry’s most Trusted Cloud is our belief in shared fate – taking an active stake to help customers achieve better security outcomes on our platforms. To make it easier to build security into deployments, we provide opinionated guidance for customers in the form of security blueprints. We recently released our updated Google Cloud security foundations guide and deployable blueprint to help our customers build security into their starting point on Google Cloud. Today, we’re adding to our portfolio of blueprints with the publication of our Protecting confidential data in AI Platform Notebooks blueprint guide and deployable blueprint, which can help you apply data governance and security policies that protect your AI Platform Notebooks containing confidential data.Security and privacy are particularly important when it comes to AI, because confidential data is often at the heart of AI and ML projects. This blog post focuses on securing the following high level notebook flow at all relevant security layers.AI Platform Notebooks offer an integrated and secure JupyterLab environment for enterprises. Data science practitioners in enterprises use AI Platform Notebooks to experiment, develop code, and deploy models. With a few clicks, you can easily get started with a Notebook running alongside popular deep learning frameworks (TensorFlow Enterprise, PyTorch, RAPIDS and many others). Today AI Platform Notebooks can be run on Deep Learning Virtual Machines or Deep Learning Containers.Enterprise customers, particularly those in highly regulated industries like financial services and healthcare and life sciences, may want to run their JupyterLab Notebooks in a secure perimeter, and control access to the notebooks and data. AI Platform Notebooks were built from the ground up with such customers in mind, with security and access control as the pillars of the service. Recently, we announced the general availability of several security features, including VPC Service Controls (VPC-SC), customer managed encryption keys (CMEK), and more for AI Platform Notebooks. However, security is more than just features; practices and processes are just as important. Let’s walk through the blueprint, which serves as a step-by-step guide to help secure your data and the Notebooks environment.AI Platform Notebooks support popular Google Cloud Platform enterprise security architectures through VPC-SC, shared VPC, and private IP controls. You can run a Shielded VM as your compute instance for AI Platform Notebooks, and encrypt your data on disk with CMEK. You can choose between two predefined user access modes to AI Platform Notebooks: single-user or via a service account. You can also customize access based on your Cloud Identity and Access Management (IAM) configuration. Let’s take a closer look at these security features in the context of AI Platform Notebooks.Compute Engine securityAI Platform Notebooks with Shielded VM supports a set of security controls that help defend against rootkits and bootkits. Available in Notebooks API and DLVM Debian 10 images, this functionality helps you protect enterprise workloads from threats like remote attacks, privilege escalation, and malicious insiders. This feature leverages advanced platform security capabilities such as secure and measured boot, a virtual trusted platform module (vTPM), UEFI firmware, and integrity monitoring. On a Shielded VM Notebook instance, Compute Engine enables the virtual Trusted Platform Module (vTPM) and integrity monitoring options by default. In addition to this functionality, Notebooks API provides an upgrade endpoint which allows you to perform operating system updates to the latest DLVM image, either manually or automatically via auto-upgrade.Data encryptionWhen you enable CMEK for an AI Platform Notebooks instance, the key that you designate, rather than a key managed by Google, is used to encrypt data on the boot and data disks of the VM. In general, CMEK is most useful if you need full control over the keys used to encrypt your data. With CMEK, you can manage your keys within Cloud KMS. For example, you can rotate or disable a key, or you can set up a rotation schedule using the Cloud KMS API.Data exfiltration mitigationVPC Service Controls (VPC-SC) improves your ability to mitigate the risk of data exfiltration from Google Cloud services such as Cloud Storage and BigQuery. AI Platform Notebooks supports VPC-SC, which prevents reading data from or copying data to a resource outside the perimeter using service operations, such as copying to a public Cloud Storage bucket using the “gsutil cp” command or to a permanent external BigQuery table using the “bq mk” command.Access control and audit loggingAI Platform Notebooks has a specific set of Identity and Access Management (IAM) roles. Each predefined role contains a set of permissions. When you add a new member to a project, you can use an IAM policy to give that member one or more IAM roles. Each IAM role contains permissions that grant the member access to specific resources. AI Platform Notebooks IAM permissions are used to manage Notebook instances; you can create, delete, and modify AI Platform Notebooks instances via Notebooks API. (To configure JupyterLab access, please refer to this troubleshooting resource.)AI Platform Notebooks writes Admin Activity audit logs, which record operations that modify the configuration or metadata of a resource.With these security features in mind, let’s take a look at a few use cases where AI Platform Notebooks can be particularly useful:Customers want the same security measures and controls they apply to their IT infrastructure applied to their data and notebook instances.Customers want uniform security policies that can be easily applied when their data science teams access data.Customers want to tune sensitive data access for specific individuals or teams, and prevent broader access to that data.AI Platform Notebook Security Best PracticesGoogle Cloud provides features and products that address security concerns at multiple layers including network, endpoint, application, data, and user access. Although every organization is unique, many of our customers have common requirements when it comes to securing their Cloud environments, including notebooks deployments. The new Protecting confidential data in AI Platform Notebooks blueprint guide can help you set up security controls and mitigate data exfiltration when using AI Platform Notebooks by: Helping you implement a set of best practices based on common customer inputs.Minimizing time to deployment by using a declarative configuration with Terraform.Allowing for reproducibility by leveraging the Google Cloud security foundations blueprint.The blueprint deploys the following architecture:The above diagram illustrates an architecture for implementing security with the following approach:Gather resources around common contexts as early as possible.Apply least-privilege principles when setting up authorization policies.Create network boundaries that only allow for necessary communications.Protect sensitive information at the data and software level.1. Gather resources around common contexts as early as possibleWith Google Cloud, you can gather resources that share a common theme using a resource hierarchy that you can customize. The Google Cloud security foundations blueprint sets a default organization’s hierarchy. The blueprint adds a folder and projects related to handling sensitive production data while using AI Platform Notebooks.A “trusted” folder under the “production” folder contains three projects organized according to its logical application:“trusted-kms” gathers resources such as keys and secrets that protect data.“trusted-data” gathers sensitive data.“trusted-analytics” gathers resources such as notebooks that access data.Grouping resources around a common context allows for high level resource management and provides the following advantages compared to setting rules at the resource level:Helps reduce the risk of security breach. You can apply security rules to a desired entity and propagate them to lower levels via policy inheritance across your data hierarchy.Ensure that administrators have to actively create bridges between resources. By default, projects are sandboxed environments of resources.Facilitate future organizational changes. Setting rules at a high level helps move groups of resources closer together.The blueprint does the following to facilitate the least-privileged approach to security:Sets specific policies at the trusted folder level.Creates identities and authorization roles at the project level.Reuses existing shared VPC environments and adds rules at a multiple-project level.2. Create network boundaries that only allow for necessary communications.Google Cloud provides VPCs for defining networks of resources. The previous sections cover the separation of functions through projects. VPCs belong to projects, so by default, resources from a VPC can not communicate with resources in another VPC.An administrator must now allow or block network communications:With the internet: Instances in Google can have internal and external IP addresses. The blueprint sets a default policy for forbidding the use of external IP addresses at the trusted folder level.With Google APIs: Without external IP addresses, instances cannot access the public endpoints of Cloud Storage and BigQuery. The blueprint sets private connectivity to Google APIs at the VPC level to allow notebooks communication with those services.Within boundaries: Limits environments such as BigQuery or Cloud Storage that notebooks have access to. The blueprint sets VPC Service Controls to create trusted perimeters, within which only resources in certain projects can access certain services based on access policies for user/device clients.Between resources: The blueprint creates notebooks using an existing shared VPC. The shared VPC should have restrictive firewall rules to limit the protocols that instances can use to communicate with each other.The blueprint uses Google Cloud’s network features to set the minimum required network paths as follows:Enables users to access Google Cloud endpoints through allowlisted devices.Allows for the creation of SSH tunnels for users to access notebook instances.Connects instances to Google services through private connections within an authorized perimeter.3. Apply least-privilege principles when setting up authorization policies.Google Cloud provides a default Cloud IAM setup to make the platform onboarding easier. For production environments, we recommend ignoring most of those default resources. Use Cloud IAM to create your custom identities and authorization rules based on your requirements. Google Cloud provides features to implement the least-privileged principle while setting up a separation of duties:Custom roles provide a way to group a minimum set of permissions for restricting access. This ensures that a role allows identities to only perform the tasks expected of them.Service accounts can represent an instance identity and act on behalf of trusted users. This allows for consistent behavior and limits user actions outside of those computing resources.Logical identity groups based on user persona simplifies management by limiting the number of lone and possibly forgotten identities.Cloud IAM policies link roles and identities. This provides users with the means to do their job while mitigating the risk of unauthorized actions.For example, the blueprint:Creates a service account with enough roles to run jobs and act as an identity for notebook instances in the trusted-analytics project.Assigns roles to a pre-created group of trusted scientists to allow them to use notebooks to interact with data.Creates a custom role in the trusted-data project with view-only access to sensitive information in BigQuery, without being allowed to modify or export the data.Binds the custom role to relevant user groups and services accounts so they can interact with data in the trusted-data project.Through Terraform, the blueprint creates the following flow:Add users from the trusted_scientists variable to the pre-created trusted-data-scientists Google Groups.Sets a policy for identities in the trusted-data-scientists group to use the service account sa_p_notebook_compute.Creates an individual notebook instance per trusted user and leverages the sa_p_notebook_compute service account as an identity for the instances.With this setup, users can access confidential data in the trusted-data project through the service account, which acts as an identity for instances in the trusted-analytics project. Note: All trusted users can access all confidential data. Setting narrower permissions is out of scope for this blueprint. Narrower permissions can be set by creating multiple service accounts and limiting their data access at the required level (a specific column, for example), then assigning each service account to the relevant group of identities.4. Protect sensitive information at the data and software level.Google Cloud provides default features to protect data at rest, and additional security features for creating a notebook.The blueprint encrypts data at rest using keys, and shows how to:Create highly available customer-manager keys in your own project.Limit key access to select identities.Use keys to protect data from BigQuery, Cloud Storage and AI Platform Notebooks in other projects within the relevant perimeter.For more details, see the key management section of the blueprint guide.AI Platform Notebooks leverage Jupyter notebooks set up on Compute Engine instances. When creating a notebook, the blueprint uses AI Platform Notebooks customization features to:Set additional security parameters, such as preventing “sudo”.Limit access to external sources when calling deployment scripts.Modify the Jupyter setup to mitigate the risk of file downloads from the Jupyterlab UI.For more details, see the AI Platform Notebooks security controls section of the blueprint guide.To learn more about protecting your confidential data while better enabling your data scientists, read the guide: Protecting confidential data in AI Platform Notebooks. We hope that this blueprint, as well as our ever-expanding portfolio of blueprints available on our Google Cloud security best practices center, helps you build security into your Google Cloud deployments from the start, and helps make you safer with Google.Related ArticleBuild security into Google Cloud deployments with our updated security foundations blueprintGet step by step guidance for creating a secured environment with Google Cloud with the security foundations guide and Terraform blueprin…Read Article
Quelle: Google Cloud Platform
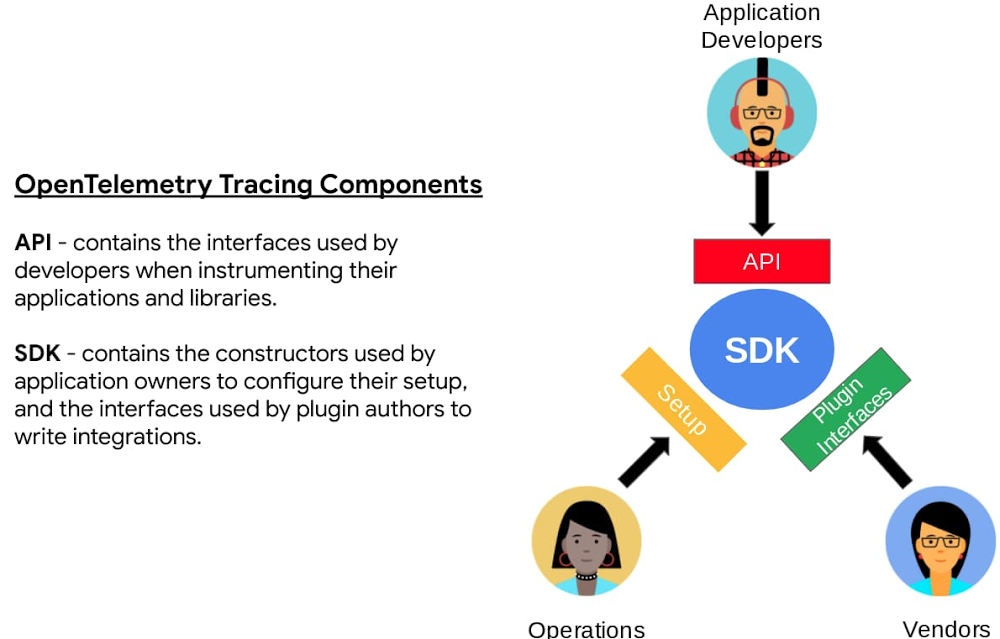
For decades, application development and operations teams have struggled with the best way to generate, collect, and analyze telemetry data from systems and apps. In 2010, we discussed our approach to telemetry and tracing in the Dapper papers, which eventually spawned the open-source OpenCensus project, which merged with OpenTracing to become OpenTelemetry. OpenTelemetry provides a single, open-source standard and a set of technologies to capture and export metrics, traces, and logs (in the future) from your applications and infrastructure. OpenTelemetry, which is now the second most active CNCF open-source project behind only Kubernetes, makes it easy to create and collect telemetry data from your services and software, then forward them to a variety of analysis tools. OpenTelemetry is 100% free and open source, and is adopted and supported by industry leaders in the observability space.OpenTelemetry has reached a key milestone: the OpenTelemetry Tracing Specification has reached version 1.0. API and SDK release candidates are available for Java, Erlang, Python, Go, Node.js, and .Net. Additional languages will follow over the next few weeks. Now that Trace has reached 1.0 status, customers can deploy OpenTelemetry Trace with confidence.Tracing stability is only the first step towards having one observability framework for trace, metrics, and logs. The top hyperscale cloud providers, application performance monitoring (APM), monitoring, logging and trace companies have partnered on OpenTelemetry to provide a unified, open-source approach that will greatly simplify the collection of telemetry data from any environment, including on-premises and multi-cloud, for all customers. One agent will work across all major hyperscale clouds, APM, logging, metrics, and trace products.How is Google using OpenTelemetry?At Google, respect and commitment to our users is always at the forefront of everything we do. To that end, we are fully embracing the OpenTelemetry standard to ensure that you get the best use of the information collected from any of our cloud-native products. We are working to implement OpenTelemetry libraries as out-of-the-box features in some of our most popular cloud products, for example the new Cloud SQL Insights. Insights provides database metrics and traces by honoring the propagated trace-id from the instrumented upstream application and appending spans that are representative of your query plan. These spans can be routed to your backend of choice via the Google Cloud Trace API. This makes it easy to do end-to-end tracing in your existing tools and provides a full-stack view of your environments from the application through to the database.OpenTelemetry, Google Cloud and our partnersWe believe that a healthy observability ecosystem serves our customers well and this is reflected in our continued commitment to open-source initiatives. Here are some of the partners who are fully supporting the OpenTelemetry rollout, which will enable them to build differentiated solutions for mutual customers. Cisco AppDynamics“AppDynamics is committed to OpenTelemetry standards to accelerate full-stack observability. Digital has an ever growing impact on our lives, and we believe the future is to make end-to-end telemetry gathering easier in order to enable a full view of the digital environment’s health and behavior.” – Abhi Madhugiri, Director, Global Strategic Alliances, Cisco AppDynamicsDatadog“As early contributors to OpenTelemetry, we are extremely pleased to see this major milestone and to work with customers instrumenting critical, production services. Bringing together end-to-end traces, metrics, and logs is necessary to make your applications, infrastructure, and third-party services entirely observable. With this 1.0 release for Tracing, Metrics and Logs on the horizon, OpenTelemetry holds incredible promise as an open, community-driven source of instrumentation for any engineering team.” – Michael Gerstenhaber, Sr Director of Product Management, DatadogDynatrace“As one of the core contributors to OpenTelemetry, Dynatrace sees great value collaborating on the open standard with other industry leaders to provide more visibility into cloud-native software stacks. Dynatrace combines OpenTelemetry and broad observability and user experience data, with automation and intelligence to help teams tame cloud-native environments, save time, and focus on activities that create customer value.” – Alois Reitbauer, VP, Chief Technology Strategist, DynatraceNew Relic“At New Relic, we strongly believe that the future of instrumentation is open and therefore we are glad to see the strong momentum behind OpenTelemetry. We are excited to continue contributing to the project as it marches towards GA as we are seeing rapidly growing demand for our OpenTelemetry solution among our customer base.” – Ramon Guiu, vice president of product management, New Relic.Splunk“Over the past two years, OpenTelemetry has grown from a proposal between two open-source communities to the north star for the collection of distributed traces and other signals. OpenTelemetry is championed by cloud platforms, has become the recommendation of many observability vendors to their customers, and now has the second highest number of contributors across all CNCF projects. Google and Splunk have been behind OpenTelemetry since day one, and the 1.0 release of tracing means that GCP and Splunk Observability Cloud customers can take advantage of OpenTelemetry’s broad set of integrations, powerful SDKs, and easy-to-use Collector, with a robust support path backing them up.” – Morgan McClean – co-founder of OpenCensus & OpenTelemetry and Director of Product Management, SplunkWhat’s next?We are excited to see the rollout of the other specifications from the OpenTelemetry community and will continue to work to enable integrations with our Google Cloud products. Our hope is that the broader developer community joins us in embracing this unique step change in collecting telemetry data. We are pleased to see the adoption and support of the committee by other leading cloud providers and observability vendors. Get started with OpenTelemetry todayTo learn more about OpenTelemetry, review the OpenTelemetry specification and start exporting traces to Google Cloud Trace.Related ArticleDatabase observability for developers: introducing Cloud SQL InsightsNew Insights tool helps developers quickly understand and resolve database performance issues on Cloud SQL.Read Article
Quelle: Google Cloud Platform
“Talk about tough times, right?”That’s how Dan Stuart, Senior Vice President of IT Services at Southwire Company, refers to the months following a December 2019 ransomware event, and the COVID crisis that began in spring of 2020. Those events hit just as the company was preparing for an overhaul of their SAP environment. This comprehensive plan included three key elements. First, the company wanted to upgrade their SAP ECC environment to take advantage of the latest functionality available for this critical ERP system. Second, Southwire aimed to deploy SAP Business Warehouse on SAP HANA to accelerate vital reporting for all business users. Third, the company wanted to upgrade to the latest version of SAP Process Orchestration—an essential component that touches key manufacturing interfaces in all Southwire facilities. Southwire had looked at multiple options for the upgrades, including remaining entirely on-premises, colocation, and full cloud migration. “Going to the cloud seemed a lot more compelling,” says Joe Schleupner, Southwire’s Senior Director of PMO & ITS planning and implementation. “We were going to the cloud eventually, so why take these intermediary steps? Let’s just get it done.”After looking at several options, Southwire decided to migrate to Google Cloud. “We wanted to be on a platform for SAP that was flexible, scalable, and secure; that we could count on to get up and running quickly,” says Stuart. “We chose Google Cloud not only for those reasons, but also because we recognize that Google has other assets that we may be able to take advantage of down the line, such as technologies like artificial intelligence (AI).” More stability, less worryAs one of the leading manufacturers of wire and cable used in the transmission and distribution of electricity, Southwire aids the delivery of power to millions of people worldwide. They have more than 30 manufacturing facilities across the United States running 24/7. Any downtime directly affects productivity and revenue. With help from Google Cloud and their implementation partner NIMBL, Southwire completed the SAP migration to Google Cloud over a planned maintenance weekend on July 4th.The migration itself, while complex, went quickly and smoothly. “Just moving to the cloud was quite a feat because we were dealing with so much data, but in total the SAP system was down for only ~16 hours,” says Schleupner.“As a project manager, I always felt that Google Cloud had my back” Schleupner says. The Process Orchestration (PO) migration was of particular concern, considering that it controlled all of Southwire’s manufacturing interfaces across the entire company. “Every critical piece of information that goes from SAP down to the manufacturing system goes through that system,” says Schleupner.Even after migrating, Southwire discovered that making changes to the system was fast, easy, and resulted in no downtime. Normally, certain types of changes would have involved taking down SAP for at least an hour.The Southwire team also appreciates the fact that the modern cloud architecture means spending less time on routine infrastructure maintenance. “It’s one less thing for me to worry about,” Stuart says, “I can focus on the business side of the house and move the technology and responsibilities to what we do within the Google Cloud Platform.”What comes next?While the cloud migration will increase stability, uptime, performance, and security, there is much more to come. Southwire is currently working on a disaster recovery implementation for their SAP environment on Google Cloud. Stuart and Schleupner are excited about where Google Cloud can further take Southwire. They are considering an SAP Hybris e-commerce implementation as well as connected factory and/or factory automation initiatives that can take advantage of artificial intelligence and machine learning. To Stuart and Schleupner,the migration of Southwire’s SAP environment to Google Cloud, as important as it was, really represents the first step in the company’s tech evolution. Now that much of the heavy lifting is complete, Southwire’s digital transformation can begin in earnest. “There’s no shortage of areas where I think Google Cloud will come into play,” Stuart says, “and we intend to look at these things with an open mind to understand how we can leverage current investments to take our organization where we want to go.”Learn more about Southwire’s SAP on Google Cloud deploymentand how Google Cloud can transform the way you work with your SAP enterprise applications. Visit cloud.google.com/solutions/sap.Related ArticleSAP on Google Cloud: 2 analyst studies reveal quantifiable business benefits and ROIFrom uptime and infrastructure to efficiency and productivity—both Forrester and IDC identified major benefits to companies that have mad…Read Article
Quelle: Google Cloud Platform
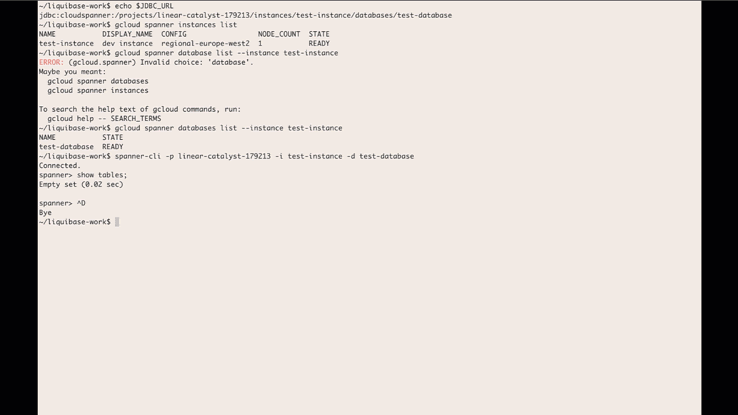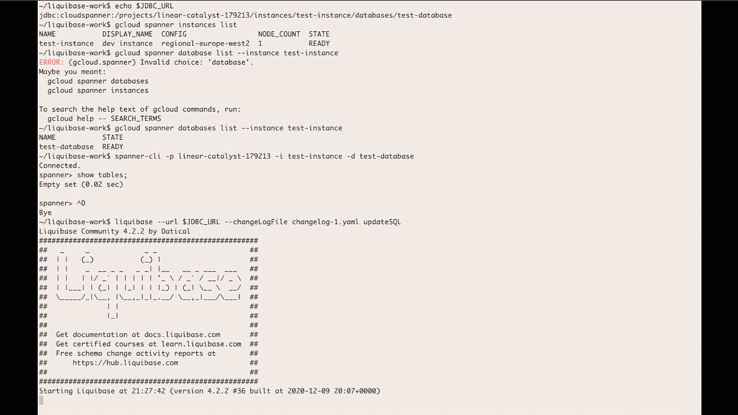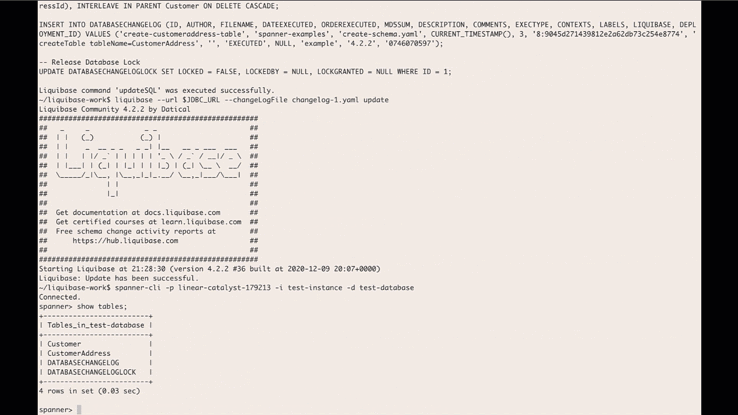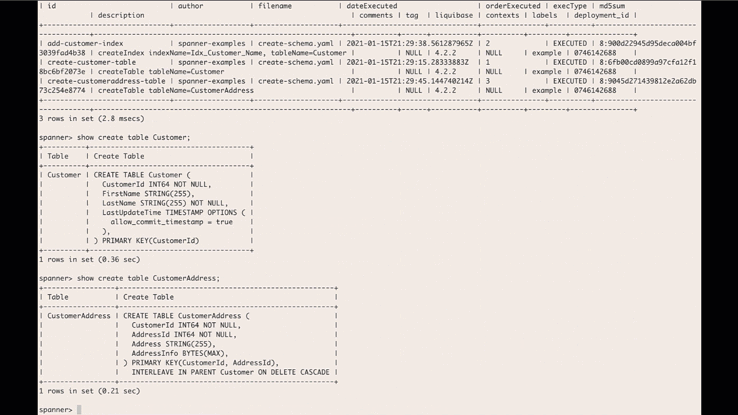
In February, we announced the beta version of the Liquibase Cloud Spanner extension that allows developers to use Liquibase’s open-source database library to manage and automate schema changes in Cloud Spanner. We’re happy to share that the Liquibase Cloud Spanner extension is now GA.What is Liquibase?Liquibase, an open-source library that works with a wide variety of databases, can be used for tracking, managing, and automating database schema changes. By providing the ability to integrate databases into your CI/CD process, Liquibase helps you more fully adopt DevOps practices. It supports SQL as well as declarative formats such as XML, YAML, and JSON. Liquibase includes support for reviewing changes before applying them, incrementally applying needed changes to different databases in different environments, and rolling back changes.When you use Liquibase, every database schema change you make is called a changeset, and all of the changesets are tracked in changelogs. These changesets and changelogs make it possible to do version control on your database and make it easier to integrate database schema migrations with your CI/CD process.What are the supported features of the Liquibase Cloud Spanner extension?The Cloud Spanner Liquibase extension allows you to use Liquibase to target Cloud Spanner databases. The extension supports most of the available features of both Liquibase and Cloud Spanner and supports most DML and DDL commands. The following Liquibase ChangeTypes are supported by the extension:createTable, dropTable, addColumn, modifyDataType, addNotNullConstraint, dropColumn, createIndex, dropIndex, addForeignKeyConstraint, dropForeignKeyConstraint, dropAllForeignKeyConstraints, addLookupTableThe following data DML ChangeTypes are supported by the extension:insert, update, loadData, loadUpdateDataBest practices and limitationsWhile the Cloud Spanner Liquibase extension supports as many of the features of Cloud Spanner and Liquibase as possible, there are some features that cannot be supported or can only be supported through custom SQL changes. To use Liquibase effectively with Spanner, review this summary of best practices and limitations. See this page for the full list of limitations.Use ModifySql commands for Cloud Spanner features without a corresponding Liquibase change typeThere are some Cloud Spanner features that don’t have a corresponding change type in Liquibase. Support for these features can be accomplished by adding a ModifySql command to your change set to modify the generated SQL.DDL limits and best practices for schema updatesCloud Spanner recommends some best practices for schema updates including limiting the frequency of schema updates and considering the impact of large scale schema changes. One approach is to apply a small number of change sets. Alternatively, you can use SQL change and batch the DDL using batch statements.Liquibase change types with limited or no Cloud Spanner supportThere are some change types that Liquibase supports that either aren’t supported by Cloud Spanner or have certain limitations. For example, addPrimaryKey and dropPrimaryKey are not supported, because Cloud Spanner requires all tables to have a primary key. The primary key has to be defined when the table is created, and can’t be added or dropped later.For a full list of these change types and potential workarounds, see this section of the documentation.Database features that aren’t supported by Cloud SpannerThere are some database features that are not supported by Spanner. If you try to use any of the following through Liquibase, an error will occur:Auto increment columnsSequencesDefault value definition for a columnUnique constraints (use UNIQUE INDEX instead)Stored proceduresViewsTable and column remarksHow to get startedUsing Cloud Spanner and Liquibase together allows you to integrate database schema migrations in your CI/CD pipelines. If you’re ready to try out the Cloud Spanner Liquibase extension for yourself, download the latest release here. Then, head over to the Liquibase with Cloud Spanner integration guide, which will walk you through how to create a changelog, how to run the changelog with Liquibase, and how to verify the changes. You can use the Liquibase extension with your actual Spanner instances or with the emulator.For even more information and additional changelog examples, visit the liquibase-spanner GitHub repository. We would love to hear your feedback, so please share any suggestions, issues, or questions in the issue tracker.Related ArticleOpening the door to more dev tools for Cloud SpannerLearn how to integrate a graphical database development tool with cloud databases like Cloud Spanner with the JDBC driver.Read Article
Quelle: Google Cloud Platform