Power Delivery: USB-C soll bald mit 240 Watt laden
Bisher war bei 100 Watt offiziell Schluss, künftig könnten sogar flotte Gaming-Notebooks mit USB Power Delivery betrieben werden. (USB PD, Notebook)
Quelle: Golem

Bisher war bei 100 Watt offiziell Schluss, künftig könnten sogar flotte Gaming-Notebooks mit USB Power Delivery betrieben werden. (USB PD, Notebook)
Quelle: Golem

Das kleine Display aus 5760 Micro-LEDs lässt sich nicht nur dehnen, sondern auch verdrehen und in andere Formen bringen. (Display, OLED)
Quelle: Golem

Der Basispreis für den Volkswagen ID.3 steigt. Wer noch etwas mehr zahlt, kann eine höhere Ladeleistung als bisher erhalten. (Volkswagen ID., Technologie)
Quelle: Golem
Digitalizing key business processes can be mission critical. But for many businesses, the pandemic slowed progress on key digital transformation initiatives. If your business depends on traditional SAP environments, delays are particularly problematic given the 2027 deadline for migration to SAP HANA or SAP S/4HANA.
Quelle: CloudForms
As a Product Manager at Red Hat, I speak with customers to understand the challenges they seek to address and recommend Red Hat technologies that can help maximize efficiency and productivity in their environments.
Quelle: CloudForms

The home lending journey entails processing an immense number of documents daily from hundreds of thousands of borrowers. Currently, home lending document processing relies on some outdated digital models and a high dependency on manual labor, resulting in slow processing times and higher origination costs. Scaling a business that sorts through millions of documents daily, while increasing efficacy and accuracy, is no small feat. When it comes to applying for a mortgage loan, consumers expect a digital experience that’s as good as the in-person one. Roostify simplifies the home lending journey for lenders and their customers.No time to spare: Overcoming document processing challenges with AIRoostify provides enterprise cloud applications for mortgage and home lenders. In order to empower its customers to deliver a better, more personalized lending experience, they needed to automate and scale their in-house document parsing functionality.As a key component of its document intelligence service, Roostify is leveraging Google Cloud’s Lending DocAI machine learning platform to automate processing documents required during a home loan application process, such as tax returns or bank statements with multi-language support. This partnership delivers data capture at scale, enabling Roostify customers to automatically identify document types from the uploaded file and to extract relevant entities such as wages, tax liabilities, names, and ID numbers for further processing, and make things move faster in the cumbersome lending process. Roostify’s solutions leverage Google Cloud’s Lending DocAI, which is built on the recently announced Document AI platform, a unified console for document processing. Customers can easily create and customize all the specialized parsers (e.g., mortgage lending documents and tax returns parsers) on the platform without the need to perform additional data mapping or training. All Google Cloud’s specialized parsers are fine-tuned to achieve industry-leading accuracy, helping customers and partners confidently unlock insights from documents with machine learning. Learn more about the solution from the GA launch blog and the overview video.Integrating Lending DocAI’s intelligent document processing capabilities into the Roostify platform means more innovation for their customers and tangible results: faster loan processing times, fewer document intake errors, and lower origination costs. Additional support in Google Lending DAI for other languages and more documents like global Know Your Customer (KYC) documents or payroll reports is in the near future.Full integration of AI solutionsWorking together with Roostify’s platform team, we were able to help them solve their document processing challenge through integration of various GCP products such as Lending DocAI (LDAI), Data Loss Prevention (DLP) for redacting sensitive data, BigQuery for data warehousing and analytics, and Firestore for API status. To make it very safe and secure, all data was encrypted end-to-end at Rest and in Transit. LDAI won’t require any training data to process. It is an easy plug and play API.Here is a sneak peek in the high level deployment architecture for LDAI in Roostify environment:Here are the steps for processing data:Receives document processing request from the client.API Function directs requests to the pre-processing service. For Async requests a processing ID is generated and returned to the caller.Pre-processing service sends the request for further processing (Long/short PDF conversion), calling other microservices and receives back the responses. Any error in the response received is then sent to the response processing service. If the response is synchronous, the pre-processing service directs it to the LDAI Invoker service. If the response is asynchronous, the pre-processing service feeds it into the Cloud Pub/Sub service.Cloud Pub/Sub service feeds the response back to the LDAI Invoker service.LDAI Invoker service routes the request to the Google LDAI API for classification if there are multiple pages in the document.Document will be split based on LDAI response and then saved in a GCS bucket for temporary storage.LDAI entity interface for single page processing and then LDAI Invoker sends LDAI results to LDAI Response ProcessingIf a request is a synchronous request the LDAI Response Processor sends results to the API Function so that it can complete the synchronous call and respond to the rConnect caller.If the request is an asynchronous request the LDAI Response Processor will respond to the caller’s webhook and complete the transaction.Finally, Data stored in the GCP bucket will be deleted.All the responses that come from the LDAI API can optionally feed into BigQuery via the Response Processor, after parsing it through Data Loss Prevention (DLP) API to redact the PII/sensitive information. Throughout the processing of both asynchronous and synchronous requests all transactions are logged using Cloud Logging. For asynchronous transactions, the state is maintained throughout the process using Cloud Firestore.Roostify currently uses this technology to power two different solutions: Roostify Document Intelligence and Roostify Beyond™. Roostify Document Intelligence is a real-time document capture, classification, and data extraction solution built for home lenders. It ingests documents uploaded by borrowers and loan officers, identifies the relevant documents, and extracts and classifies key information. Roostify Document Intelligence is available as a standalone API service to any home lender with any digital lending infrastructure already in place. Roostify Beyond™ is a robust suite of AI-powered solutions that enables home lenders to create intelligent experiences from start to close. It combines powerful data, insightful analytics, and meaningful visualization to streamline the underwriting process. Roostify Beyond™ is currently available only to Roostify customers as part of an Early Adopter program and will be rolled out to the market later this year.Lenders can set the desired field confidence level. An extracted field that does not meet the set field confidence will display a warning indicator to borrowers asking them to validate the uploaded document.If the Beyond algorithms aren’t sure about the document (i.e., with lower confidence in the classification result than that set by the admin), the user sees a message asking them to validate the task.Through this partnership, Roostify has enabled its customers to adopt a data-first approach to their home lending processes, which will lead to improved user experiences and significantly reduced loan processing times.Fast track end-to-end deployment with Google Cloud AI Services (AIS)Google AIS (Professional Services Organization), in collaboration with our partner Quantiphi, helped Roostify deploy this system into production and fast-tracked the development multifold to generate the final business value.The partnership between Google Cloud and Roostify is just one of the latest examples of how we’re providing AI-powered solutions to solve business problems.Related ArticleLending DocAI fast tracks the home loan processLending DocAI fast tracks the home loan process for borrowers and lendersRead Article
Quelle: Google Cloud Platform
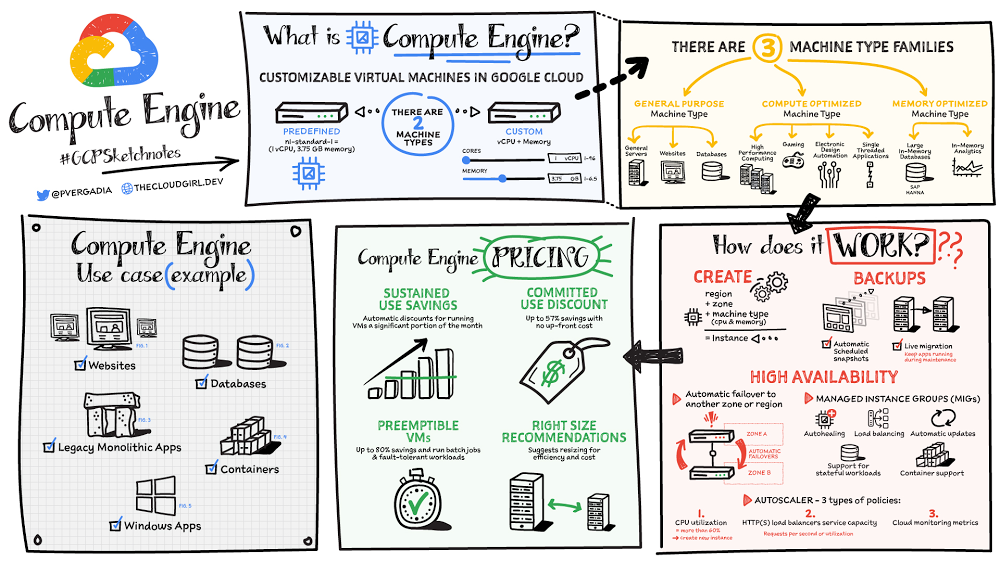
Compute Engine is a customizable compute service that lets you create and run virtual machines on Google’s infrastructure. You can create a Virtual Machine (VM) that fits your needs. Predefined machine types are pre-built and ready-to-go configurations of VMs with specific amounts of vCPU and memory to start running apps quickly. With Custom Machine Types, you can create virtual machines with the optimal amount of CPU and memory for your workloads. This allows you to tailor your infrastructure to your workload. If requirements change, using the stop/start feature you can move your workload to a smaller or larger Custom Machine Type instance, or to a predefined configuration.Click to enlargeMachine typesIn Compute Engine, machine types are grouped and curated by families for different workloads. You can choose from general-purpose, memory-optimized, compute-optimized and accelerator-optimized families. General-purpose machines are used for Day-to-day computing at a lower cost and for balanced price/performance across a wide range of VM shapes. The use cases that best fit here are web serving, app serving, back office applications, databases, cache, media-streaming, microservices, virtual desktops, development environments.Memory-Optimized machine are recommended for ultra high-memory workloads such as in-memory analytics and large in-memory databases such as SAP HANA Compute-Optimized machines are recommended for ultra high performance workloads such as High Performance Computing (HPC), Electronic Design Automation (EDA), gaming, video transcoding, single-threaded applications.Accelerator-Optimized machines are optimized for high performance computing workloads such as Machine learning (ML), Massive parallelized computations and High Performance Computing (HPC)How does it work?You can create a VM instance using a boot disk image, a boot disk snapshot, or a container image. The image can be a public operating system (OS) image or a custom one. Depending on where your users are you can define the zone you want the virtual machine to be created in. By default all traffic from the internet is blocked by the firewall and you can enable the HTTP(s) traffic if needed. Use snapshot schedules (hourly, daily, or weekly) as a best practice to back up your Compute Engine workloads. Compute Engine offers live migration by default to keep your virtual machine instances running even when software or hardware update occurs. Your running instances are migrated to another host in the same zone instead of requiring your VMs to be rebooted. AvailabilityFor High Availability (HA) Compute Engine offers automatic failover to other regions or zones in event of a failure. Managed instance groups (MIGs) help keep the instances running by automatically replicating instances from a predefined image. They also provide application based autohealing health checks. If an application is not responding on a VM, the auto healer automatically recreates that VM for you. Regional MIGs let you spread app load across multiple zones. This replication protects against zonal failures. MIGs work with load balancing services to distribute traffic across all of the instances in the group. Compute Engine offers autoscaling to automatically add or remove VM instances from a managed instance group based on increases or decreases in load. Autoscaling lets your apps gracefully handle increases in traffic, and it reduces cost when the need for resources is lower. You define the autoscaling policy for automatic scaling based on the measured load, CPU utilization, requests per second or other metrics.Active Assist’s new feature, predictive autoscaling, helps improve response times for your applications–When you enable predictive autoscaling, Compute Engine forecasts future load based on your Managed Instance Group’s (MIG) history and scales it out in advance of predicted load, so that new instances are ready to serve when the load arrives. Without predictive autoscaling, an autoscaler can only scale a group reactively, based on observed changes in load in real time. With predictive autoscaling enabled, the autoscaler works with real-time data as well as with historical data to cover both the current and forecasted load. That makes predictive autoscaling ideal for those apps with long initialization times and whose workloads vary predictably with daily or weekly cycles. For more information, see How predictive autoscaling works or check if predictive autoscaling is suitable for your workload, and to learn more about other intelligent features, check out Active Assist.PricingYou pay for what you use. But you can save cost by taking advantage of some discounts! Sustained use saving are automatic discounts applied for running instances for a significant portion of the month. If you know your usage upfront, you can take advantage of committed use discounts which can lead up to significant savings without any upfront cost. And by using short lived preemptive instances you can save up to 80%, they are great for batch jobs and fault tolerant workloads. You can also optimize resource utilization with automatic recommendations. For example if you are using a bigger instance for a workload that can run on a smaller instance you can save costs applying these recommendations.SecurityCompute Engine provides you default hardware security. Using Identity and Access Management (IAM)you just have to ensure that proper permissions are given to control access to your VM resources. All the other basic security principles apply, if the resources are not related and don’t require network communication amongst themselves, consider hosting them on different VPC networks. By default, users in a project can create persistent disks or copy images using any of the public images or any images that project members can access through IAM roles. You may want to restrict your project members so that they can create boot disks only from images that contain approved software that meet your policy or security requirements. You can define an organization policy that only allows Compute Engine VMs to be created from approved images. This can be done by using the Trusted Images Policy to enforce images that can be used in your organization. By default all VM families are Shielded VMs. Shielded VMs are virtual machine instances that are hardened with a set of easily configurable security features to ensure that when your VM boots, it’s running a verified bootloader and kernel — is the default for everyone using Compute Engine, at no additional charge. For more details on Shielded VMs refer to the documentation here.For additional security, you also have the option to use Confidential VM to encrypt your data in use, while it’s being processed in Compute Engine. For more details on Confidential VM refer to the documentation here.Use casesThere are many use cases Compute Engine can serve in addition to running websites and databases. You can also migrate your existing systems onto Google Cloud, with Migrate for Compute Engine, enabling you to run stateful workloads in the cloud within minutes rather than days or weeks. Windows, Oracle or VMware applications have solution sets enabling a smooth transition to Google Cloud. To run windows applications either bring your own license leveraging Sole-tenant nodes or using the included licenced images. ConclusionWhatever your application use case may be, from legacy enterprise applications to digital native applications, Compute Engine’s families will fit it. For a more in-depth look into Compute Engine check out the documentation. For more #GCPSketchnote, follow the GitHub repo. For similar cloud content follow me on Twitter @pvergadia and keep an eye out on thecloudgirl.devRelated ArticleHow does Anthos simplify hybrid & multicloud deployments?If you’re an enterprise, chances are you have networking, storage, and compute on multiple clouds and in your own data center. How can yo…Read Article
Quelle: Google Cloud Platform

With so much data at our fingertips, many organizations are utilizing machine learning to generate insightful predictions and improve their apps. But most teams have varying levels of machine learning expertise, ranging from novice all the way to experts. To accelerate AI innovation, you need a platform that can help you build expertise for those novice users, and provide a flexible environment for those experts. This is where Vertex AI comes in. Announced last week, Vertex AI unifies Google Cloud’s existing ML offerings into a single environment for efficiently building and managing the lifecycle of ML projects. It provides tools for every step of the machine learning workflow across different model types, for varying levels of machine learning expertise.In this video, we’ll show how Vertex AI supports your entire ML workflow—from data management all the way to predictions.If you enjoyed this video, keep an eye out for more AI Simplified episodes where we’ll dive much deeper into Vertex AI, including managing different datasets and building end-to-end machine learning workflows.
Quelle: Google Cloud Platform

A few months ago, we wrote about how the first step to implementing Site Reliability Engineering (SRE) in an organization is getting leadership on board. So, let’s assume that you’ve gone ahead and done that. Now what? What are some concrete steps you can take to get the SRE ball rolling? In this blog post, we’ll take a look at what you as an IT leader can do to fast-track SRE within your team. Step 1: Start small and iterate “Rome wasn’t built in a day,” the saying goes, but you do need to start somewhere. When it comes to implementing SRE principles, the approach that I (and my team) found to be the most effective is to start with a proof of concept, learn from our mistakes, and iterate!Start by identifying a relevant application and/or team There are many factors that go into choosing a specific team or application for your SRE proof of concept. Most of the time, though, this is a strategic decision for the organization, which is outside the scope of this article. Possible candidates can be a team shifting from traditional operations or DevOps to SRE, or a need to increase reliability to a business-critical product. No matter the reason, it’s crucial to select an application that is:Critical to the business. Your customers should care deeply about its uptime and reliability. Currently in development. Pick an application in which the business is actively investing resources. In a perfect world, the application provides data and metrics regarding its behaviour. Conversely, stay away from proprietary software. If the application wasn’t built by you, it’s not a good candidate for SRE! You need the ability to make strategic decisions about—and engineering changes to—the application as needed. Pro tip: In general, if you have workloads both on-premises and in the cloud, try to start with the cloud-based app. If your engineers come from a traditional operations environment, changing their thinking away from ‘bare metal’ and infrastructure metrics will be easier for a cloud-based app, as managed infrastructure turns practitioners into users and forces them to consume it like developers (APIs, infrastructure as code, etc.)Remember: Set realistic goals. Discouraging your team with unrealistic expectations early on will have a negative effect on the initiative. Step 2: Empower your teamsImplementing SRE principles requires fostering a learning culture, and in that regard, team enablement means both training them, i.e., in regards to knowledge, as well as empowering them.Building a training program is a topic in and of itself, but it’s important to think about an enablement strategy at an early stage. Especially in large organizations, you need to address topics like internal upskilling, hiring and scaling the team as well as onboarding and creating a learning community. Your enablement strategy should also accommodate employees at different levels and in different functions. For example, higher leadership’s training will look very different from practitioners’ training. Leadership’s education should be sufficient to get buy-in and to be able to make organizational decisions. To drive change in the entire organization, additional training to leadership on cultural concepts and practices might be required.Related ArticleRead ArticleWhen it comes to engineering leadership and/or middle management (managers that manage managers), training should be a combination of high-level cultural concepts to help foster the required culture, and technical SRE practices that are deep enough to understand prioritization, resource allocation, process creation, and future needs.When it comes to practitioners, ideally you want the entire organization to be aligned both from a knowledge perspective as well as culturally. But as we’ve mentioned earlier, it’s best to start simple, with just one team.The starting point for those teams should be to understand reliability and key concepts like SLAs, SLOs, SLIs and error budgets. These are important because SRE is focused on the customer experience. Measuring whether systems meet customer expectations requires a shift in mindset and can take time.Related ArticleRead ArticleAfter identifying your first application and/or the team responsible for it, it’s time to identify the app’s user journeys, the set of interactions a user has with a service to achieve a single goal—for example, a single click or a multi-step pipeline, and rank them according to business impact. The most critical ones are called Critical User Journeys (CUJ), and these are where you should start drafting SLO/SLIs.Pro tip: There are some general technical practices that can help you embrace SRE faster. For example, using less repos rather than more can help you reduce silos within the organization and better utilize resources. Likewise, prioritizing automatic processes and self-healing systems can benefit reliability, but also team satisfaction, helping the organization retain talent.Related ArticleRead ArticleFinal note: Similar to the way that you make architecture decisions, your chosen technology, solutions and implementation tools should enable you to do what you are trying to do and not vice versa. Step 3: Scale those learnings After you establish these SRE practices with one or a few teams, the next step is to think about building an SRE community and formalized processes across the organization. In some organizations, you can do this in parallel to the end of step 2, and in some organizations, only after you have a few successful implementations under your belt.In this phase, you’ll probably want to address community, culture, enablement and processes. You will need to address them all, especially as they are intertwined, but which one you prioritize will depend on your organization.Creating an SRE community in the organization is important both from a learning perspective, but also to establish a knowledge base of best practices, train subject-matter experts, help create needed guardrails, and align processes. Building a community goes hand in hand with fostering an empowered culture and training teams. The idea is that early adopters are ambassadors for SRE who share their learnings and train other teams in the organization. It is also useful to identify potential ambassadors or champions in individual development teams who are passionate about SRE and will help with the adoption of those practices.It is also crucial to create repeatable trainings for each functional role, including onboarding sessions. Onboarding new team members is a critical aspect of training and fostering an empowered SRE culture. Therefore it is vital to be mindful about your onboarding process and make sure that the knowledge is not lost when team members change roles.Related ArticleRead ArticleDuring this phase, you also want to foster an org-wide culture that promotes psychological safety, accepts failure as normal and enables the team to learn from mistakes. For that, leadership must model the desired culture and promote transparency. Finally, having structured and formalized processes can help reduce the stress around emergency response—especially being on-call. Processes can also provide clarity and make teams more collaborative and effective. In order to have the most impact, start by prioritizing the most painful areas under your team’s remit—for example, clean up noisy alerts to avoid (or address) alert fatigue, automate your change management processes and involve only the necessary people to save team bandwidth. Team members shouldn’t work on software engineering projects while doing on-call incident management, and vice-versa. Make sure they have enough bandwidth to do both, separately. Similar to other areas, you want to use data to drive your decisions. As such, identify where your teams spend the most time, and for how long. If you find that it is challenging to collect this kind of data, be it quantitative or qualitative, a good starting point is often your emergency response processes, as those have a direct impact on the business, especially around the escalation process, incident management and related policies. Pro tip: All the above practices contribute to reducing silos and align goals across the organization; those should include also your vendors and engineering partners. To that end, make sure your contracts with them capture those goals as well.Step 4: Embody a data-driven mindsetStarting the SRE journey can take time, even if you’re just implementing it for one team. Two quick wins that you can start with that will make a positive impact are collecting data and doing blameless postmortems.In SRE we try to be as data-driven as possible, so creating a measurement culture in your organization is crucial. When prioritizing data collection, ideally look for data that represents the customer experience. Collecting that data will help you identify your gaps and help you prioritize according to business needs and by extension your customer expectations.Related ArticleRead ArticleAnother thing that you can do is run or improve postmortems, which are an essential way of learning from failure and fostering a strong SRE culture. From our experience, even organizations that do run postmortems can benefit from them much more with a few minor improvements. It is important to remember that postmortems should be blameless in order to make the team feel safe to share and learn from failures. And to make tomorrow better than today, i.e., not repeat the same problems, it’s important that postmortems include action items and are assigned to an owner. Creating a shared repository for postmortems can have a tremendous impact on the team: it increases transparency, reduces silos, and contributes to the learning culture. It also shows the team that the organization “practices what it preaches.” Implementing a repository can be as easy as creating a shared drive.Pro tip: Postmortems should be blameless and actionable.Related ArticleRead ArticleOn the SRE fast trackOf course, no two organizations are alike, and no two SRE teams are either. But by following these steps, you can help get your team on the path to SRE success faster. To learn more about developing an effective SRE practice, check out the following resources. Collection of SRE Public resourcesGoogle Professional Services SRE packagesRelated ArticleWith SRE, failing to plan is planning to failThe process of becoming a successful Site Reliability Engineering shop starts well before you take your first class or read your first ma…Read Article
Quelle: Google Cloud Platform

Was am 25. Mai 2021 neben den großen Meldungen sonst noch passiert ist, in aller Kürze. (Kurznews, Google)
Quelle: Golem