MG Cyberster: MG B Roadster mit Lasergürtel und Union Jack
Der MG Cyberster soll als futuristisches Elektroauto das Erbe des legendären MG B Roadsters antreten. (Elektroauto, Technologie)
Quelle: Golem

Der MG Cyberster soll als futuristisches Elektroauto das Erbe des legendären MG B Roadsters antreten. (Elektroauto, Technologie)
Quelle: Golem

Das Betriebsrätegesetz soll an die Digitalisierung angepasst werden und Mitspracherechte beim Einsatz künstlicher Intelligenz und beim Homeoffice enthalten. (Homeoffice, KI)
Quelle: Golem

Kaum ein Genre hat sich so radikal weiterentwickelt: Golem.de stellt Kartenspiele für alle Plattformen vor – mit Faustkämpfen und Dämonen. Von Rainer Sigl (Hearthstone, Spieletest)
Quelle: Golem
We are pleased to announce that Red Hat Satellite 6.8.5 is generally available as of April 1, 2021.
Quelle: CloudForms

The Friday Five is a weekly Red Hat® blog post with 5 of the week’s top news items and ideas from or about Red Hat and the technology industry. Consider it your weekly digest of things that caught our eye.
Quelle: CloudForms
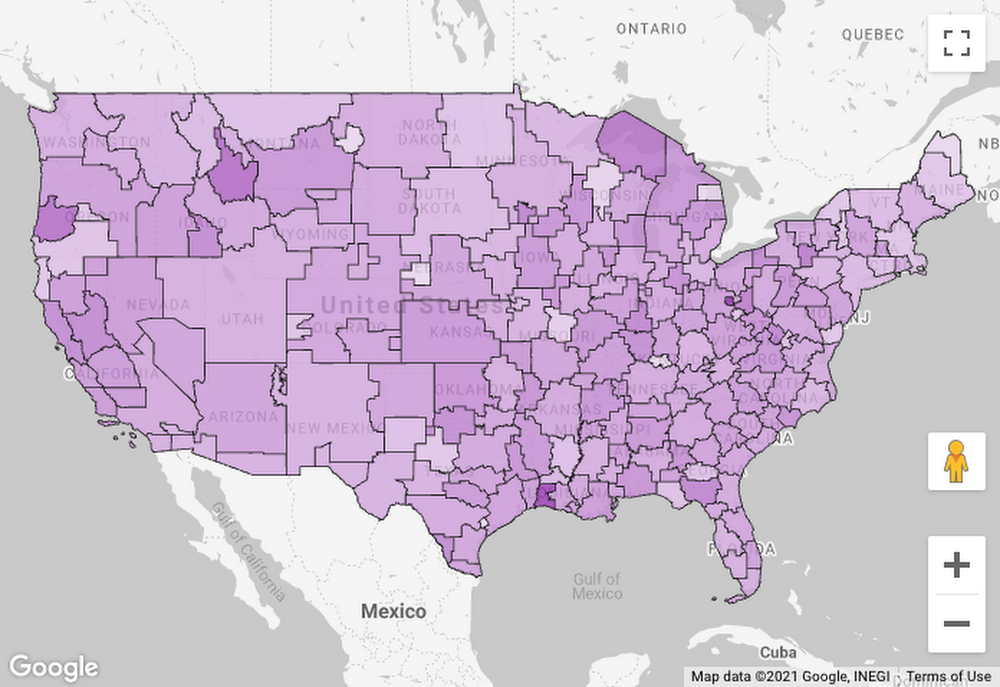
Chances are, your data contains information about geographic locations in some form, whether it’s addresses, postal codes, GPS coordinates, or regions that are meaningful to your business. Are you putting this data to work to understand your key metrics from every angle? In the past, you might’ve needed specialized Geographic Information System (GIS) software, but today, these capabilities are built into Google BigQuery. You can store locations, routes, and boundaries with geospatial data types and manipulate them with geospatial functions. Ultimately, helping people explore this data and spot geospatial patterns requires visualizing it on a map. To that end, we’re excited to announce new enhancements to Data Studio, including support for choropleth maps of BigQuery GEOGRAPHY polygons, so you can easily visualize BigQuery GIS data in a Google Maps-based interface.Google Maps in Data StudioData Studio is a no-cost, self-serve reporting and data visualization service from Google Marketing Platform that connects to BigQuery and hundreds of other data sources. With it, you can visually explore your data and design and share beautiful, interactive reports. With the addition in the past year of a Google Maps-based visualization, you can visualize and interact with your geographic data just as you do with Google Maps: pan around, zoom in, even pop into Street View.Don’t have geographic coordinates in your data? No problem: Data Studio recognizes countries, states/provinces, Designated Market Areas (DMAs), cities, postal codes, addresses, and other supported geographic field types. For example, even if all you have are DMA codes and metrics from Google Ads, you can visualize click-through rate by DMA:Click-through rate by Designated Market AreaVisualize BigQuery GEOGRAPHY polygonsBut what if you want to visualize boundaries beyond the most commonly used ones? What if there are different boundaries that are important in your industry or business? What if you’ve done an analysis that groups locations into clusters and drawn boundaries around them?With support for BigQuery GEOGRAPHY polygons in Data Studio, you can now visualize arbitrary polygons in a choropleth map. When you connect to BigQuery data that contains GEOGRAPHY fields, you’ll see them recognized as geospatial data:To visualize this data, add a Google Maps “filled map” visualization:Then, for the Geospatial field, simply choose the field with geospatial data:You can group by a location dimension and color by a dimension or metric. To learn more, check out this step-by-step walkthrough.Let’s take a look at a few examples of this feature in action. We’ll use data from BigQuery Public Datasets, which contain several datasets with geospatial data.Mapping census tractsSuppose we want to visualize rent affordability in different areas of the United States. We can get data about the percentage of income spent on rent from the U.S. Census Bureau’s American Community Survey dataset. We could visualize this metric on a map by state, county, metro area, or zip code, but it can vary quite a bit even within the same zip code. To understand it at a more detailed level, we might want to visualize census tracts. Thankfully, census tract boundaries are available in the U.S. Boundaries dataset. By joining these datasets and visualizing in Data Studio, we can understand rent affordability at a deeper level:Rent affordability by census tract in the Seattle, Washington areaHere, we’re seeing census tracts in the Seattle area, with the least affordable areas in orange. Two areas stand out for very different reasons: the University District (cheaper rent, but many students with low or no income) and Medina (high incomes, but multi-million dollar lakefront houses).Here’s the query to get this data:Mapping New York City taxi zonesNext, suppose we’re analyzing New York City taxi trips and want to understand how tipping varies by pickup location. New York City is divided into taxi zones, whose boundaries are available in the dataset. Using Data Studio, we can visualize the median tip percentage by taxi zone in the Brooklyn and Queens boroughs:Median tip percentage by New York City taxi zoneThe map helps us see a clear geospatial pattern: passengers picked up in the zones nearer to Manhattan tend to tip more.Here’s the query to get this data:While this example involves taxi zones, there are many specialized boundaries that exist across various sectors and businesses: electoral districts, school districts, hospital referral regions, and flood risk zones, for instance.Clustering severe stormsFinally, suppose we want to understand where in the U.S. different types of severe storms tend to occur. Rather than visualize the individual storms, we want to visualize “clusters” of many storms within a given area. BigQuery’s geospatial functions come in handy here: We can assign storms to clusters using the ST_CLUSTERDBSCAN function and draw boundaries around them using the ST_CONVEXHULL function. Then we can visualize these polygons in Data Studio:Clusters of severe storms, and most common storm typeThe map helps us see how the frequency and type of severe storms vary from west to east, from flooding in the Bay Area, to hail storms in the Great Plains, to thunderstorms in the Midwest and East Coast. (If you’d prefer to avoid severe storms altogether, you might want to live in the Pacific Northwest, where drizzle is frequent but severe storms are rare.)Here’s the query to get this data:Try it outReady to try it out for yourself? Check out this step-by-step walkthrough of visualizing BigQuery polygons in Data Studio. Explore the BigQuery Public Datasets or try it with your own data. If your geospatial data isn’t already in BigQuery, you might want to learn more about BigQuery GIS or loading geospatial data into BigQuery using FME.
Quelle: Google Cloud Platform
Late last year, Google Cloud joined the EOS community, a leading open-source platform for blockchain innovation and performance, and is taking steps to support the EOS Public Blockchain by becoming a block producer (BP). At the time, we outlined how our planned participation underscores the importance of blockchain to the future of business, government, and society. Today, I want to outline why Google Cloud is uniquely positioned to be an excellent partner for Block.one and other distributed ledger technology (DLT) companies.We’ve recently seen an unprecedented rate of digital transformation across all industries, as a huge proportion of the economy has moved online. New startups, along with legacy businesses reimagining themselves as software companies, are in aggregate anticipated to account for thirty percent of economic activity by 2025, up from one percent today.As this digital transformation takes hold, businesses increasingly need to build integrated service networks with strong requirements for trust and coordination. This is what a DLT can provide. The EOSIO protocol, developed by Block.one and the basis for the EOS Public Blockchain, is an example of such a DLT. It’s built for speed, scale, and low-cost transactions—all of which make EOSIO an attractive platform upon which to build networked applications. This is where Google Cloud comes in. We are uniquely qualified to help Block.one and other companies develop and operate their DLT networks. A number of our products are well-suited to DLT applications, whether it is the scalability and reliability of our network, our innovation in Confidential Computing, or our leadership in AI/ML and data analytics. Confidential ComputingConfidential Computing is an emerging technology that encrypts data in-use—while it is being processed. Confidential Computing environments keep data encrypted in memory and elsewhere outside of the CPUs. Along with Google Cloud’s advanced capabilities around data in-transit and at-rest, Confidential Computing adds a “third pillar” to encryption by encrypting data while in-use. Confidential Computing is available in nine Google Cloud regions and will continue to extend to a broader set of the regions to support customers like Block.one. Confidential Computing leverages the secure encrypted virtualization supported by 2nd Gen AMD EPYC™ CPUs, ensuring data will stay private and encrypted while it is used, indexed, queried, or trained on. Confidential VMs followed by Confidential GKE Nodes are the first two products in Google Cloud’s Confidential Computing portfolio. Confidential VMs and Confidential GKE Nodes offer the cryptographic level of isolation while giving customers an easy-to-use solution that doesn’t require changing code in apps or compromising on performance. Computing directly on encrypted data is a must-have for the custody and handling of digital assets, and it creates exciting new possibilities, such as machine learning on private data, decentralized exchange of assets, and preventing collusion, exfiltration, and contamination of the network by rogue peers.AI and Data AnalyticsGoogle Cloud’s leading Cloud AI services, and the smart analytics services upon which they are built, enable businesses to get more value out of their data. The broad applicability of this pattern is evident from its many and varied use cases, such as AI for trade finance and decision support for advertising. DLT data on open networks are inherently public and can thus be indexed and made searchable, as we’ve demonstrated and continue to do for Bitcoin, Ethereum, and a number of other public DLTs, and our partners have followed our lead by ETL of DLT data into BigQuery.Perhaps more importantly, exciting new opportunities emerge by combining Cloud AI with Confidential Computing. For example, by executing DLT smart contracts within a trusted execution environment, machine learning accelerators such as Cloud TPU can be used for DLT coprocessing. In addition to computing capabilities, the trustworthiness of APIs can also be ensured and this allows external data to be used in smart contracts. We’ve previously written about the possibilities of building DLT/cloud hybrid applications.Network Performance and SecurityGoogle Cloud’s low-latency premium network tier allows peers to synchronize more quickly, enabling the higher transaction throughputs. Our network also peers directly with many ISPs, meaning that there’s less lag when customers interact with their digital assets, critical to real-world use cases such as retail point-of-sale and gaming. Google’s systems are designed for security and reliability on a global scale. When DLT customers are selecting a cloud platform, a huge part of what they’re looking for is infrastructure. Our infrastructure doesn’t rely on any single technology to make it secure. Our stack builds security through progressive layers that deliver defense in depth. From the physical premises to the purpose-built servers, networking equipment and custom security chips, to the low-level software stack running on every machine, our entire hardware infrastructure is controlled, secured, built and hardened by Google. Learn more and get involvedDevelopers, you can learn more about projects built with EOSIO on Google Cloud in the EOSIO Beyond Blockchain Hackathon—submissions are open until April 6, 2021. Or get building right away by learning how to build with EOSIO. Keep up with Google’s latest EOS block producer activities at https://dlt.withgoogle.com/eos.
Quelle: Google Cloud Platform
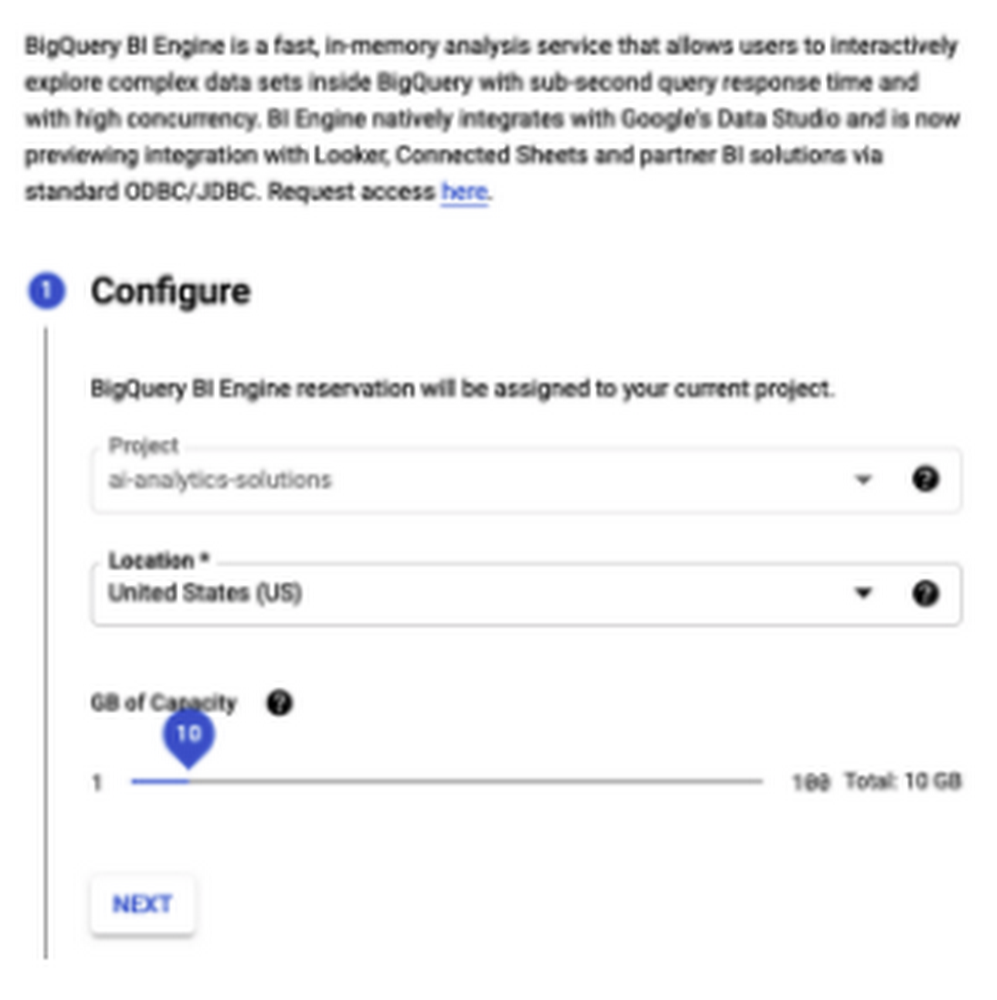
A quick and easy way to speed up small queries in BigQuery (such as to populate interactive applications or dashboards) is to use BI Engine. The New York Times, for example,uses the SQL interface to BI Engine to speed up their Data Reporting Engine.The queriesTo Illustrate, I’ll use three representative queries on tables between 100 MB and 3 GB — tables that are typically considered smallish by BigQuery standards. Because BigQuery is a columnar database, I’m reporting only the size of the columns that the query needs to read.The first involves processing about 400 MB data to find the average cost of a Medicare claim:The second processes a larger table (3GB) to find the average tip for a Chicago taxi based on payment type:The third processes a smaller table (100 MB) to find the most polluted sites:Measuring query performanceTo measure the query performance, I’ll run any given query 5 times, taking care to turn off the cache:The code prints out the total resources consumed (slot-milliseconds) and the total time taken by the query on the server.If you are on a flat-rate pricing (most enterprise customers are), the slot-milliseconds reflects how long your slots are getting used. So, this is a reflection of the cost of the query to you.The time elapsed is the time spent in computing the results. Note that the server_time is the time taken to process the request (I don’t measure the network roundtrip time because it’s going to be the same whether or not you use BI Engine).I first ran the three queries without BI Engine (see my notebook in GitHub).Turning on BI EngineI then went to the BigQuery web console and created a 10 GB BI Engine reservation (monthly cost: $300):Why did I pick 10 GB?One of the key ways that BI Engine speeds up queries on small tables is that it caches the tables in memory. It also does other speedups, but this is the main one. So, you want to provide it enough memory to comfortably hold the tables you will be querying. BI Engine will automatically manage the memory for you.In my case, the Chicago taxicab query involves 3GB, so I used 10 GB. For the other two queries, 1 GB would have been enough. You can go up to 100 GB, something I’d recommend if you have many concurrent queries on small tables. You might be able to get away with less because BI Engine stores data compressed, but it’s better to provide some extra room.You can turn on BI Engine from a script using the Reservations API. Note, however, that it takes a few minutes for the memory to become available, so this is something you should consider doing for a few hours at least, not on a per-query basis.Turning on BI EngineHere’s how the 3 queries compared with and without BI Engine:As you can see, I got cost improvements of 8x to 20x and timing improvements of about 2x. Note that some BI Engine capacity is included at no extra cost when you purchase a flat rate reservation–for example, you get 50 GB of BI Engine included for free with a 1000-slot annual commitment. At $30-$300/month, additional BI Engine capacity is a very cost-effective way to make your BigQuery reservations go further, and get a speedup too. Enjoy!Next stepsTry it out.My code is on GitHub.For more about BI Engine and how to enroll for the preview, see this blog post.You can get the full speedup in your applications provided you are using the query() method in the BigQuery Client API [the insertJob() methods are also accelerated, but not as much]. So, check your code.To learn more about BigQuery,read my book.Note: The SQL interface to BI Engine is in preview at the time of writing (April 2021). Use this enrollment form to turn this on in your account. Thanks to Mosha Pasumansky and the BI Engine team for helpful discussions.Related Article[New blog series] BigQuery explained: An overviewOur new blog series provides an overview of what’s possible with BigQuery.Read Article
Quelle: Google Cloud Platform

System and application logs provide crucial data for operators and developers to troubleshoot and keep applications healthy. Google Cloud automatically captures log data for its services and makes it available in Cloud Logging and Cloud Monitoring. As you add more services to your fleet, tasks such as determining a budget for storing logs data and performing granular cross-project analysis can become challenging. That’s why today we’re proud to announce a set of open source JSON dashboards that can be imported into Cloud Monitoring to help you quickly analyze logging volumes, logs-based metrics and information about your logging exports across multiple projects. The dashboards we are releasing today include:Logging management dashboardGKE logging usageGCE logging usageCloud SQL logging usageLogging Management dashboardThe Logs Storage section of the Cloud Console provides a summary of logging usage data for an individual project including the current total logging volume, previous billed volume and a projected volume estimate for the current month.Categories in the Logs Storage summaryWhile this aggregate level is sufficient for those who just need a high-level view of their usage, you may need to analyze logging usage data across multiple projects or investigate your logging data at a more granular level. The Logging Management dashboard provides that aggregation for any projects included in your Cloud Monitoring Workspace so you are not limited to analyzing just one project at a time.A view of the Logging Management dashboard in Cloud Monitoring, providing aggregated logs metricsUsing standard filters that are available in Cloud Monitoring, you can refine the data to do a more granular analysis, such as display a specific project, log name or log severity. For example, errors tend to provide the most critical signals for applications, and filtering the charts to include just error logs may help identify specific projects and resources to investigate.A filtered view of the ingested error logs in the Logging Management dashboard Logging Usage – Kubernetes dashboardThe Logging usage dashboard for GKE provides an aggregated view of logging metrics for any GKE clusters running in projects included in your Cloud Monitoring Workspace. The views are grouped by cluster, container, pod and namespace.A view of a subset of the tables available in the GKE logging usage dashboard in Cloud Monitoring Using this dashboard, you can filter the dashboard by resource to understand the logging metrics for the specific Kubernetes resource. For example, filtering by cluster_name scopes all the charts in the dashboard to the Kubernetes containers, pods and namespaces running in the selected GKE cluster.A view of logging metrics at the cluster levelBy expanding the chart legend, you can also filter the chart to the selected resources. In the example below, the volume of logs ingested is displayed specifically for the selected resource in the specific Pod.Logging metrics for just one resource displayed at the pod levelThe logging usage dashboard is a logging management complement to the GKE Dashboard in Cloud Monitoring, which we rolled out last year. The GKE Dashboard provides detailed information about metrics and error logs to use for troubleshooting your services.Logging usage- GCE & other dashboardsThe github repo includes other dashboards built specifically for services like Compute Engine and Cloud SQL. A top-level view of the tables available in the GCE logging usage dashboardSet alerts and customize furtherWhile you can analyze important usage metrics for Cloud Logging projects in aggregate or filter to specific logs, to take full advantage of the capabilities of Cloud Monitoring, you can also set proactive alerts on the underlying metrics in the dashboards. Alerts can be set on any metric, such as logging usage volumes or errors, so you are notified when they exceed your specified threshold. Additionally, any of the dashboards can be further customized with our new Monitoring Dashboard builder and if you’re willing to share what you’ve created, send us a pull request against the Monitoring dashboard samples github repo.Learn more about Cloud LoggingGet started today with the Log Explorer, learn more about Cloud Logging with our qwiklab quest and join us in our discussion forum. As always, we welcome your feedback.
Quelle: Google Cloud Platform