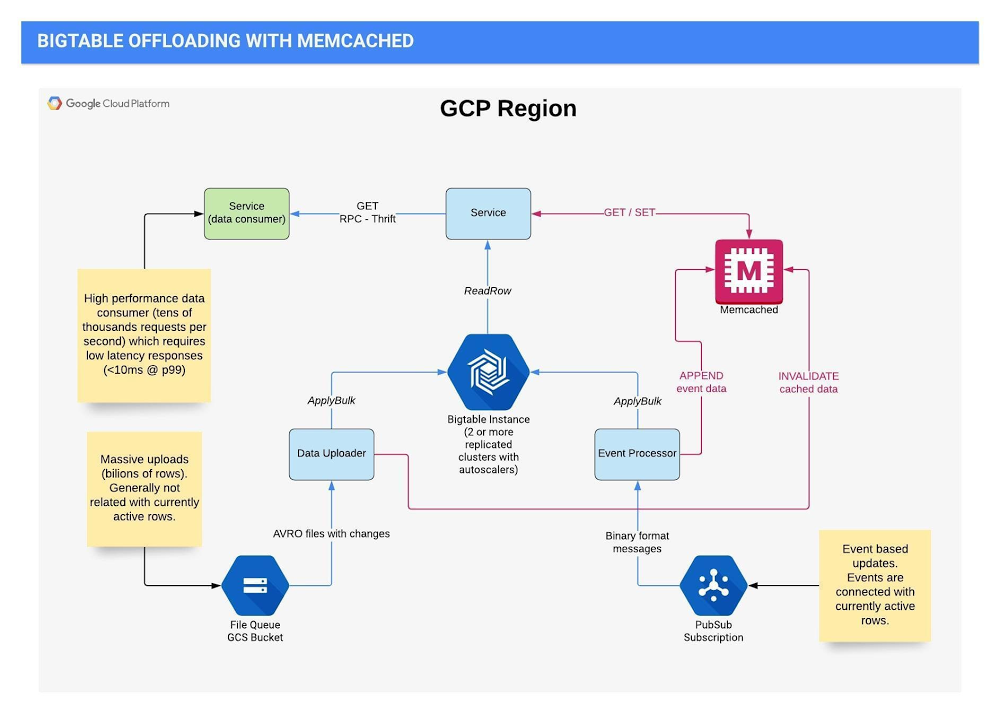
Editor’s note: When ad tech provider OpenX was migrating to Google Cloud, they found a scalable, dependable and cost-effective solution in Bigtable and Memorystore for Memcached. Here’s how—and why—they made the move.Running one of the industry’s largest independent ad exchanges, OpenX developed an integrated platform that combines ad server data and a real-time bidding exchange with a standard supply-side platform to help ad buyers get the highest real-time value for any trade. OpenX serves more than 30,000 brands, more than 1,200 websites, and more than 2,000 premium mobile apps.We migrated to Google Cloud to save time, increase scalability, and be available in more regions in the world. As we were migrating to Google Cloud, we also sought to replace our existing open-source database because it was not supported anymore, which led us to search for a cloud-based solution. The combination of Cloud Bigtable and Memorystore for Memcached from Google Cloud gave us the performance, scalability, and cost-effectiveness we required. Leaving behind an unsupported databaseWhen OpenX was hosted on-premises, our infrastructure included a main open source key value database at the back end that offered low latency and high performance. However, the vendor eventually left the market, which meant we had the technology but no commercial support. This opened up the opportunity for us to take the important step of migrating to the cloud and get a more convenient, stable, and predictable data cloud solution.Performance was a huge consideration for us. We used the legacy key value database to understand the usage patterns of our active web users. We have a higher percentage of get requests than update requests, and our main requirement was, and remains, low latency. We need the database requests to be handled in less than 10 milliseconds at P99 (99th percentile). The expected median is less than five milliseconds, and if the time is shorter, it’s better for our revenue. Scalability was another consideration and, unfortunately, our legacy database wasn’t able to keep up. To handle traffic, our clusters were maxed out and external sharding between two relatively large clusters was required. It wasn’t possible to handle the traffic in a single region by a single instance of this database because we’d reached the maximum number of nodes. In search of a cloud-based solutionChoosing our next solution was a crucial decision, as our database is mission-critical for OpenX. Cloud Bigtable, a fully managed, scalable NoSQL database service, appealed to us because it’s hosted and available on Google Cloud, which is now our native infrastructure. Post migration we had also made it a policy to leverage managed services when possible. In this case we didn’t see the value in operating (installing, updating, optimizing etc) a key value store on top of Google Kubernetes Engine (GKE) – work that doesn’t directly add value to our products.We needed a new key value store and we needed to move quickly because our cloud migration was happening on a very compressed timeline. We were impressed with the foundation paper written about Bigtable, one of the most-cited articles in computer science, so it wasn’t a complete unknown. We also knew that Google itself used Bigtable for its own solutions like Search and Maps, so it held a lot of promise for OpenX. OpenX processes more than 150B ad requests per day and on average 1M such requests per second, so response time and scalability are both business-critical factors for us. To start, we created a solid proof of concept and tested Bigtable from different aspects and saw that the P99s and the P50s met our requirements. And with Bigtable, scalability is not a concern. Where is the data coming from?In each of our regions, we have a Bigtable instance for our service with at least two clusters replicated and with independent autoscalers because we write to both clusters. Data gets into Bigtable in two very different flows. Our first flow handles event-based updates like user-based activity, page views, or cookie syncing, and these events are connected to the currently active rows. We update Bigtable with the updated cookie. It’s a process focused on updating and during this event processing, we usually don’t need to read any data from Bigtable. Events are published to Pub/Sub and processed on GKE.The second flow manages massive uploads of billions of rows from Cloud Storage, which include batch processing results from other OpenX teams and some external sources.We perform reads when we get an ad request. We’ll look at the different numbers that Memorystore for Memcached provided us later in this blog, but here, before we used Memcached, the reads were 15 to 20 times more than the writes. The following chart shows the current architecture today for the flows described above:Click to enlargeThings just happen automaticallyEach of our tables contains at least one billion rows. The column families available to us through Bigtable are incredibly useful and flexible because we are able to set up different retention policies for each, what should be read, and how they should be managed. For some families, we have defined strict retention based on time and version numbers, so the old data is set to disappear automatically when the values are updated. Our traffic pattern is common to the industry; there’s a gradual increase during the day and a decrease at night, and we are using autoscaling to handle that. Autoscaling is challenging in our use case. First of all, our business priority is to serve requests that read from the database because we have to retrieve data quickly for the ads broker. We have the GKE components that write to Bigtable and we have Bigtable itself. If we scale GKE too quickly, it might send too many writes to Bigtable and affect our read performance. We solved this by gradually and slowly scaling up the GKE components , and essentially throttling the rate in which we consume messages from Pub/Sub, an asynchronous message service. This allows the open-source autoscaler we are using for Bigtable to kick in and work its magic, a process which takes a bit longer than GKE scaling, naturally. It’s like a waterfall of autoscaling.At this point, our median response time was about five milliseconds. The 95 percentile was below 10 millisecond and the 99 percentile was generally between 10 and 20 milliseconds. This was good, but after working with the Bigtable team and the GCP Professional Services Organization team we felt like we could do better by leveraging another tool in the Google Cloud toolbox.Memorystore for Memcached saved us 50% in costsCloud Memorystore is Google’s in-memory datastore service, a solution we turned to when we wanted to improve performance, reduce response time and optimize overall costs. Our approach was to add a caching layer in front of Bigtable. So we created another POC with Memorystore for Memcached to investigate and experiment with the caching times, and the results were very fruitful. By using Memorystore as a caching layer we reduced the median and P75 to a value close to the Memcached response times and which is lower than one millisecond. P95 and P99 also decreased. Of course, response times vary by region and workload, but they have been significantly improved across the board. With Memorystore, we were also able to optimize the number of requests to Bigtable. Now, over 80% of get requests are fetching data from Memorystore, and less than 20% from Bigtable. As we reduced the traffic to the database, we reduced the size of our Bigtable instances as well. With Memorystore, we were able to reduce our Bigtable node count by over 50%. As a result of this, we are paying for Bigtable and Memorystore together 50% less than what we paid for Bigtable alone before that. With Bigtable and Memorystore, we could leave the problems of our legacy database behind and position ourselves for growth with solutions that provided low latency and high performance in a scalable, managed solution.To learn more about OpenX, visit our site. To explore Memorystore for Memcached, read how it powers up caching.Thank you: None of this would have been possible without the hard work of Grzegorz Łyczba, Mateusz Tapa, Dominik Walter, Jarosław Stropa, Maciej Wolny, Damian Majewski, Bartłomiej Szysz, Michał Ślusarczyk, along with the rest of the OpenX Engineering Teams. We’re also grateful for the support of Google strategic cloud engineer Radosław Stankiewicz.Related ArticleHow Memorystore cut costs in half for Quizlet’s Memcached workloadsSee how online learning platform Quizlet uses managed database service Memorystore for Memcached to cut costs, improve reliability for SRE.Read Article
Quelle: Google Cloud Platform