Anschlagspläne: Texaner wollte Amazon-Rechenzentrum in die Luft sprengen
Beim Kauf des Sprengstoffs wurde der Mann festgenommen. Auf ihn aufmerksam wurde das FBI durch einen Tipp. (AWS, Amazon)
Quelle: Golem

Beim Kauf des Sprengstoffs wurde der Mann festgenommen. Auf ihn aufmerksam wurde das FBI durch einen Tipp. (AWS, Amazon)
Quelle: Golem

Forschern ist es gelungen, ohne Benutzerinteraktion Schadcode per Zoom auszuführen. Präsentiert wurden die Lücken auf dem Hackerwettbewerb Pwn2own. (Sicherheitslücke, Ubuntu)
Quelle: Golem

Der für seine Elektroroller bekannte Hersteller NIU hat die ersten Bilder der Serienversion seines Elektromotorrads veröffentlicht. (Elektromotorrad, Technologie)
Quelle: Golem

Ist mehr CO2 verfügbar, nehmen Pflanzen auch mehr davon auf. Doch seit den 1980er Jahren nimmt der Effekt ab, wie eine Studie zeigt. Das hat Auswirkungen auf den Kampf gegen die Klimakrise. (Klimakrise, Studie)
Quelle: Golem

China und das Sultanat von Delhi plus erweiterte taktische Optionen: Es gibt viele neue Infos zu Age of Empires 4. Von Peter Steinlechner (Age of Empires, Microsoft)
Quelle: Golem

Tolkien auf Russisch in unter zwei Stunden und Zoobesuche aus der Ferne mit Luca. Die Woche im Video. (Golem-Wochenrückblick, Tchibo)
Quelle: Golem
In this post, we’ll walk through an example of how to configure Red Hat Enterprise Linux (RHEL) 8 crypto-policy to remove Cipher block chaining (CBC), but let’s start with a little background on CBC and default crypto-policy on RHEL 8.
At an operational level, most of us have experienced situations where there is a complex configuration on a system, and there is either too much or too little information to understand everything.
Quelle: CloudForms

The Lightning framework is a great companion to PyTorch. The lightweight wrapper can help organize your PyTorch code into modules, and it provides useful functions for common tasks. For an overview of Lightning and how to use it on Google Cloud Platform, this blog post can get you started.One really nice feature of Lightning is being able to train on any hardware without changing your core model code. An Accelerator API is provided with built-in support for CPU, GPU, TPU, Horovod, and more. You can even extend the API to support your own hardware.In this blog post, we’ll see how easy it is to start training models with Lightning on TPUs. TPUs, or Tensor Processing Units, are specialized ML processors that can dramatically accelerate the time to train your model. If you’re new to TPUs, the blog post What makes TPUs fine-tuned for deep learning? is a gentle introduction to TPU architecture and benefits.Google Cloud’s GA support for PyTorch / XLA is the bridge between PyTorch and the TPU hardware. XLA, or Accelerated Linear Algebra, compiles high level operations from your model into operations optimized for speed and memory usage on the TPU. PyTorch XLA Deep Learning Containers are available at gcr.io/deeplearning-platform-release/pytorch-xla, preconfigured with everything you need to use PyTorch on TPUs.Now that we’ve introduced the concepts, let’s walk through how to get started. We will demonstrate how to setup the Cloud infrastructure, a notebook instance that is connected to a TPU node. Then, we will show how to use this TPU node in our training from PyTorch Lightning. Setup your notebook instanceThe first step is setting up the notebook instance. From the Cloud Console, go to AI Platform > Notebooks. Select New Instance, then Customize instance, so that we can provide more specific configuration details.Next, select a region and zone. After that, the key inputs are:Environment: Custom containerDocker container image: gcr.io/deeplearning-platform-release/pytorch-xla.1-8Machine configuration: n1-standard-16Select CREATE to begin provisioning your notebook instance.If newer PyTorch XLA images are available, you can feel free to use those. Just make sure that the version matches the version of the TPU node that we’ll create next. You can browse available images at gcr.io/deeplearning-platform-release.After the notebook has been provisioned, select OPEN JUPYTERLAB to access the JupyterLab environment. If you’d like to access the sample for this tutorial, you can open a new terminal (File > New > Terminal), and then run:cd /home/jupytergit clonehttps://github.com/GoogleCloudPlatform/ai-platform-samplesThe left sidebar will refresh after a few moments. You’ll find the sample within ai-platform samples > notebooks > samples > pytorch > lightning.Setup your TPU nodeNext, let’s provision a TPU node that we can use from our notebook instance. From the Cloud Console, go to Compute Engine > TPUs. Select Create TPU Node, and then choose a name of your choice. Then, select a Zone and TPU type, keeping in mind that TPU availability varies per region.Make sure to select a TPU software version that matches the version you selected for your notebook, in this case pytorch-1.8. Also, for the purposes of this tutorial, select datalab-network for the Network, so that you can access your TPU directly from the notebook instance without configuring any networking settings.Connect your notebook instance to the TPU nodeAfter your TPU has been provisioned, go back to the sample notebook. There are a couple optional cells for TPU configuration that you can uncomment. Let’s walk through these.First, let’s check the IP address of the Cloud TPU you created. Make sure to update –zone with your TPU zone.Make note of a couple items here:ACCELERATOR_TYPE: v3-8 tells us the TPU type and number of cores. In this case, we created a v3 with 8 cores.NETWORK_ENDPOINTS: we’ll need to include this IP address in an environment variable, so that we can communicate with the TPU node. You can set this variable in the sample notebook, and this it will be exported in this line:Basically, exporting that one environment variable is all that’s required!Training your model with TPUsLightning helps you organize your PyTorch code by extending classes such as LightningModule and LightningDataModule. The model code contained with your LightningModule can be reused across different types of hardware.The Lightning Trainer class manages the training process. Not only does it handle standard training tasks such as iterating over batches of data, calculating losses, and so on, it takes care of distributed training! It uses a PyTorch DistributedDataSampler to distribute the right data to each TPU core. It also leverages PyTorch’s DistributedDataParallel strategy that replicates the model across each core, passes in the appropriate inputs, and manages gradient communication between each core.When creating the Trainer, you can use the tpu_cores argument to configure TPU support. You can either pass in the number of TPU cores or a specific core you’d like to use:You can use the Brain Floating Point Format, or bfloat16, by setting the environment variable XLA_USE_BF16=1. bfloat16 has worked as well as the 32-bit floating point format in practice, while reducing memory usage and increasing performance. For more details, see this blog post: BFloat16: The secret to high performance on Cloud TPUs.To begin training, all you need to do is call the fit() method:You will then have a trained PyTorch model that you can use for inference, or to save to a model file for production deployment. You’ll see how to do that and more in the sample notebook, which you can directly open in AI Platform Notebooks.In this blog post, we’ve seen how PyTorch Lightning running on Google Cloud Platform makes training on TPUs a breeze. We showed how to configure a TPU node and connect it to a JupyterLab notebook instance. Then, we leveraged standard PyTorch distributed training across TPU cores, by using the same, reusable model code that works on any hardware. With the power of TPUs at your fingertips, what will you solve next?Related ArticlePyTorch / XLA now generally available on Cloud TPUsPyTorch / XLA support for Cloud TPUs is now generally available. This means PyTorch users can access large scale, low cost Cloud TPU hard…Read Article
Quelle: Google Cloud Platform
Contact center virtual agents, such as chatbots or voice bots, leverage the power of artificial intelligence (AI) to help businesses connect with their customers and answer questions round the clock, regardless of request volume. AI tools will only become more critical for streamlining customer experience processes in the future. Are you convinced about the benefits of conversational AI for your contact center but don’t know where to start? As UX researchers who are part of the team behind Google Contact Center AI (CCAI), we spend a lot of time with our customers and have a unique perspective on what’s needed to develop and manage virtual agents correctly. Although there is no one-size-fits-all for creating a team, we have discovered six typical roles during our numerous hours of studying contact centers. In this post, we’ll discuss each role and the additional stakeholders that are critical ingredients for getting conversational AI right. All engineers — the most common pitfallBefore we jump in, let’s quickly discuss why this topic is so important. Too often, we see teams made up of all engineers or a product manager responsible for doing everything. A potential reason for this is that many companies underestimate how hard it is to implement a virtual agent that can interact with a customer appropriately and naturally. More often than not, the flow of conversation becomes too nuanced to interpret. We even see flow mistakes in simple cases, for example, at the end of a conversation:User: Goodbye.Virtual agent: I think you said Goodbye. Do you want to restore the conversation?User: (What?) [user quits the chat]This type of misunderstanding often leaves people feeling confused or disappointed with the experience, which is a direct extension of the company. In more severe cases, inadequate attention to virtual agent design can harm your brand credibility or even cause a PR crisis. That’s why we also encourage our customers to build conversational AI from a user-centric perspective—and that requires assembling the right team. The core roles needed for conversational AI When building a virtual agent for the first time, you have to create a team with the right blend of skills, striking a balance between engineering, user experience, and data science. Through our own experience, we have identified the following three core roles:1) Conversational ArchitectA Conversational Architect (CA) is an expert at designing conversations. Like an architect designing a house, they create blueprints for the virtual agent to use when interacting with customers. They leverage professional human language skills to bring natural human speech patterns to the human to virtual agent interaction flows. For example, a virtual agent’s language should be supportive in its content, style and tone, as well as use the correct level of formality needed for a specific context. In addition, conversational architects should have a clear understanding of the product requirements and customers’ needs, working with business stakeholders to:Gather customer requirementsDefine use casesDesign a human-to-virtual-agent conversation flow iterativelyLet’s consider a chatbot created for travel booking and managing existing reservations. To design an interaction flow that fits the business logic, legal terms, and domain specifications, it’s necessary to communicate with multiple parties. In this particular case, a CA would be responsible for working with business stakeholders to define the essential details, such as destination, dates, or number of people traveling, needed to create a new booking. Also, CAs often transfer the conversation flow design into a chatbot or a voice bot through a bot creation platform. 2) Bot developerIf a CA designs and manages the conversation between humans and virtual agents, then bot developers are in charge of ensuring that a virtual agent has ability to conduct complex actions, such as checking available dates for available flights. Bot developers are also responsible for supporting service integration and any additional customized UI or IVR (Interactive Voice Response) implementations.3) Quality Assurance TestersDue to the nature of the iterative and incremental conversational AI development and maintenance life cycle, another critical role identified from best practices is Quality Assurance (QA) tester. This role is often easily overlooked, especially in the early stages of the development process. Quality assurance testers are responsible for testing conversational AI against pre-defined use cases. Those use cases or scripts are typically created based on the design from the CA or through analysis of the available conversation data. Any breakdowns in a conversation, unexpected user experiences, or mismatched targeted flows will be discovered by QA and reported to the team. QA testers can also identify new cases or problematic flows to assist the CA in refining the conversation design. The good-to-have roles that support strong conversational AI developmentBesides the three core roles, strong conversational AI teams typically include the following good-to-have roles:Product managerCopywriter Data analyst Product managers help conversational architects define and prioritize use cases, manage the development life cycle, and communicate with multiple teams. Copywriters come into play after a CA has defined the interaction flow, with one primary purpose—to ensure the virtual agent’s content quality. It’s hard for conversational AI technology to understand human conversations without training data. People often use different expressions to say things, and based on what they say, we can match intent. In Google Cloud Dialogflow, we call these training phrases—or the different expressions people might use to say things. For example, users might use the expression “Get a pizza” or “Order pizza” for the phrase “I want a pizza.” Our customers often use call center log data or copywriters to help them create and define training phrases. “Designing the conversation is one piece, but writing the responses is different—copywriters can help think through the persona of a virtual agent.” — Pavel Sirotin, Conversational AI Incubator ManagerIt’s critical for creating complex virtual agents with tons of training phrases and responses to have a copywriter on the team managing all the content. For example, if someone says “I want to book a flight to Paris,” a copywriter would have to come up with at least 10 to 15 other expressions that a person might use to say the same thing, including: “I would like to book a flight to Paris” “I’d like a flight to Paris” “I plan to travel to Paris and need to book a flight” Once a chatbot or voice bot is launched, data analysts can then define and monitor key metrics, analyze failure root causes, and set up A/B testing for experimental features.Other crucial stakeholders to considerIn addition to the roles that directly contribute to conversational AI development, we also see other stakeholders with varying degrees of involvement. Legal advisors can provide a comprehensive understanding of all regulations needed to define the project scope and use cases. We’ve also seen business advisors from the marketing team review the virtual agent interactions according to the updated business rules and strategies. To help discover the most impactful call use cases, teams will often initiate research conversations with call center managers. Managers have a stronger understanding of the interactions best suited for replacement or augmentation due to their knowledge about call volume and use case complexity. Call center agents are also often underestimated and overlooked when it comes to developing conversational AI. We’ve witnessed many successful examples of call center agents collaborating either as direct conversational AI team members or acting as consultants. Their knowledge from the field, including the familiarity of the business rules and their innumerable practices with customers in real conversations, is extremely valuable for conversation flow design and training phrase writing. For example, in the flight booking use case, call center agents could help identify what related one-off questions are asked most frequently by customers. Getting the recipe rightThere is no single, works-every-time formula when it comes to creating a conversational AI team. It comes down to finding the mix that works best for your priorities, the stage of development at your organization, your resources, and more. At the same time, following our recipe for the core roles, good-to-have supporting roles, and other key stakeholders to consider will put you on the right path to building a world-class team. Conversational AI development is not magic—it’s collaborative work. With Google Contact Center AI Dialogflow CX, enterprises can now build advanced virtual agents using intuitive Visual Flow builder with less development effort. Read this to learn more about using Dialogflow CX to build virtual agents.Related ArticleRespond to customers faster and more accurately with Dialogflow CXNew Dialogflow CX Virtual Agents can jumpstart your contact center operational efficiency goals, drive CSAT up and take care of your huma…Read Article
Quelle: Google Cloud Platform
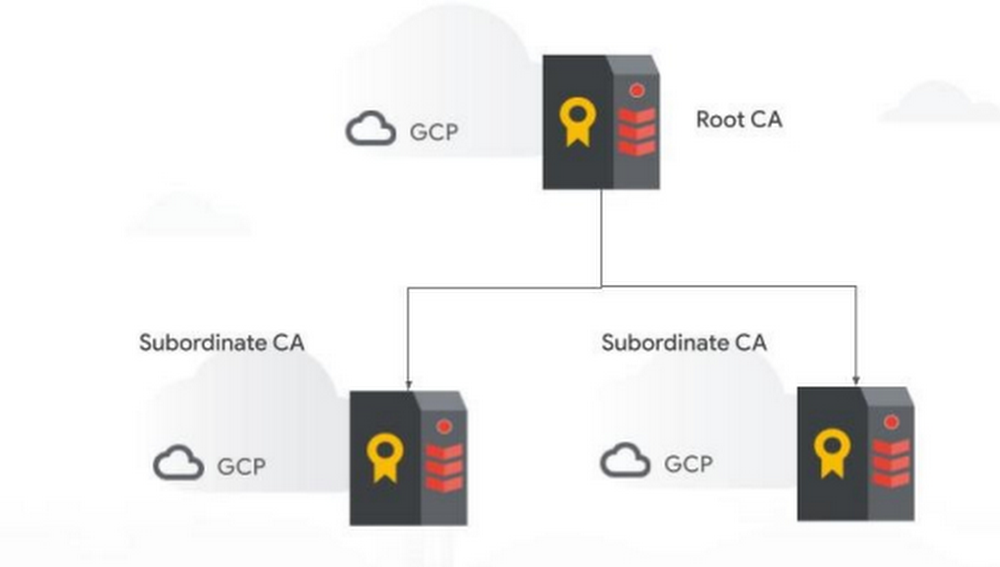
Certificate Authority Service (CAS) is a highly available, scalable Google Cloud service that enables you to simplify, automate, and customize the deployment, management, and security of private certificate authorities (CA). As it nears general availability, we want to provide guidance on how to deploy the service in real world scenarios. Today we’re releasing a whitepaper about CAS that explains exactly that. And if you want to learn more about how and why CAS was built, we have a paper on that too.“How to deploy a secure and reliable public key infrastructure with Google Cloud Certificate Authority Service” (written by Mark Cooper of PKI Solutions and Anoosh Saboori of Google Cloud ) covers security and architectural recommendations for the use of the Google Cloud CAS by organizations, and describes critical concepts for securing and deploying a PKI based on CAS. The purpose of a public key infrastructure (PKI) to issue certificates is largely dependent on the environment in which the PKI-issued certificates will be used. For common internet-facing services, such as a website or host where visitors to the site are largely unknown to the host, a certificate that is trusted by the visitor is required to ensure a seamless validation of the host. If a visitor’s browser hasn’t been configured to trust the PKI from which the certificate was issued, an error will occur. To facilitate this process, publicly trusted certificate authorities issue certificates that can be broadly trusted throughout the world. However, their structure, identity requirements, certificate restrictions, and certificate cost make them ineffective for certificate needs within an organizational or private ecosystem, such as the internet of things (IoT) or DevOps. Organizations that have a need for internally trusted certificates and little to no need for externally trusted certificates can have more flexibility, control, and security in their certificates without a per-certificate charge from commercial providers. A private PKI can be configured to issue the certificates an organization needs for a wide range of use cases, and can be configured to do so on a large scale, automated basis. Additionally, an organization can be assured that externally issued certificates cannot be used to access or connect to organizational resources.The Google Cloud Certificate Authority Service (CAS) allows organizations to establish, secure and operate their own private PKI. Certificates issued by CAS will be trusted only by the devices and services an organization configures to trust the PKI.Here are our favorite quotes from the paper:“CAS enables organizations to flexibly expand, integrate or establish a PKI for their needs. CAS can be used to establish and operate as an organization’s entire PKI or can be used to act as one or more CA components in the PKI along with on-premises or other CAs.”“There are several architectures that could be implemented to achieve goals within your organization and your PKI: Cloud root CA, cloud issuing CA and others” “Providing a dispersed and highly available PKI for your organization can be greatly simplified through CAS Regionalization. When deploying your CA, you can easily specify the location of your CA.”“CAS provides two operational service tiers for a CA – DevOps and Enterprise. These two tiers provide organizations with a balance of performance and security based on operational requirements.”Read “How to deploy a secure and reliable public key infrastructure with Google Cloud Certificate Authority Service”, and sign up for CAS here.Related ArticleNew whitepaper: Scaling certificate management with Certificate Authority ServiceThis whitepaper explains how organizations can more easily manage devices with Google Cloud’s Certificate Authority ServiceRead Article
Quelle: Google Cloud Platform