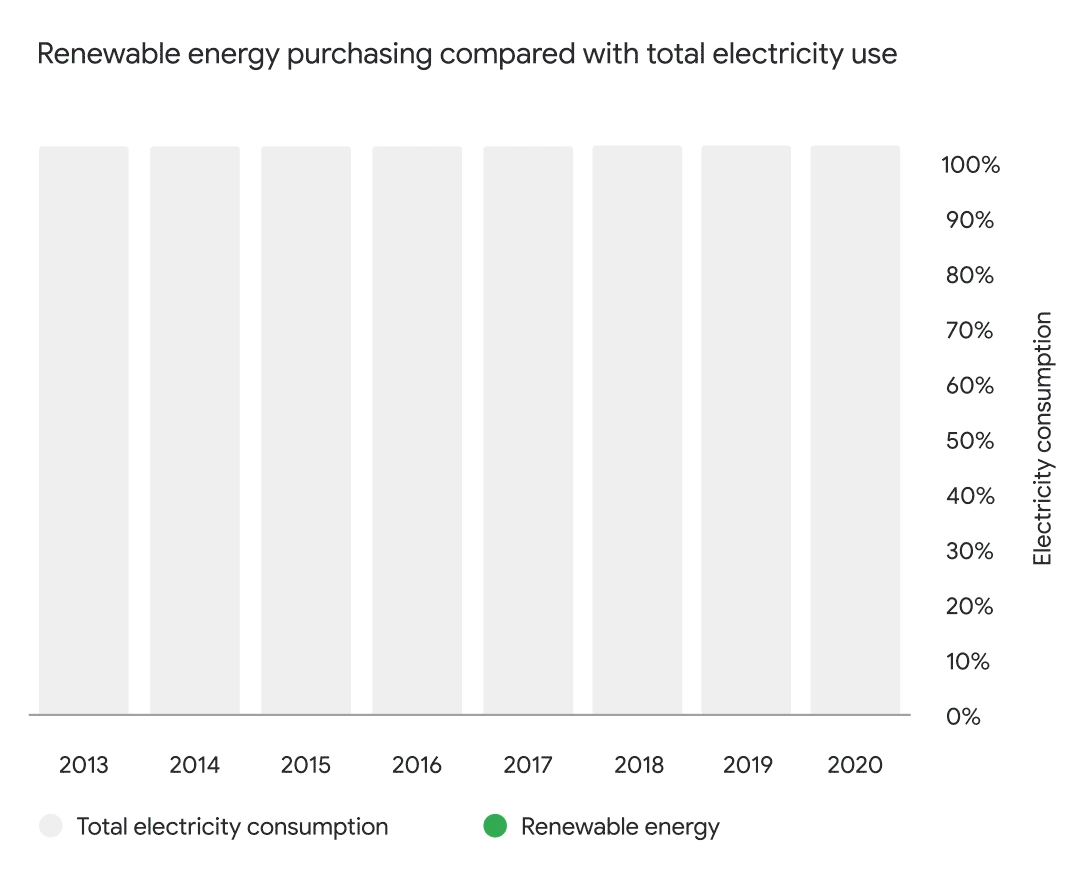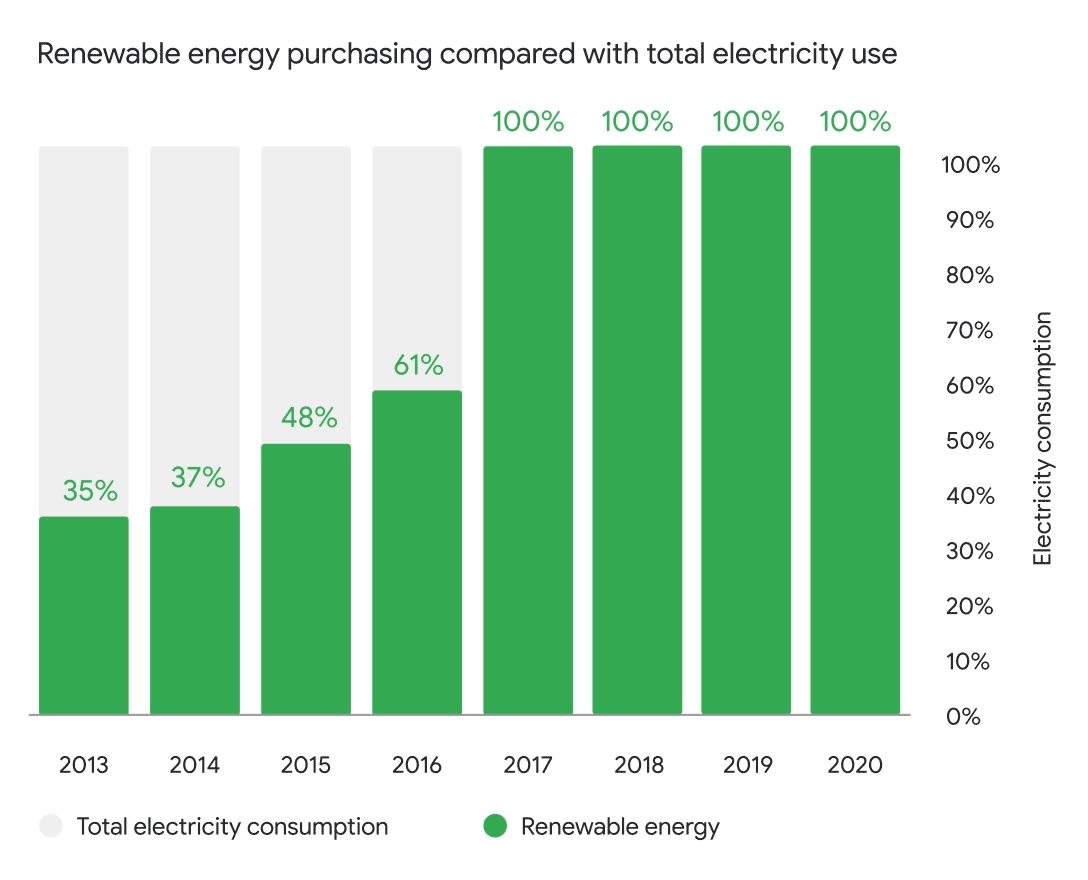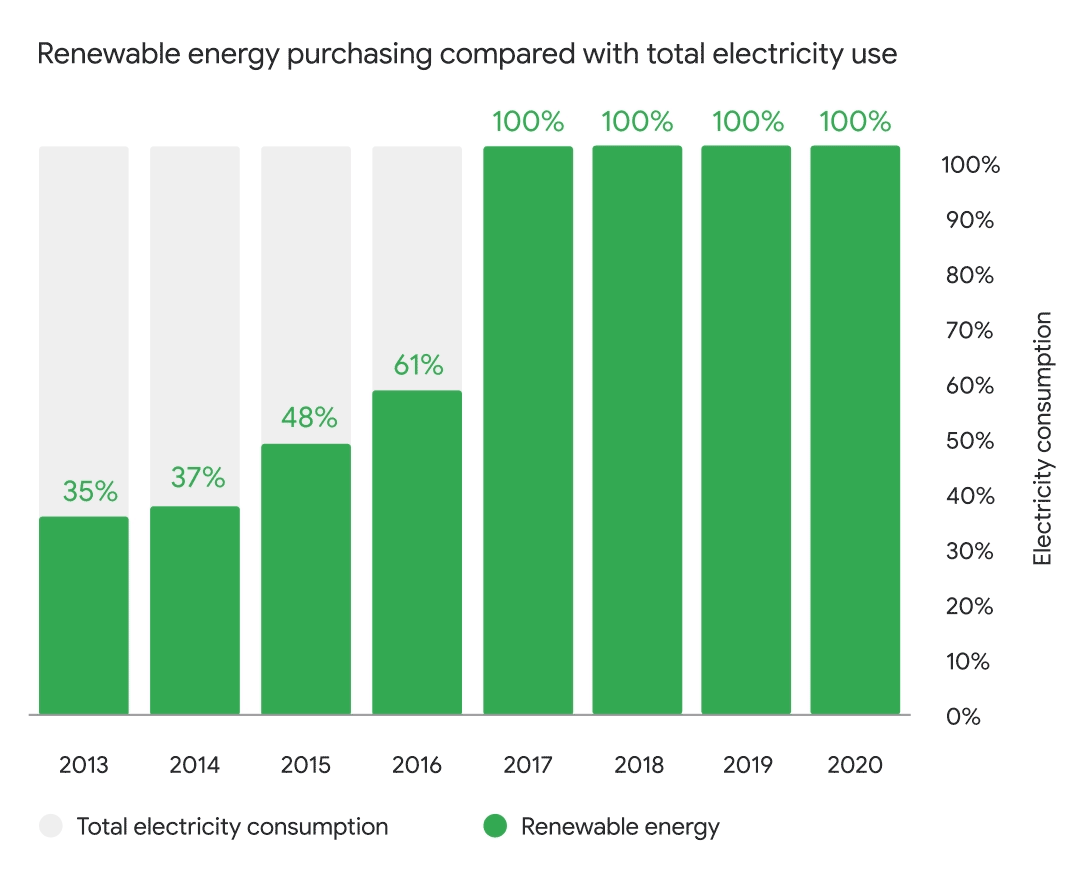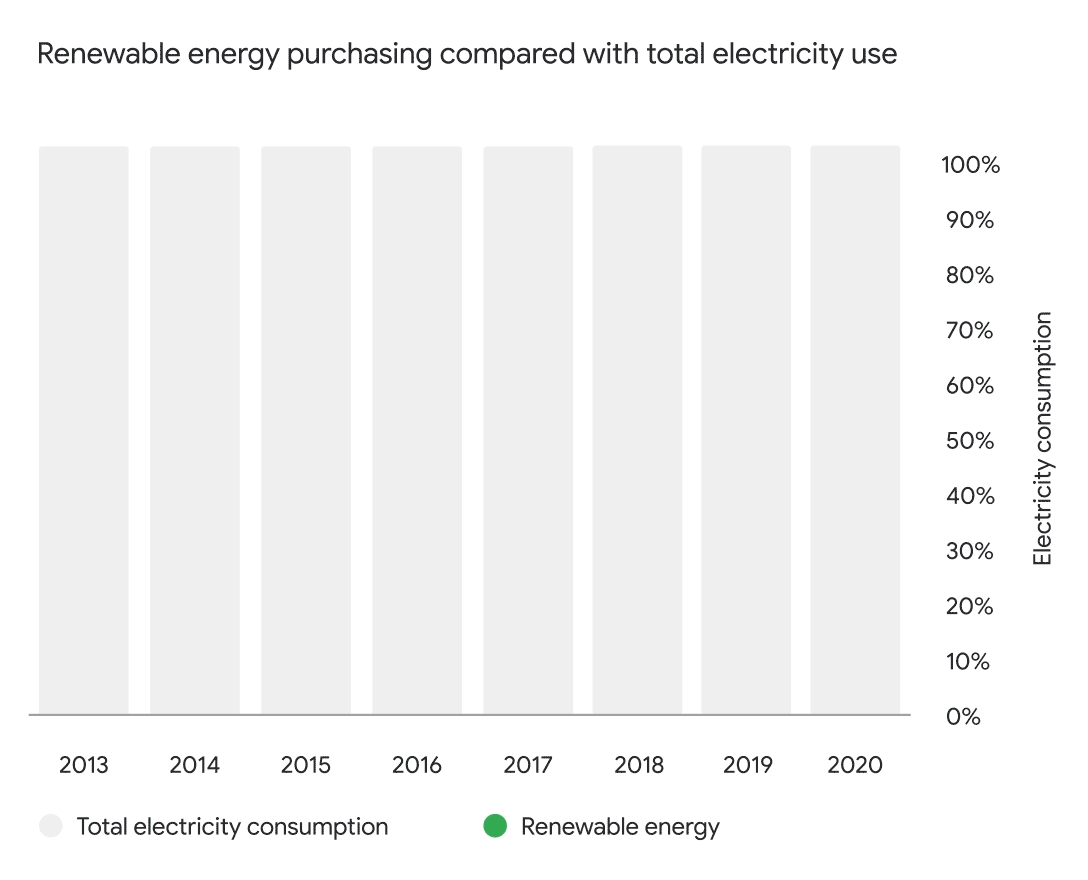
Guest post by Docker Captain Gianluca Arbezzano
Recently Corey Quinn from LastWeekInAWS wrote an article that made me think “Nobody Cares About the Operating System Anymore”. Please have a look at it! I like the idea that nobody cares about where their application runs. Developers only want them running.
A bit of context about Tinkerbell
I am one of the maintainers for the Tinkerbell project. A bare metal workflows engine that heavily relies on containers and Docker to get its work done. It tries to find an answer for a reasonable question: how do we manage rooms of pieces of hardware? More in practice, how can we bring an API on top of everybody’s data centers?
Containers are the abstraction we decided to use when running reusable code (that we call actions) in somebody else’s hardware. Mainly because distribution, packaging, and runtime are solved issues. Everyone knows how to build, push and run a container.
I think this scenario compares well with the story Corey highlighted. Operating systems are an established, well-known abstraction for the majority of the use cases.
The special operating system for bare metal provisioning
The lifecycle of a bare metal server can be summarised as follows:
You mount SSDs, RAMs and you rack your server, cabling it with power and dataIf you have a BMC, you can remotely start the server. Otherwise, you have to push the power button manuallyThe BIOS looks for bootable devices, USBs, disks, but it can’t find anything to boot because the disk driver is not something that server has nowadays, and there are not operators running with USB sticks in modern datacentersUsually, the last chance a server has to boot when nothing works is via netbooting. A popular technology for that is called PXE (the new one iPXE).PXE makes a DHCP request; you can imagine it as the last SOS: “PLEASE tell me what to do.”If there is a DHCP listening, it can replay with a rescue message to simplify things with a script that PXE can execute.
Usually, the script contains boot information for an operating system, a Linux operating system that can run on RAM. For example, this is how you can Netboot Alpine.
Now the hardware has an ephemeral (on RAM) fully operational operating system. Tinkerbell distributes two of them, one called OSIE and the second one called Hook:
OSIE is the one ran by Equinix Metal internally to provision their entire cloud offerHook is a more recent one the Tinkerbell community develop using LinuxKit
OSIE or Hooks are essential for bare metal provisioning because they are the source of power for what you can do on the hardware itself. Tinkerbell starts a docker daemon, and it downloads and executes a set of actions (as you read Docker containers).
The actions all together build workflows that looks like:
Provisioning: flash and install the end is the operating system on the disk, so next boot, you can access Ubuntu, CentOS, CoreOS, or what you needDeprovision: you can wipe disks and make the server available for a next brand new use
This article is about why we choose LinuxKit, and I hope it will give you more information about when you should think about using it as well!
Nobody cares about the operating system, but you can not avoid one
As you can imagine reading briefly about Tinkerbell when it comes to bare metal provisioning, every bit counts because the hardware lifecycle is cold and not that fast. Stay in control of every step is crucial, from when the server power to when it makes the DHCP request when the hardware boots the in-memory operating system until you finally get what you want executed!
When it comes to operating systems and Linux maintaining a distribution is a lot of work! Even if it dedicated to a specific use case like the one we have to Tinkerbell (it is just a temporary execution environment that relays on Docker) we still have to take care of:
Compatibilities: there are many hardware devices, drivers, kernel modules, architecturesSize: the operating system runs on RAM, yeah it is not that expensive nowadays, but still, we have to be carefulNeeds: We can not assume that all the environments where Tinkerbell runs are the same. For example somebody will make like the idea to run an SSH server as part of the in memory environment because their server do not have a serial console and SSH is a good option for troubleshooting. Or they want to run agents for service discovery like Consul, or for monitoring like Telegraf to improve observability and monitoring. Or some scanner for security purposes.
We can’t make one that works for everything and everybody. That’s why with Hook we decided to adopt LinuxKit.
LinuxKit is now part of the Linux Foundation, initially developed by Docker specifically to release Docker for Mac. You can think about it as a Linux builder focused on containers.
You can add a program on boot as init, or as long-running services. The cool part is that everything runs as a container giving us the ability to package building blocks as Docker containers, leaving a clear path from end-user to build their environment, based on their needs reusing LinuxKit itself (if they want) and the building blocks we developed.
One of the building blocks I am referring to is a Docker container who overrides the logic used by LinuxKit to start the docker daemon. Along that it also starts what we call tink-worker. An agent who reaches out to the tink server obtaining the next workflow to run. You can think about them as api-server and kubelet for Kubernetes but instead of running pods tink-worker reaches out to the Docker daemon running actions such as:
streaming a new operating system to a particular diskformatting or partitioning a diskExecuting commands with a different chrootBut it can be every container, you can even run an action that notifies you on slack when your workflows reaches a certain point
LinuxKit provides facilities for multi-architecture and output format as well. We are working for ARM support, for example.
Being part of something bigger than ourselves
LinuxKit has a supportive community with docs, examples and even a Slack channel. End users of Tinkebell can make use of hundreds of people and maintainers dedicated to only building distros with LinuxKit. This makes the effort of maintaining Tinkerbell scoped to a reasonable size. Allowing us to stay strict to what matters most. Provisioning bare metal quickly.
The post LinuxKit as a Commodity for Building Linux Distributions appeared first on Docker Blog.
Quelle: https://blog.docker.com/feed/