Fingerabdruckscanner: iPhone 13 soll Touch ID auf dem Bildschirm bekommen
Die kommende iPhone-13-Generation soll wieder einen Fingerabdruckscanner haben, diesmal aber unter dem Display. (Fingerabdrucksensor, Biometrie)
Quelle: Golem

Die kommende iPhone-13-Generation soll wieder einen Fingerabdruckscanner haben, diesmal aber unter dem Display. (Fingerabdrucksensor, Biometrie)
Quelle: Golem

Wer Fallout 4 und Skyrim nach der Aufnahme in den Xbox Game Pass spielen möchte, sollte warten: Demnächst verdoppelt Microsoft die Bildrate. (Xbox Series X, Microsoft)
Quelle: Golem

Ein Investor verklagt Tesla-Chef Elon Musk wegen Tweets, die den Kurs des Unternehmens negativ beeinflusst haben sollen. (Elon Musk, Börse)
Quelle: Golem
Today, everything from payroll software to specialized machine-learning systems is available “as a service” in the cloud, addressing a vast range of needs across businesses, enabling rapid growth and scale while allowing a business to focus on its core competencies.But moving to the cloud can generate tension, which is inevitably challenging for everyone involved—especially if that transformation creates “winners” and “losers” or frames individuals as “old” or “new.” The good news; however, is that a cloud transformation doesn’t have to be this way.As Google Cloud has grown, so too has the team of Googlers who build and support the platform, and many of us have sat in the same seat as our customers. We’ve experienced firsthand how empowering it can be to shape the future of an organization, help one another grow, as well as unlock the business opportunities that a transformation provides. Our own personal experiences, and those of our peers, have led us to conclude one thing we know to be true for every company – the story of digital transformation is a human story—one that involves as much cultural transformation as technological transformation. It’s with this realization we have identified the deeper factors behind a successful transformation. That’s why we recently published a guide, reflecting on the nature of these changes and how you can take action in your own organization to drive a migration to the cloud. Posing challenging questions helps you reflect on your own organization’s journey and the unique path you will need to take to lead to meaningful change. We wrote this guide to share key tenets that underpin the change philosophy you need to instill in your own organization. In A Practical Guide to Moving to Cloud, we present the following calls to action:Understand who in the organization you need to enlist to move to cloud.Create a psychologically safe culture in which you can grow together.Define clear objectives for your organization. Document measurable steps towards these goals and understand that each step must, in and of itself, deliver value.Review your existing organizational behaviors and set principles/policies which influence and direct every future decision related to your transformation.Use your new culture to refine how decisions are made, and provide meaningful autonomy across the organization.Build structures that empower practitioners to share best practices and solve common problems. Use these structures to empower your peers.Build guardrails into your cloud platform that support transformation, at pace, without negatively impacting others. Support safe experimentation.Understand what types of cloud platforms are the best fit for your business needs and determine your multi-cloud strategy in anticipation of your evolving business needs (e.g. acquisitions, new revenue streams, competitive responses).Recognize that everything is now software, and understand what this means for your existing IT infrastructure functions.Don’t be afraid to revisit existing, hallowed, security policies. Making them fit-for-purpose is crucial.Continuously measure and apply your new policies through software.Be bold; build a new way of operating your business products with a customer-centric perspective. Love your developers.At Google Cloud, we’re here to help you craft the right migration for you and your business. A Practical Guide to Moving to Cloud is available as a free download. You can also learn more about our data center migration solutions or sign up for a free migration cost assessment. Let’s get migrating! Visit sre.google to learn more about SRE and industry-leading practices for service reliability.
Quelle: Google Cloud Platform
TLDR: Improve your application’s performance by using Memcached for frequently queried data like this:Databases are designed for specific schemas, queries, and throughput, but if you have data that gets queried more frequently for a period of time, you may want to reduce the load on your database by introducing a cache layer. In this post, we’ll look at the horizontally scalable Google Cloud Bigtable, which is great for high-throughput reads and writes. Performance can be optimized by ensuring rows are queried somewhat uniformly across the database. If we introduce a cache for more frequently queried rows, we speed up our application in two ways: we are reducing the load on hotspotted rows and speeding up responses by regionally colocating the cache and computing. Memcached is an in-memory key-value store for small chunks of arbitrary data, and I’m going to use the scalable, fully managed Memorystore for Memcached, since it is well integrated with the Google Cloud ecosystem.SetupCreate a new Google Cloud project or use an existing project and database of your choice. The examples here will show Cloud Bigtable, but Spanner or Firestore would be good options too.I’ll provide gcloud commands for most of the steps, but you can do most of this in the Google Cloud Console if you prefer.Create a Cloud Bigtable instance and a table with one row using these commands:cbt createinstance bt-cache “Bigtable with cache” bt-cache-c1 us-central1-b 1 SSD && cbt -instance=bt-cache createtable mobile-time-series “families=stats_summary” && cbt -instance=bt-cache set mobile-time-series phone#4c410523#20190501 stats_summary:os_build=PQ2A.190405.003 stats_summary:os_name=android && cbt -instance=bt-cache read mobile-time-seriesThe codeThe generic logic for a cache can be defined in the following steps: Pick a row key to query.If row key is in cacheReturn the value. 3. OtherwiseLook up the row in Cloud Bigtable.Add the value to the cache with an expiration.Return the value.For Cloud Bigtable, your code might look like this (full code on GitHub):I chose to make the cache key be row_key:column_family:column_qualifier to easily access column values. Here are some potential cache key/value pairs you could use:rowkey: encoded rowstart_row_key-end_row_key: array of encoded rowsSQL queries: resultsrow prefix: array of encoded rowsWhen creating your cache, determine the setup based on your use case. Note that Bigtable rowkeys have a size limit of 4KB, whereas Memcached keys have a size limit of 250 bytes, so your rowkey could potentially be too large.Create a Memorystore for Memcached instanceI’ll create a Memorystore for Memcached instance, but you can install and run a local Memcached instance to try this out or for testing. These steps can be done with the Memorystore Cloud Console if you prefer.1. Enable the Memorystore for Memcached API.2. Create a Memorystore for Memcached instance with the smallest size on the default network. Use a region that is appropriate for your application.3. Get the Memcached instance details and get the discoveryEndpoint IP address (you may have to wait a few minutes for the instance to finish creation).Set up machine within networkWe need to create a place to run code on the same network as our Memcached instance. You can use a serverless option such as Cloud Functions, but a Compute VM requires less configuration.Create a compute instance on the default network with enabled API scopes for Cloud Bigtable data. Note that the zone must be in the same region as your Memcached instance.2. SSH into your new VM.Optionally connect to Memcached via TelnetThe Memorystore for Memcached documentation contains more information about this process, but you can just run the commands below to set and get a value in the cache. Run the codeNow we are ready to put our code on the machine. You can clone the repo directly onto the VM and run it from there. If you want to customize the code, check out my article on rsyncing code to Compute Engine or use the gcloud scp command to copy your code from your local machine to your VM.2. Install maven3. Set environment variables for your configuration.4. Run the program once to get the value from the database, then run it again and you’ll see that the value is fetched from the cache.CleanupIf you followed along with this blog post, delete your VM, Cloud Bigtable Instance, and Memcached instance with these commands to prevent getting billed for resources:Next steps Now you should understand the core concepts for putting a cache layer in front of your database and can integrate it into your existing application. Head to the Google Cloud console where you can try this with Cloud Bigtable and Cloud Memorystore.Related ArticleGo faster and cheaper with Memorystore for Memcached, now GALearn about fully managed Memorystore for Memcached, which is compatible with open-source Memcached protocol and can save database costs …Read Article
Quelle: Google Cloud Platform
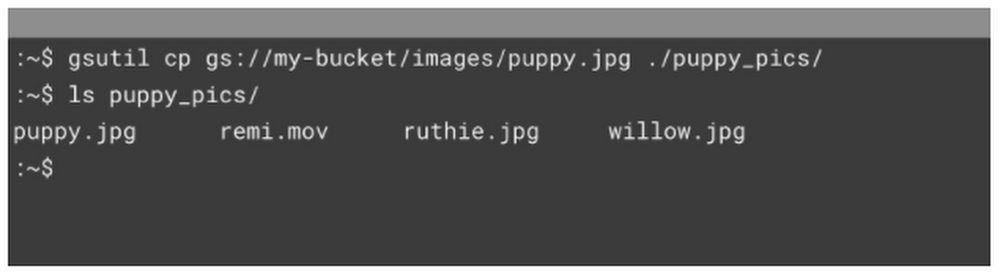
Prefer to listen rather than read? Check out this post on the podcast!When it comes to the cloud, there’s more than one way to serve a file. In this post, we’ll walk you through all the ways to serve data from Cloud Storage—so you can determine the best fit for your needs!You can use Cloud Storage to serve assets to your customers, and depending on your application, there are a variety of methods you might use to get that data out of a Cloud Storage bucket. In this post, we’ll cover four ways to serve those assets, but feel free to read more in the documentation, or for general, conceptual information on uploads and downloads, read this. Here we go!Client LibrariesFirst, we’ve got Client Libraries. If you need to download assets directly into your existing application, this is something for you to explore!And trust me when I say…we speak your language. With code samples in C++, C#, Go, Java, Node.js, PHP, Python, and Ruby—we’ve got you covered. Check out the documentation for more. Here’s an example of downloading from your Cloud Storage bucket using Python:gsutilUp next, you have the gsutil application. gsutil is a Python application that lets you access Cloud Storage from the command line. For our purposes, the cp command allows you to upload files from your local machine to google cloud. For example, running this command will download from a Cloud Storage bucket to a local path on your device.Additionally, gsutil comes with a plethora of options to configure to your specific use case; like the -m command, which allows for copy options to occur in parallel.REST APIsYou can also directly go to the REST APIS, using other programs like cURL to fetch your files directly and allowing the user to log in with OAuth. More on that here.Cloud ConsoleFinally, you can always access your objects right from the Cloud Console. Simply select the desired bucket, or object, and click “Download” in the handy “more actions” drop down menu. This is a great way to grab individual files when you’re debugging or going through things manually.Note: For some object types, selecting “Download” opens the object in the browser. To download these objects to your local computer, right-click on “Download” and select “Save Link As.”What’s Next?Retrieving files is really just the start, and you’ll want to make sure you’ve got a handle on controlling access – You know we’ve got another post for that, so stay tuned!Learn more about your storage options in Cloud Storage Bytes, or check out the documentationfor more information, including tutorials.Related Article5-ish ways to get your data into Cloud StorageSo you’ve created your buckets, and now you want to use the power of the cloud to serve your content. With a can-do attitude and the deta…Read Article
Quelle: Google Cloud Platform
Amazon Redshift Data Sharing, eine sichere und einfache Möglichkeit, Live-Daten über Redshift-Cluster hinweg zu teilen, ist jetzt allgemein verfügbar. Die gemeinsame Nutzung von Daten ermöglicht einen sofortigen, granularen und hochleistungsfähigen Datenzugriff über Amazon Redshift-Cluster innerhalb eines AWS-Kontos, ohne dass Daten kopiert oder verschoben werden müssen. Die gemeinsame Nutzung von Daten bietet einen Live-Zugriff auf die Daten, so dass Ihre Benutzer immer die aktuellsten und konsistentesten Informationen sehen, sobald diese im Data Warehouse aktualisiert werden. Die gemeinsame Nutzung von Daten kann auf Ihren Amazon Redshift RA3-Clustern ohne zusätzliche Kosten verwendet werden.
Quelle: aws.amazon.com
Amazon Redshift-Datenbankübergreifende Abfragen bieten die Möglichkeit, Abfragen über Datenbanken in einem Redshift-Cluster hinweg durchzuführen. Diese Funktion ist jetzt generell in allen Regionen verfügbar, in denen Amazon Redshift RA3-Knotentypen verfügbar sind. Mit datenbankübergreifenden Abfragen können Sie nahtlos Daten aus jeder Datenbank im Cluster abfragen, unabhängig davon, mit welcher Datenbank Sie verbunden sind. Datenbankübergreifende Abfragen können Datenexemplare eliminieren und Ihre Datenorganisation vereinfachen, um mehrere Geschäftsgruppen auf demselben Cluster zu unterstützen. Datenbankübergreifende Abfragen können ohne zusätzliche Kosten auf Ihren RA3-Clustern verwendet werden.
Quelle: aws.amazon.com
Amazon Elastic File System (Amazon EFS) unterstützt jetzt einzelne Availability Zone (AZ)-Speicherklassen (One Zone), wodurch die Speicherkosten im Vergleich zu Amazon EFS Standard-Speicherklassen um 47 % gesenkt werden, während die von den Kunden geschätzten EFS-Funktionen erhalten bleiben. Mit dieser Einführung können Sie einen effektiven Speicherpreis von 0,043 USD/GB-Monat erreichen.[1]
Quelle: aws.amazon.com
Amazon RDS for Oracle unterstützt jetzt Oracle Management Agent (OMA) Version 13.4. for Oracle Enterprise Manager (OEM) Cloud Control 13c Version 4 Update 9. OEM 13c bietet webbasierte Tools zur Überwachung und Verwaltung Ihrer Oracle-Datenbanken. Amazon RDS for Oracle installiert OMA, das daraufhin mit Ihrem Oracle Management Service (OMS) kommuniziert, um Überwachungsinformationen bereitzustellen. Kunden mit OMS 13.4 können nun Datenbanken durch die Installation von OMA 13.4 verwalten.
Quelle: aws.amazon.com