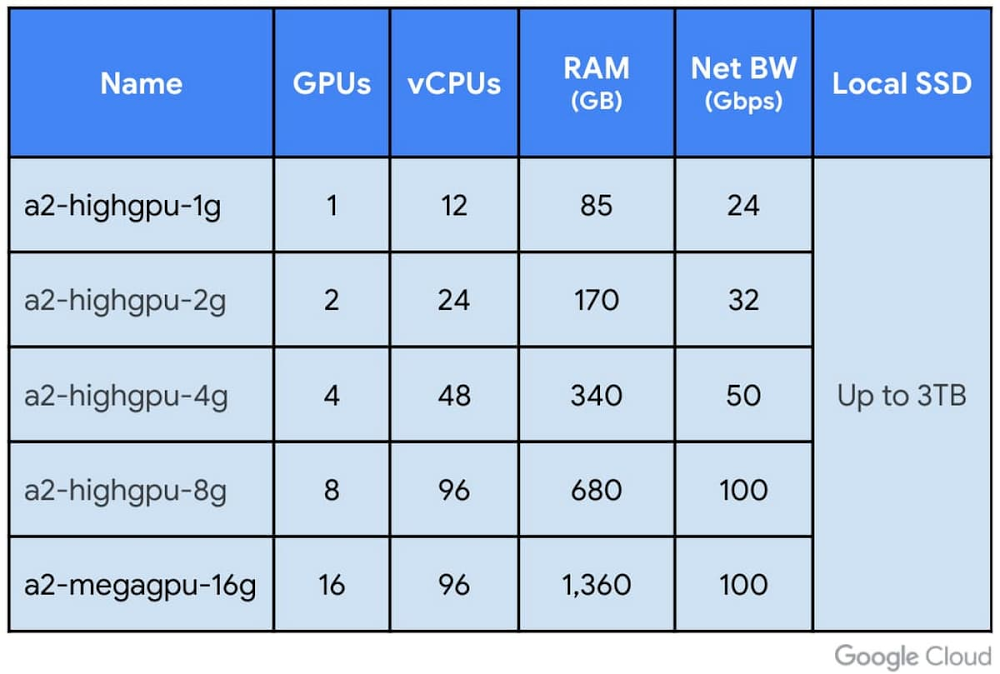
Today, we are excited to announce the general availability of A2 VMs based on the NVIDIA Ampere A100 Tensor Core GPUs in Compute Engine, enabling customers around the world to run their NVIDIA CUDA-enabled machine learning (ML) and high performance computing (HPC) scale-out and scale-up workloads more efficiently and at a lower cost. Our A2 VMs stand apart by providing 16 NVIDIA A100 GPUs in a single VM—the largest single-node GPU instance from any major cloud provider on the market today. The A2 VM also lets you choose smaller GPU configurations (1, 2, 4 and 8 GPUs per VM), providing the flexibility and choice you need to scale your workloads.A2 VM shapes on Compute EngineThe new A2-MegaGPU VM: 16 A100 GPUs with up to 9.6 TB/s NVIDIA NVlink BandwidthAt-scale performanceA single A2 VM supports up to 16 NVIDIA A100 GPUs, making it easy for researchers, data scientists, and developers to achieve dramatically better performance for their scalable CUDA compute workloads such as machine learning (ML) training, inference and HPC. The A2 VM family on Google Cloud Platform is designed to meet today’s most demanding HPC applications, such as CFD simulations with Altair ultraFluidX. For customers seeking ultra-large GPU clusters, Google Cloud supports clusters of thousands of GPUs for distributed ML training and optimized NCCL libraries, providing scale-out performance. The single VM shape offering with 16 A100 GPUs tied together with NVIDIA’s NVlink fabric is unique to Google Cloud and is not offered by any other cloud provider. Thus, if you need to scale up large and demanding workloads, you can start with one A100 GPU and go all the way up to 16 GPUs without having to configure multiple VMs for a single-node ML training. A2 VMs are also available in smaller configurations, offering the flexibility to match differing application needs along with up to 3 TB of Local SSD for faster data feeds into the GPUs. As a result, running the A100 on Google Cloud delivers more than 10X performance improvement on BERT Large pre-training model compared to the previous generation NVIDIA V100, all while achieving linear scaling going from 8 to 16 GPU shapes. In addition, developers can leverage containerized, pre-configured software available from NVIDIA’s NGC repository to get up and running quickly on Compute Engine A100 instances.What customers are sayingWe first made A2 VMs with A100 GPUs available to early access customers in July, and since then, have worked with a number of organizations pushing the limits of machine learning, rendering and HPC. Here’s what they had to say:Dessa, an artificial intelligence (AI) research firm recently acquired by Square was an early user of the A2 VMs. Through Dessa’s experimentations and innovations, Cash App and Square are furthering efforts to create more personalized services and smart tools that allow the general population to make better financial decisions through AI.“Google Cloud gave us critical control over our processes,” said Kyle De Freitas, a senior software engineer at Dessa. “We recognized that Compute Engine A2 VMs, powered by the NVIDIA A100 Tensor Core GPUs, could dramatically reduce processing times and allow us to experiment much faster. Running NVIDIA A100 GPUs on Google Cloud’s AI Platform gives us the foundation we need to continue innovating and turning ideas into impactful realities for our customers.”HyperConnect is a global video technology company in video communication (WebRTC) and AI. With a mission of connecting people around the world to create social and cultural values, Hyperconnect creates services based on various video and artificial intelligence technologies that connect the world.“A2 instances with new NVIDIA A100 GPUs on Google Cloud provided a whole new level of experience for training deep learning models with a simple and seamless transition from the previous generation V100 GPU. Not only did it accelerate the computation speed of the training procedure more than twice compared to the V100, but it also enabled us to scale up our large-scale neural networks workload on Google Cloud seamlessly with the A2 megagpu VM shape. These breakthroughs will help us build better models for enhancing the user experience on Hyperconnect’s services.” – Beomsoo Kim, ML Researcher, HyperconnectDeepMind(an Alphabet subsidiary) is a team of scientists, engineers, machine learning experts and more, working together to advance the state of the art in AI.“At DeepMind, our mission is to solve intelligence, and our researchers are working on finding advances to a variety of Artificial Intelligence challenges with help from hardware accelerators that power many of our experiments. By partnering with Google Cloud, we are able to access the latest generation of NVIDIA GPUs, and the a2-megagpu-16g machine type helps us train our GPU experiments faster than ever before. We’re excited to continue working with Google Cloud to develop and build future ML and AI infrastructure.” – Koray Kavukcuoglu, VP of Research, DeepMindAI2 is a non-profit research institute founded with the mission of conducting high-impact AI research and engineering in service of the common good. “Our primary mission is to push the boundaries of what computers can do, which poses two big challenges: modern AI algorithms require massive computing power, and hardware and software in the field changes quickly; you have to keep up all the time. The A100 on GCP runs 4x faster than our existing systems, and does not involve major code changes. It’s pretty much plug and play. At the end of the day, the A100 on Google Cloud gives us the ability to do drastically more calculations per dollar, which means we can do more experiments, and make use of more data.” – Dirk Groeneveld, Senior Engineer, Allen Institute for Artificial IntelligenceOTOY is a cloud graphics company, pioneering technology that is redefining content creation and delivery for media and entertainment organizations around the world.“For nearly a decade we have been pushing the boundary of GPU rendering and cloud computing to get to the point where there are no longer constraints on artistic creativity. With Google Cloud’s NVIDIA A100 instances featuring massive VRAM and the highest OctaneBench ever recorded, we have reached a first for GPU rendering – where artists no longer have to worry about scene complexity when realizing their creative visions. OctaneRender GPU-accelerated rendering democratized visual effects enabling anyone with an NVIDIA GPU to create high-end visual effects on par with a Hollywood studio. Google Cloud’s NVIDIA A100 instances are a major step in further democratizing advanced visual effects, giving any OctaneRender and RNDR users on-demand access to state of the art NVIDIA GPUs previously only available in the biggest Hollywood studios” – Jules Urbach, Founder and CEO, OTOY.GPU pricing and availabilityNVIDIA A100 GPU instances are now available in the following regions: us-central1, asia-southeast1 and europe-west4 with additional regions slated to come online throughout 2021. A2 Compute Engine VMs are available via on-demand, preemptible and committed usage discounts and are also fully supported on Google Kubernetes Engine (GKE), Cloud AI Platform, and other Google Cloud services. A100 GPUs are available for as little as $0.87 per hour per GPU on our preemptible A2 VMs. You can find full pricing details here. Getting started You can get up and running quickly, start training ML models, and serving inference workloads on NVIDIA A100 GPUs with our Deep Learning VM images in any of our available regions. These images include all the software you’ll need: drivers, NVIDIA CUDA-X AI libraries, and popular AI frameworks like TensorFlow and PyTorch. Our pre-built and optimized TensorFlow Enterprise Images also support A100 optimizations for current and older versions of TensorFlow (1.15, 2.1, and 2.3). We handle all software updates, compatibility, and performance optimizations, so you don’t have to think about it. Check out our GPU page to learn more about the wide selection of GPUs available on Google Cloud.Related ArticleNew Compute Engine A2 VMs—first NVIDIA Ampere A100 GPUs in the cloudGoogle Cloud’s new Accelerator-Optimized (A2) VM family is based on the NVIDIA Ampere A100 GPU, and designed for demanding HPC and ML wor…Read Article
Quelle: Google Cloud Platform