TV: Sony bringt viele neue LCD- und OLED-Fernseher für 2021
Die neuen Bravia-Modelle lösen mit 4K oder auch 8K auf. Kernstück ist ein XR-Bildprozessor, der die Darstellung verbessern soll. (Fernseher, Display)
Quelle: Golem

Die neuen Bravia-Modelle lösen mit 4K oder auch 8K auf. Kernstück ist ein XR-Bildprozessor, der die Darstellung verbessern soll. (Fernseher, Display)
Quelle: Golem

Twitter hat erstmals den Account von US-Präsident Trump gesperrt. Facebook und Youtube löschten ein Video hingegen direkt. (Donald Trump, Soziales Netz)
Quelle: Golem

Waymo-Chef John Krafcik hat die Herausforderungen des autonomen Fahrens unterschätzt. Nun will er bescheidener geworden sein. (Waymo, Google)
Quelle: Golem

Intel und Qualcomm bieten besonders sparsame Chips für Ultrabooks an, wir haben beide zum Akku- und Performance-Test antreten lassen. Ein Test von Marc Sauter (Snapdragon, Intel)
Quelle: Golem

Die 2021-Edition des ungewöhnlichen Fernsehers wird noch einmal dünner sein. Samsung setzt weiterhin auf QLED und ein Kunstwerkabo. (Fernseher, Display)
Quelle: Golem

General Motors soll Auftragsfertiger für Honda werden und künftig die Elektroautos des japanischen Herstellers mit Ultium-Akkus bauen. (General Motors, Technologie)
Quelle: Golem
For the past couple years, we’ve been working to make Google Cloud an excellent platform for running C++ workloads. To demonstrate some of the progress we’ve made so far, we’ll show how you can use C++ with both Cloud Pub/Sub and Cloud Storage to build a highly scalable job queue running on Google Kubernetes Engine (GKE).Such applications often need to distribute work to many compute nodes to achieve good performance. Part of the appeal of public cloud providers is the ability to schedule these kinds of parallel computations on demand, growing the size of the cluster that runs the computation as needed, and shrinking it when it’s no longer running. In this post we will explore how to realize this potential for C++ applications, using Pub/Sub and GKE.A common pattern for running large-scale computations is a job queue, where work is represented by messages in the queue, and a number of worker applications pull items from the queue for processing. The recently released Pub/Sub (CPS) C++ client library makes it easy to implement this pattern. And with GKE autoscaling, the cluster running such a workload can grow and shrink on demand, saving C++ developers from the tedium of managing the cluster, and leaving them with more time to improve their applications.Sample applicationFor our example, we will create millions of Cloud Storage objects; this models a parallel application that performs some computation (e.g., analyze a fraction of some large data set) and saves the results in separate Cloud Storage objects. We believe this workload is easier to understand than some exotic simulation, but it’s not purely artificial: from time-to-time our team needs to create large synthetic data sets for load testing.OverviewThe basic idea is to break the work into a small number of work items, such as, “create 1,000 objects with this prefix”. We use a command-line tool to publish these work items to a Pub/Sub topic, which reliably delivers them to any number of worker nodes that execute the work items. We use GKE to run the worker nodes, as GKE automatically scales the cluster based on demand, and restarts the worker nodes if needed after a failure. Because Pub/Sub offers at-least-once delivery, and because the worker nodes may be restarted by GKE, it’s important to make these work items idempotent, that is, executing the work item multiple times produces the same objects in Cloud Storage as executing the work item a single time.The code for this example is available in this GitHub repository.Posting the work itemsA simple C++ struct represents the work item:Converting this struct to a Pub/Sub message takes only a few lines of code:Since the messages are posted using a Publisher, there’s no need to batch messages, or retry them, as the library takes care of these details:Reading the work itemsTo read the work items, create a Subscriber and associate a callback with it. We configure the subscription to only read a few messages at a time, as we prefer to keep the messages on the Pub/Sub service until the application is ready to act on the message.If the application running this function crashes, or needs to be rescheduled by GKE, the Pub/Sub service re-delivers the messages to a new instance. This produces the same results, as the process_one_item() function produces the same output, even if called multiple times:Compiling the applicationThe GitHub repository includes the necessary CMake and Docker scripts to compile this code into a Docker image. We use Cloud Build to run the build, freeing our workstations to do useful work (and definitely not for playing video games):The first time you run that command it might take a while, as this builds all the dependencies from source. The intermediate results are cached, and used to save time in subsequent runs.Deploying to GKEOnce the Docker image is created, you can deploy the application to a previously created GKE cluster. We use a script to generate the yaml file:And then you instruct GKE to autoscale as needed:This starts at least one replica of the application in the GKE cluster, and configures the cluster to create additional replicates (up to 200) if their CPU load is over 50%. SummaryUsing Pub/Sub as a work queue can simplify the implementation of parallel C++ applications. Pub/Sub distributes the work items across applications, retries them when a worker node terminates unexpectedly, and/or scales up as the number of worker nodes increases. Furthermore, you can deploy the worker nodes to GKE, which automatically takes care of finding or creating free virtual machines to run your worker application, scheduling your worker application in these virtual machines, and increasing or reducing the number of compute nodes as needed. If your C++ application has a lot of small work items and these can be made idempotent, consider using Pub/Sub and GKE for task scheduling.To try these techniques in your own environment, just download the example from GitHub. Or just browse the code and use them in your own applications!
Quelle: Google Cloud Platform
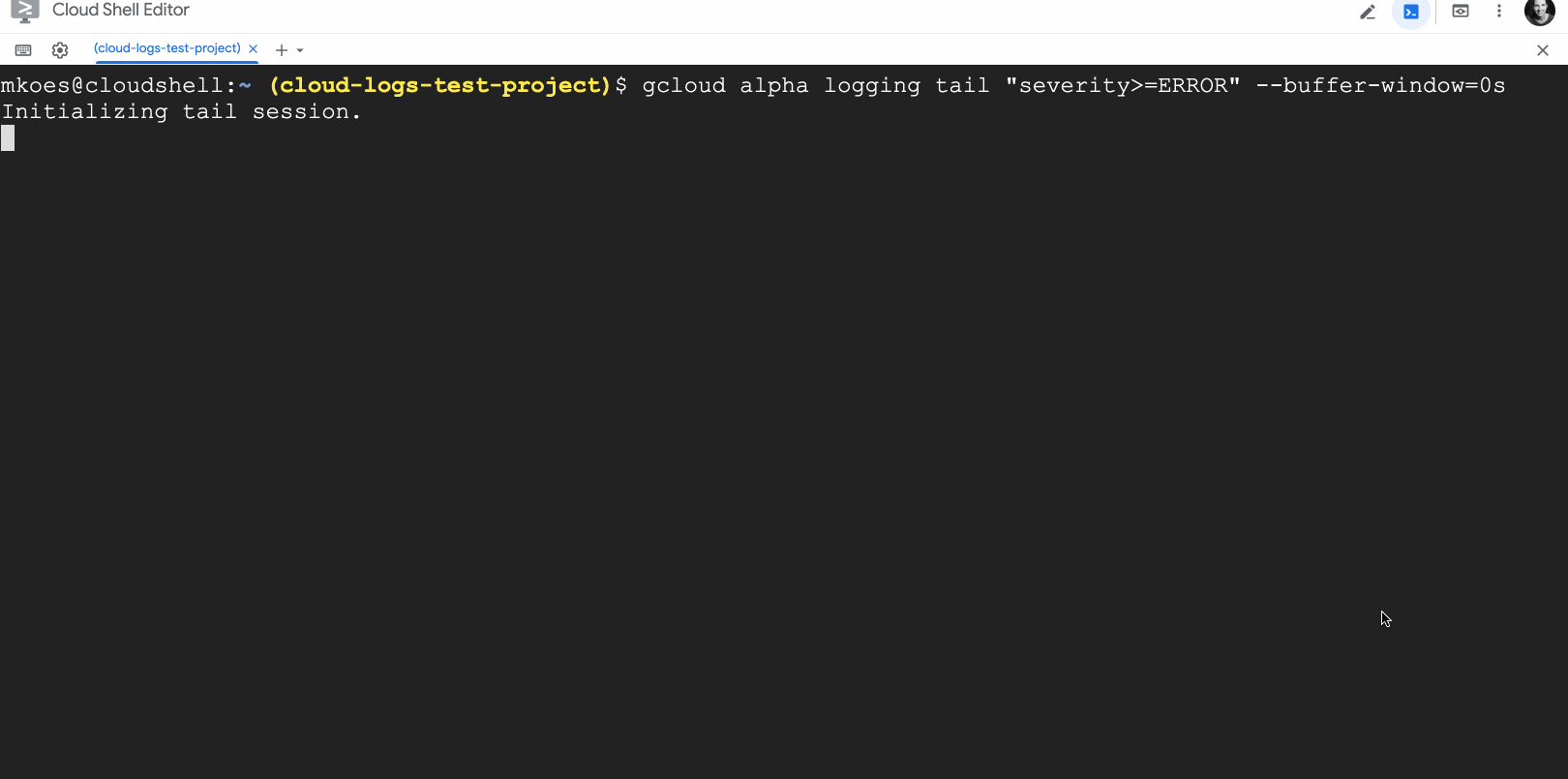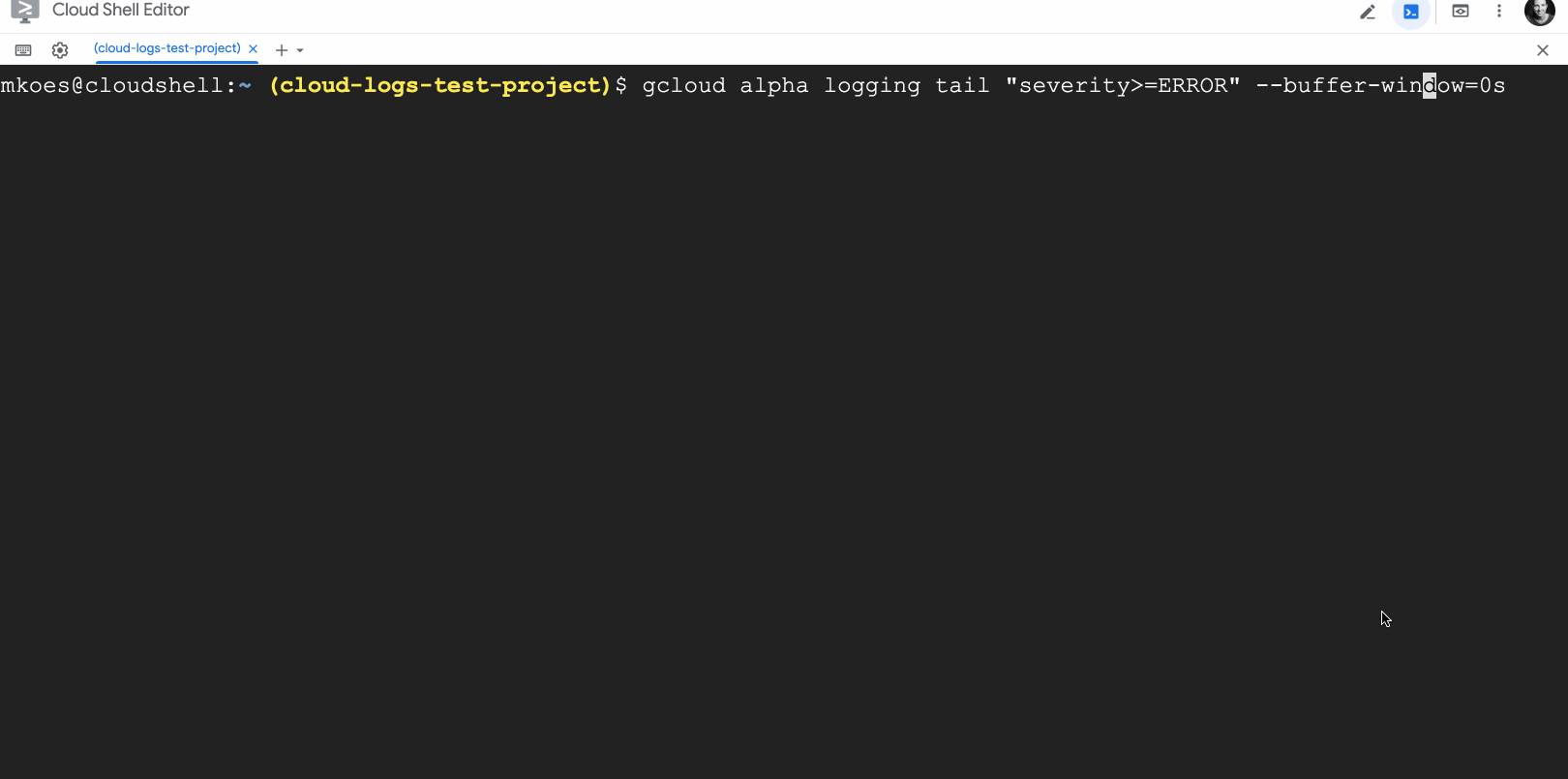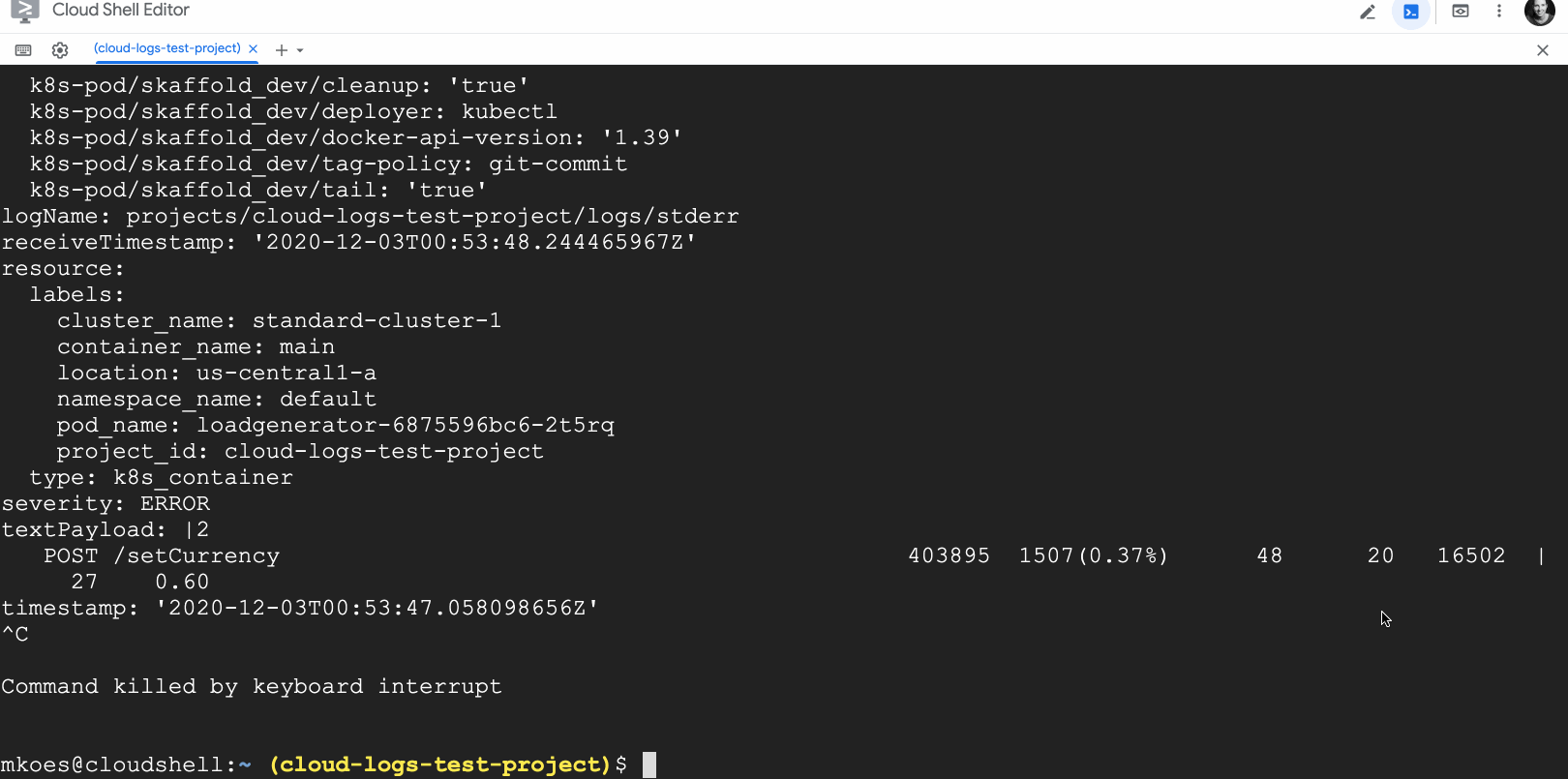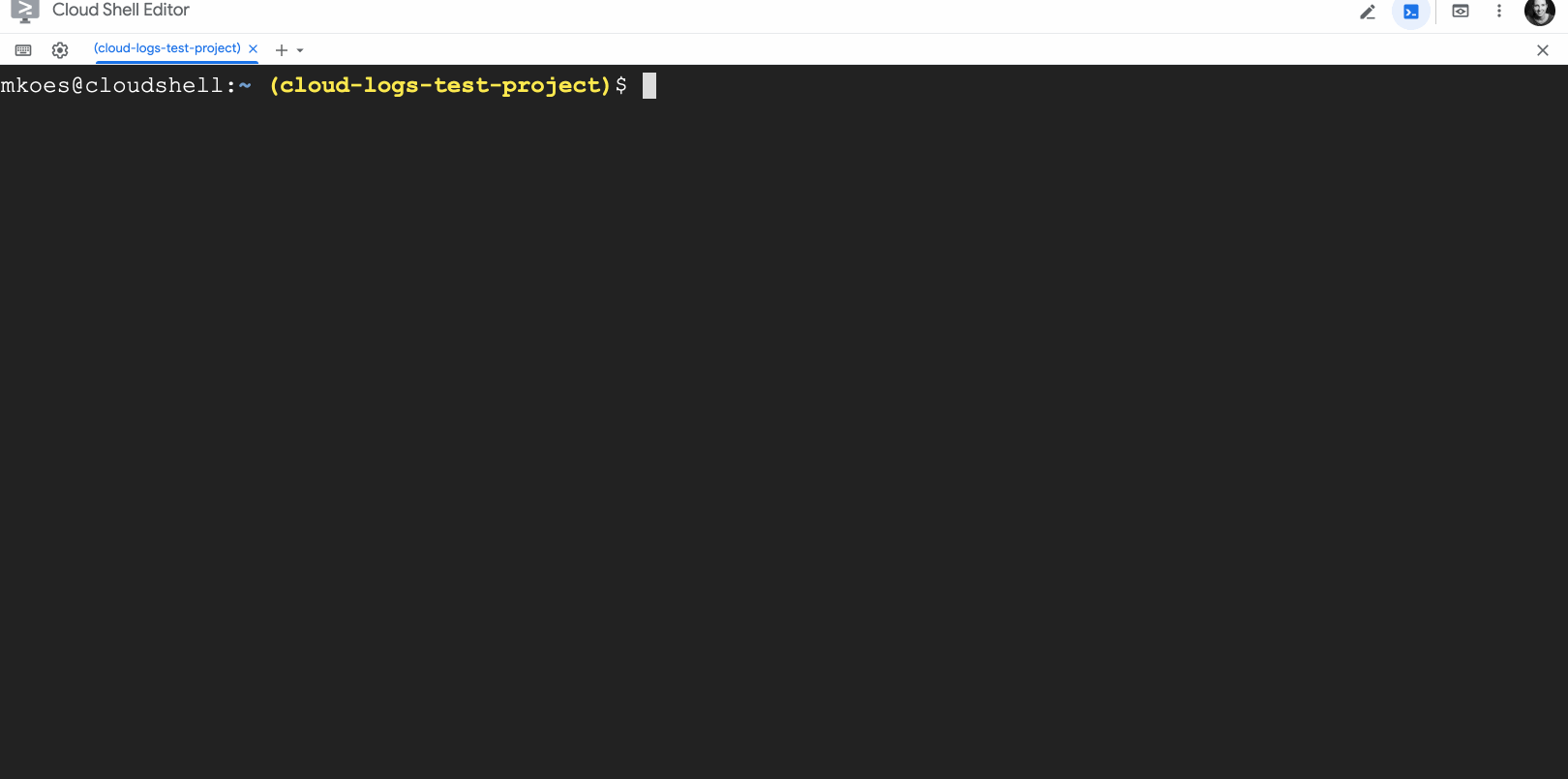
When you’re troubleshooting an app or a deployment, every second counts! Cloud Logging helps you troubleshoot by aggregating logs from across Google Cloud, on-premises or other clouds, indexing, aggregating logs into metrics, scanning for unique errors with Error Reporting and making logs available for search, all in less than a minute. And now, we’ve built two new features for streaming logs to give you even fresher insights from your logs data.By popular demand from Linux users, we added a new tool to mimic the behavior of the tail -f command, which allows you to display the contents of a log file to the console in real time. We’ve also included upgrades beyond the well-loved tail tool such as searching across all logs from all your resources at once and the ability to use Cloud Logging’s powerful logging query language including global search, regular expressions, substring matches, etc., all still in real-time. You can use the logging query language with the new live feature to find information in your logs in real-time. For example, let’s say you just deployed a new application and want to look at all error logs:gcloud alpha logging tail “severity>=ERROR”But this returns too many results so you narrow the scope to just logs that include the text “currency”:gcloud alpha logging tail “severity>=ERROR AND currency”This search returns a meaningful set of logs, all still in real time.Tailing logs with gcloud is now available to all users in Preview. Head over to our docs to get it set up and start tailing.And if you prefer using Google Cloud Console, we’ve got great news for you as well. You can now stream logs to Logs Explorer as well as easily stream, pause, explore, link to traces, resume streaming, visualize counts and download logs, all from the Cloud Console.So whether you prefer command line tail -f or a dedicated user experience for exploring logs, check out Cloud Logging’s new tools and save time troubleshooting.Related ArticleTroubleshooting your apps with Cloud Logging just got a lot easierLearn how to use the Logs Explorer feature in Cloud Logging to troubleshoot your applicationsRead Article
Quelle: Google Cloud Platform
Der neueste Track von APN Navigate für alle AWS-Partner, der ISV-Partnerpfad von APN Foundations, ist jetzt verfügbar. Dieser Track führt AWS-Partner durch Best Practices, um ein AWS-Geschäft durch das AWS Cloud Adoption Framework auszubauen, AWS Best Practices zu implementieren und AWS-verifizierte Lösungen bei Kunden durch Partnerprogramme zu bewerben, die den Geschäftsanforderungen des Partners am besten entsprechen.
Quelle: aws.amazon.com
APN Navigates neuester Track für alle AWS-Partner, APN Foundations Advanced, ist jetzt verfügbar. Dieser Track ermöglicht es APN Select Tier-Partnern, APN Advanced Tier als Beratungs- oder Technologiepartner zu erreichen. Sie finden ihn in APN Partner Central in Ihrer vorhandenen APN Navigate Foundations Toolbox.
Quelle: aws.amazon.com