Our “State of the API Economy 2021” report indicates that despite the many financial pressures and disruptions wrought by COVID-19, 75% of companies continued focusing on their digital transformation initiatives, and almost two-thirds of those companies actually increased their investments and efforts.Because APIs are how software talks to software and how developers leverage data and functionality in different systems, they are at the center of these digital transformation initiatives. As organizations across the world have shifted how they do business, IT organizations have scrambled to meet demands for new applications—and to do more with APIs. API analytics usage is seeing an explosive growthLeading businesses use API analytics to not only inform new strategies but also align leadership goals and outcomes. Because executive sponsors tend to support initiatives that produce tangible results, teams can use API metrics to unite leaders around digital strategies and justify continued platform-level funding for the API program. This demand is responsible for surging API analytics usage. Among Apigee customers, API analytics adoption increased by 75% from 2019 to 2020—growth that reflects organizations’ broader need to holistically assess the business and digital transformation impacts of API programs.API analytics point to opportunities To remain competitive in today’s hyper-connected world, one key question needs to be answered: “How do we drive impact with our digital initiatives while also making sure we’re putting our limited resources to the best use?“ API analytics support API providers in this endeavor by helping them to determine which digital assets are key drivers of business value and to create a strategic view of digital interactions. By tracking which APIs are being consumed by certain communities of developers, which APIs are powering the most popular apps, and how performant APIs are, organizations can understand which digital assets need optimization or iteration, which digital assets are being leveraged for new uses or by new communities, which digital assets are driving revenue, and more. Beyond helping enterprises answer questions they’ve already identified, API analytics also surface patterns that may be unexpected—and that help both IT and business leaders refine the KPIs they use analytics to generate. If an API becomes popular with developers in a new vertical for example, that may persuade the enterprise to focus on KPIs like adoption among these specific developers, rather than on overall adoption. Best Practices for defining effective API metricsWhen our survey respondents were asked how API usage at their company is currently measured, top responses included metrics focused on API performance (35%), on traditional IT-centric numbers (22%), and on consumption of APIs (21%). But when asked about preference for API measurement, business impact topped the list (43%). The data suggests that API effectiveness metrics vary across geography and industry, with measurement by business impact or API performance serving as a collective north star.Establishing a framework to connect digital investments directly to metrics and key performance indicators (KPIs) is among the most important areas of strategic alignment for ensuring a successful API strategy. Successful programs clearly define and measure a combination of business metrics, such as direct or indirect revenue, and API consumption metrics, such as API traffic, the number of apps built atop given APIs, and the number of active developers leveraging APIs. Good KPIs are a cornerstone of an effective API analytics effort, but they can be difficult to define. Here are some effective KPIs to help position an API program for success.Operational KPIsAverage and max call latency: P1 latency, or elapsed time, is an important metric that impacts customer experiences. Breaking down this KPI into detailed metrics (e.g., networking times, server process and upload and download speeds) can help provide additional insights for measuring the performance of APIs–and thus of the apps that rely on them.Total pass and error rates: Measuring success rates in terms of the number of API calls that trigger non-200 status codes can help organizations to track how buggy or error-prone an API is. In order to track total pass and error rates, it’s important to understand what type of errors are surfacing during API usage.API SLA: While one of the most basic metrics, API Service Level Agreements (SLA) is the gold standard for measuring the availability of a service. Many enterprise SLAs leave software providers little-to-no room for error. Providing this level of service means a provider’s upstream APIs need to be running–and that requires API monitoring and analytics to maintain performance and quickly troubleshoot any problems. Adoption KPIsDevelopers: This target is commonly intended to improve API adoption. Enterprises should consider using this metric in combination with other metrics that confirm a given API’s business utility.Onboarding: The portal that application developers use to access APIs should ideally feature an automated approval process, including self-service onboarding capabilities that let users register their apps, obtain keys, access dashboards, discover APIs, and so on. The ease and speed with which developers can navigate this process can significantly impact the adoption of an enterprise’s API program. Just as consumers are unlikely to adopt a service if too much friction is involved, developers are less likely to adopt APIs that cannot be easily and securely accessed. API traffic: This target can help API programs develop a strong DevOps culture by continuously monitoring, improving, and driving value through APIs. Enterprises should consider coupling this target with related metrics up and down the value chain, including reliability and scalability of back-ends.API product adoption: Retention and churn can identify key patterns in API adoption. A product with high retention is closer to finding its market fit than a product with a churn issue, for example. Unlike subscription retention, product retention tracks the actual usage of a product such as an API. Business Impact KPIsDirect and indirect revenue: These targets track the different ways APIs contribute to revenue. Some APIs provide access to particularly rare and valuable datasets or particularly useful and hard-to-replicate functionality—and in these cases, enterprises sometimes directly monetize APIs, offering them to partners and external developers as paid services/products. Often, however, an API can generate more value if enterprises focus on adoption rather than upfront revenue. A retailer won’t make much money charging partners for access to a store locator API, for example, but if they make the API freely available, partners are more likely to use it to add functionality to their apps and the retailer is more likely to benefit because its business is exposed to more people through more digital experiences. It is important to be able to track both direct revenue from monetized APIs and forms of indirect value, such as how adoption of an API among certain developers supports those developers’ revenue-generating apps. Likewise, it is important to be able to adjust pricing models to find the right blend; analytics can reveal, for example, whether an API is most valuable if offered for free, if offered for a flat subscription rate, or if offered in a “freemium” model with free base access and paid tiers. Partners: This target can be used to accelerate partner outreach, drive adoption, and demonstrate success to existing business units.Cost: Enterprises can reduce costs by reusing APIs rather than initiating new custom integration efforts for each new project. When internal developers use standardized APIs to connect to existing data and services, the APIs become digital assets that can be leveraged again and again for new use cases, typically with little if any overhead costs. By tracking API usage, enterprises can identify instances in which expense that otherwise would have gone to new integration projects has been eliminated thanks to reusable APIs. Likewise, because APIs automate and accelerate many processes, enterprises can identify how specific APIs contribute to faster development cycles and faster completion of business processes–and how many resources are saved in the process. API analytics is at the core of successful API programsComprehensive monitoring and robust analytics efforts for API programs are among the most important ways to make data-driven business decisions. For an enterprise unsure how to scale its API program or uncertain about which next steps to take, analytics may literally be the difference-maker, providing insights that illuminate previously hidden opportunities, remove ambiguity, drive consensus, and help the business grow.Citrix is among the Google Cloud customers using Apigee’s monitoring and analytics solutions to proactively monitor the performance, availability, and security health of their APIs. “Apigee has a lot of built-in analytics that run automatically on every API, and Citrix can track any custom metric it wants. We’re gaining real-time visibility into our APIs, and that is helping us grow a strong API program for both internal and external developers.” says Adam Brancato, senior manager of customer apps at Citrix. When monitoring and analytics tools are integrated directly, rather than bolted on, the platform managing APIs is the same platform capturing data—which means the data can be acted on more easily and in near-real time. A full lifecycle API management solution such as Apigee provides near real-time monitoring and analytics insights that enable API teams to measure the health, usage, and adoption of their API, while also offering the ability to diagnose and resolve problems faster. The solution also enables teams to keep abreast of all essential aspects of their API-powered digital business.Want to learn more? The “State of API Economy 2021*” report describes how digital transformation initiatives evolved throughout 2020, as well as where they’re headed in the years to come. Read the full report*This report is based on Google Cloud’s Apigee API Management Platform usage data, Apigee customer case studies, and analysis of several third-party surveys conducted with technology leaders from enterprises with 1,500 or more employees, across the United States, United Kingdom, Germany, France, South Korea, Indonesia, Australia, and New Zealand.Related ArticleTop 5 trends for API-powered digital transformation in 2021Google Cloud’s State of APIs report investigates digital transformation in 2020 and where trends point in 2021 and beyond.Read Article
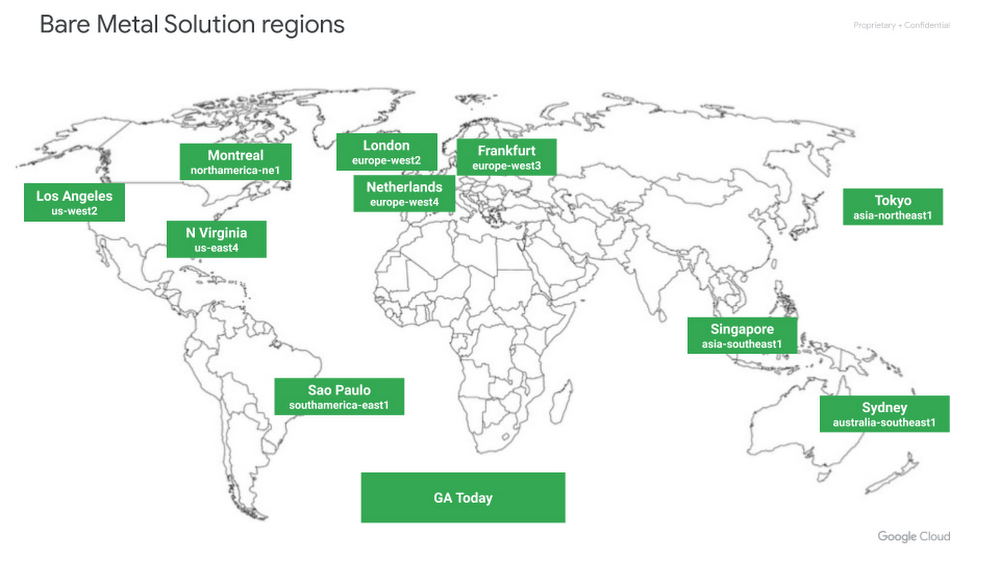
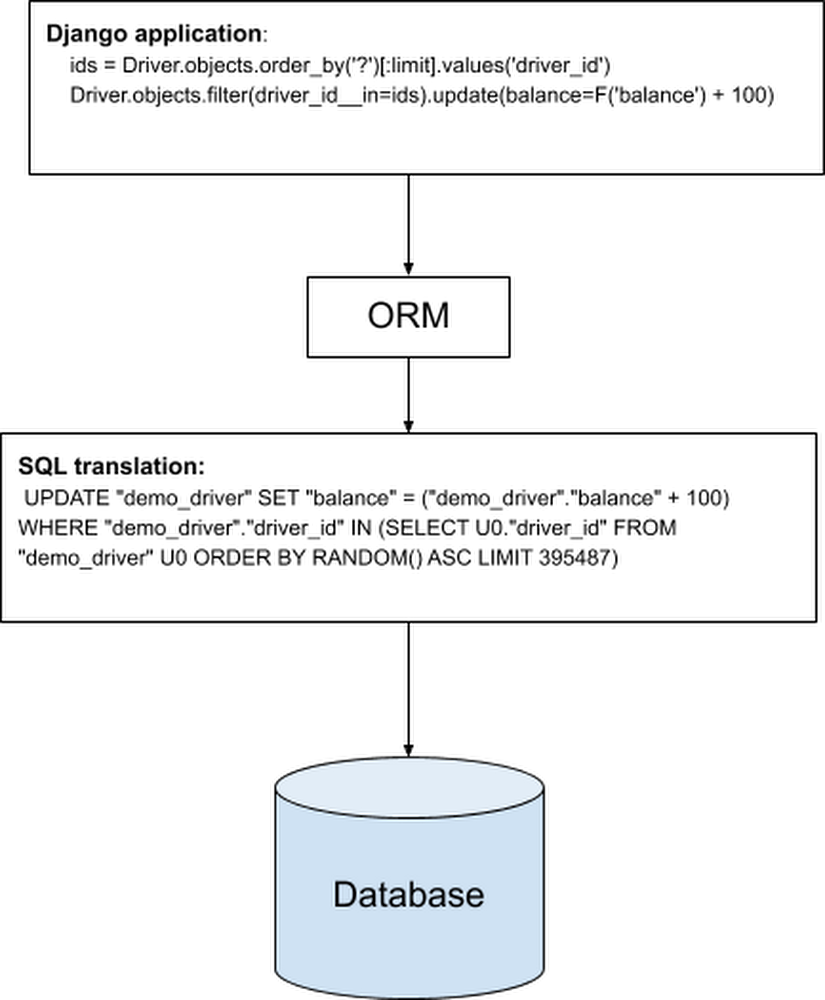
Quelle: Google Cloud Platform