Elektroauto: Elon Musk wollte Tesla an Apple verkaufen
Elon Musk hat verraten, dass er vor nicht allzu langer Zeit vorhatte, Tesla für einen Bruchteil des aktuellen Wertes an Apple zu verkaufen. (Apple, Technologie)
Quelle: Golem

Elon Musk hat verraten, dass er vor nicht allzu langer Zeit vorhatte, Tesla für einen Bruchteil des aktuellen Wertes an Apple zu verkaufen. (Apple, Technologie)
Quelle: Golem

Prinoth hat mit dem Leitwolf H2Motion eine Pistenraupe mit Brennstoffzelle vorgestellt. Mit einer Betankung sind vier Stunden Betrieb möglich. (Brennstoffzelle, Technologie)
Quelle: Golem
eng.uber.com – Apache Kafka at Uber Uber has one of the largest deployments of Apache Kafka in the world, processing trillions of messages and multiple petabytes of data per day. As Figure 1 shows, today we positio…
Quelle: news.kubernauts.io
learncloudnative.com – Init containers allow you to separate your application from the initialization logic and provide a way to run the initialization tasks such as setting up permissions, database schemas, or seeding dat…
Quelle: news.kubernauts.io
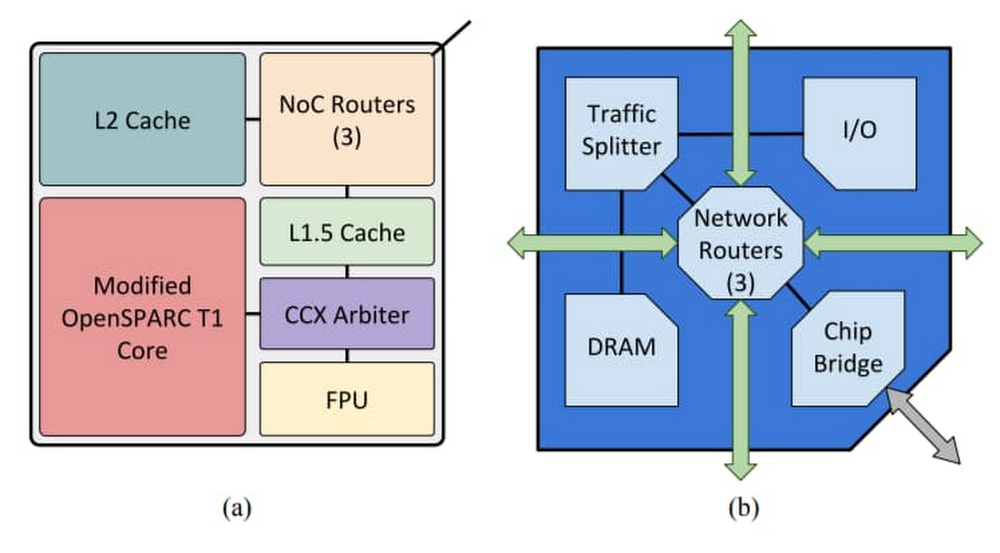
Companies embark on modernizing their infrastructure in the cloud for three main reasons: 1) to accelerate product delivery 2) to reduce system downtime and 3) to enable innovation. Chip designers with Electronic Design Automation (EDA) workloads share these goals, and can greatly benefit from using cloud. Chip design and manufacturing includes several tools across the flow, with varied compute and memory footprints. Register Transfer Level (RTL) design and modeling is one of the most time consuming steps in the design process, accounting for more than half the time needed in the entire design cycle. RTL designers use Hardware Description Languages (HDL) such as SystemVerilog and VHDL to create a design which then goes through a series of tools. Mature RTL verification flows include static analysis (checks for design integrity without use of test vectors), formal property verification (mathematically proving or falsifying design properties), dynamic simulation (test vector-based simulation of actual designs) and emulation (a complex system that imitates the behavior of the final chip, especially useful to validate functionality of the software stack).Dynamic simulation arguably takes up the most compute in any design team’s data center. We wanted to create an easy set up using Google Cloud technologies and open-source designs and solutions to showcase three key points:How simulation can accelerate with more computeHow verification teams can benefit from auto-scaling cloud clustersHow organizations can effectively leverage the elasticity of cloud to build highly utilized technology infrastructureOpenPiton Tile architecture(a) and Chipset Architecture(b)Source: OpenPiton: An Open Source Manycore Research Framework, Balkind et alWe did this using a variety of tools: We used the OpenPiton design verification scripts, Icarus Verilog Simulator, SLURM workload management solution and Google Cloud standard compute configurations.OpenPiton is the world’s first open-source, general-purpose, multithreaded manycore processor and framework. Developed at Princeton University, it’s scalable and portable and can scale up to 500-million cores. It’s wildly popular within the research community and comes with scripts for performing the typical steps in the design flow, including dynamic simulation, logic synthesis and physical synthesis.Icarus Verilog, sometimes known as iverilog, is an open-source Verilog simulation and synthesis tool. Simple Linux Utility for Resource Management or SLURM is an open-source, fault-tolerant and highly scalable cluster management and job scheduling system for Linux clusters. SLURM provides functionality such as enabling user access to compute nodes, managing a queue of pending work, and a framework for starting and monitoring jobs. Auto-scaling of a SLURM cluster refers to the capability of the cluster manager to spin up nodes on demand and shut down nodes automatically after jobs are completed.SLURM Components. Source: slurm.schedmd.com/quickstart.htmlSetupWe used a very basic reference architecture for the underlying infrastructure. While simple, it was sufficient to achieve our goals. We used standard N1 machines (n1-standard-2 with 2 vCPUs, 7.5 GB memory), and set up the SLURM cluster to auto-scale to 10 compute nodes. The reference architecture is shown here. All required scripts are provided in this github repo.Running the OpenPiton regressionThe first step in running the OpenPiton regression is to follow the steps outlined in the github repo and complete the process successfully. The next step is to download the design and verification files. Instructions are provided in the github repo. Once downloaded, there are three simple setup tasks to perform:Set up the PITON_ROOT environment variable (%export PITON_ROOT=<location of root of OpenPiton extracted files>) Set up the simulator home (%export ICARUS_HOME=/usr). The scripts provided to you in the github repo already take care of installing Icarus on the machines provisioned. This shows yet another advantage of cloud: simplified machine configuration.Finally, source your required settings (%source $PITON_ROOT/piton/piton_settings.bash)For the verification run, we used the single tile setup for OpenPiton, the regression script ‘sims’ provided in the OpenPiton bundle and the ‘tile1_mini’ regression. We tried two runs—sequential and parallel. The parallel runs were managed by SLURM.We invoked the sequential run using the following command:%sims -sim_type=icv -group=tile1_miniAnd the distributed run using this command:%sims -sim_type=icv -group=tile1_mini -slurm -sim_q_command=sbatchResults The ‘tile1_mini’ regression has 46 tests. Running all 46 tile1_mini tests sequentially took an average of 120 minutes. The parallel run for tile1_mini with 10 auto-scaled SLURM nodes completed in 21 minutes—a 6X improvement!View of VM instances on GCP console; node instances edafarm-compute0-<0-9> are created when the regression is launchedView of VM instances on GCP console when the regression was winding down; notice that the number of nodes has decreasedFurther, we wanted to also highlight the value of autoscaling. The SLURM cluster was set up with two static nodes, and 10 dynamic nodes. The dynamic nodes were up and active quite soon after the distributed run was invoked. Since the nodes are shut down if there are no jobs, the cluster auto-scaled to 0 nodes after the run was complete. The additional cost of the dynamic nodes for the time of the simulation was $8.46.Report generated to view compute utilization of SLURM nodes; notice the high utilization of the top 5 nodesThe cost of the extra compute can also be easily viewed by the several existing reports on GCP consoleThe above example shows a simple regression run, with very standard machines. By providing the capability to scale to more than 10 machines, further improvements in turnaround time can be achieved. In real-life, it is common for project teams to run millions of simulations. By having access to elastic compute capacity, you can dramatically reduce the verification process and shave months off verification sign-off. Other considerationsTypical simulation environments use commercial simulators that extensively leverage multi-core machines and large compute farms. When it comes to Google Cloud infrastructure, it’s possible to build many different machine types (often referred to as “shapes”) with various numbers of cores, disk types, and memory. Further, while a simulation can only tell you whether the simulator ran successfully, verification teams have the subsequent task of validating the results of a simulation. Elaborate infrastructure that captures the simulation results across simulation runs—and provides follow-up tasks based on findings—is an integral part of the overall verification process. You can use Google Cloud solutions such as Cloud SQL and BigTable to create a high-performance, highly scalable and fault-tolerant simulation and verification environment. Further, you can use solutions such as AutoML Tables to infuse ML into your verification flows.Interested? Try it out!All the required scripts are publically available—no cloud experience is necessary to try them out. Google Cloud provides everything you need, including free Google Cloud credits to get you up and running. Click here to learn more about high performance computing (HPC) on Google Cloud.Related ArticleHPC made easy: Announcing new features for Slurm on GCPScheduling HPC workloads on GCP just got easier, with new integrations to the Slurm HPC workload manager.Read Article
Quelle: Google Cloud Platform
Cloud Spanner has had a busy year. We’ve rolled out more enterprise features, including managed backup and restore, local emulator, and numerous multi-region configurations. It’s easier than ever to test and deploy applications across multiple regions without manual sharding, downtime, or patching, and with an industry-leading SLA of 99.999%.In addition to enterprise features, we continued our focus on making developers more productive. Earlier this year we launched foreign keys, C++ client library, query optimizer, and various introspection features. In this post, we’ll discuss three recently launched Spanner features: check constraints, generated columns, and NUMERIC data type. We launched these features to boost your productivity when building an application on Spanner. Read on for a brief description of each feature, and an example of how check constraints and generated columns can be combined to provide additional referential integrity to your application. Check constraintsA check constraint allows you to specify that the values of one or more columns must satisfy a boolean expression. With check constraints, you can specify predicates (boolean expressions) on a table, and require that all rows in the table satisfy those predicates. For example, you can require that the end time of a concert is later than its start time:Here, we see the “start_before_end” constraint requires the value of the StartTime column to be less than the EndTime, otherwise an insert or update for any row will fail. Check constraints join foreign keys,NOT NULL constraints, and UNIQUE indexes as methods to add integrity constraints to your database.Generated columnsA generated column is a column whose value is computed from other columns in the same row. This is useful to push down critical data logic into the database, instead of relying on the application layer. Generated columns can make a query simpler or save the cost of evaluating an expression at query time. Like other column types, they can also be indexed or used as a foreign key. For example, you can create a generated column that concatenates the first and last name fields into a new column:In this example, the value of “FullName” is computed when a new row is inserted or when “FirstName” and/or “LastName” is updated for an existing row. The computed value is stored and accessed the same way as other columns in the table, but can’t be updated on its own. NUMERIC data typeCustomer requests are a crucial part of how we prioritize features, and NUMERIC data type was a common request. The NUMERIC data type provides precision, useful across many industries and functions, such as financial, scientific, or engineering applications. NUMERIC is useful, where a precision of 30 digits or more is commonly required. Spanner’s NUMERIC has precision of 38 and scale of 9, meaning it can store a number with a total of 38 digits, 9 of which can be fractional (i.e., to the right of the decimal). When you need to store an arbitrary precision number in a Spanner database, and you need more precision than NUMERIC provides, we recommend that you store the value as its decimal representation in a STRING column.Using new Spanner features in an example use caseIn the following example, we look at an ecommerce application and see how check constraints, generated columns, and basic indexing can help improve application performance and reliability. A common pattern for an ecommerce site might be creating a case-insensitive search for a product. In many cases, product names are stored case-sensitively, and the practice of capitalization can vary greatly. To improve the performance of searching over product names, we can create a generated column that converts product name to uppercase and then create an index on that.The schema for the product table could look like this:You now have a generated column that stores the product name column with all capital letters. This generated column is stored like any other column in the table, and can be indexed for faster lookups:To search a product name, convert the search term into uppercase first. We also need to instruct Spanner to use the index we just created:Now when we query over the product name, we get faster and consistent results, regardless of how the product is capitalized in the listing.An ecommerce company may also keep a separate pricing table for its products. A few simple check constraints can make sure that prices for products don’t enter an invalid state, and that discount programs don’t overlap. For example, the following constraint checks that a product price cannot be negative:The pricing table also has two columns for discounts, one of which is a seasonal discount that applies during certain seasonal holidays, and another that is provided for new customer registrations. Here we can add a check constraint to an existing table to ensure that only one discount is active at a time:For many customers, check constraints, generated columns, and NUMERIC data type will be welcome additions to the toolbox for defining schema and creating high-performing applications. We hope that this year’s launches have made it easier to build, test, and deploy your applications using Spanner as your globally consistent database. We look forward to your feedback, and stay tuned for a busy 2021.Learn moreTo get started with Spanner, create an instanceor try it out with a Spanner Qwiklab.Related ArticleAutomatically right-size Spanner instances with the new AutoscalerFrom the Google Cloud blog: new Autoscaler lets you scale Spanner instances up and down easily to optimize costs and usage based on utili…Read Article
Quelle: Google Cloud Platform
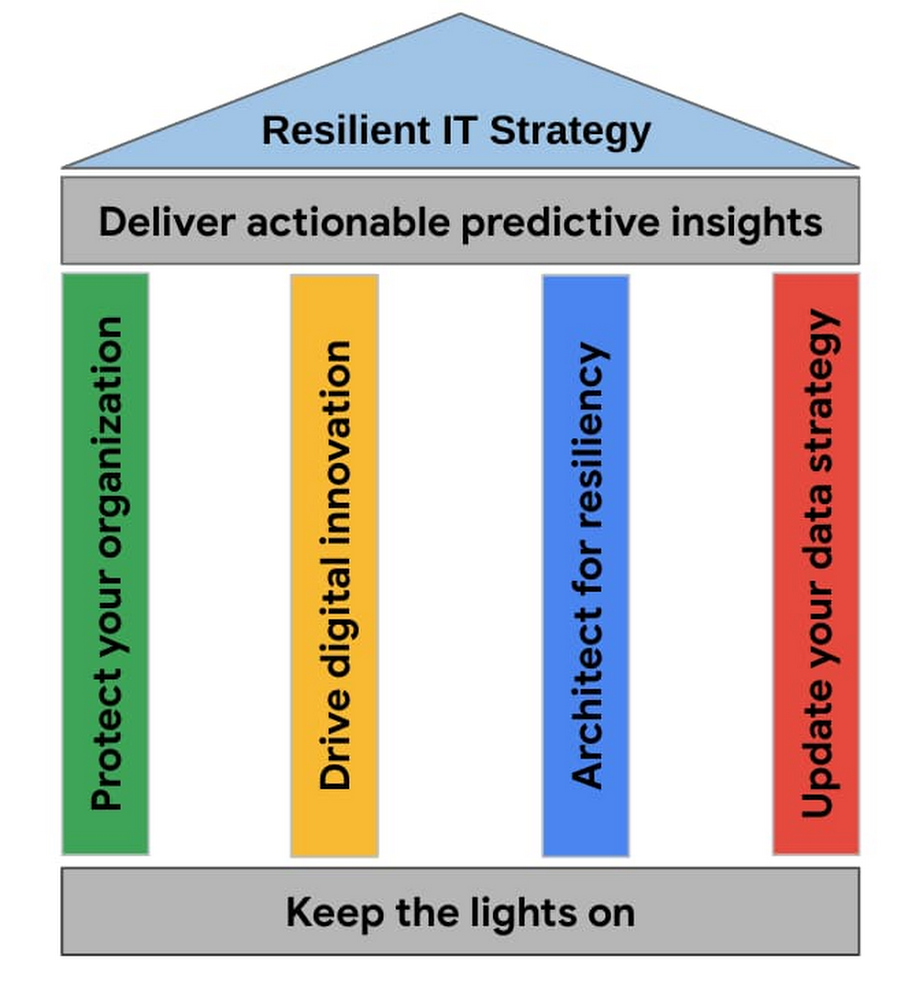
During my last 20 years of IT projects and consultancy across enterprise businesses, I have seen recurring patterns being implemented to deliver a resilient IT strategy. Challenges across security, operation, innovation, data strategy, and insights are very common for enterprises looking to modernize. 2020 has so far proven to be a very challenging year for everyone, and enterprises want to plan, architect, and build resilient strategies to keep their business successful. My job as an Enterprise Cloud Architect at Google Cloud is to help enterprises on this journey, and I have collected different critical success factors to navigate such challenging times. In this article, I share my experience, those critical success factors, and the methodology I developed to achieve a resilient IT Strategy through Google Cloud.What is Resilient IT Strategy (RIS)Achieving business resilience, one of the main asks from management boards, is keeping your business successful both during these difficult times, and also in the future. This means protecting employees, maintaining the core business running, and accelerating your digital transformation.I’ve grouped the success factors (or pillars) needed to achieve business resilience in the following methodology that I call RIS: Resilient IT Strategy.RIS-Model: How to build a Resilient IT Strategy with Google CloudThe “house of resiliency” is helping reimagine a business model to achieve business resilience. The foundation is led out at the bottom of the house with “keep the lights on,” the first of the six pillars from the RIS-Model. The vertical pillars revolve around best practices on security, innovation, resiliency, and data strategy. The last pillar shown on top is “deliver actionable data insights.” Let’s go through each of the pillars and see how this can help solve these challenges with Google Cloud.1. Keep the lights onIT is not only a business enabler but also a business driver, and IT operations truly is the “engine” of your business. This is why “keeping the lights on” with IT operations is such an important foundation to our house of resiliency: without that, your business engine stops. In this section, I would like to share how enterprises can achieve that goal when using Google Cloud.The first step to take is to follow our best practices for enterprise organization. This article helps enterprise architects and technology stakeholders plan a solid foundation across identity and access management, networking, security, cloud architecture, billing, and management. To expand on the foundation, our Solving for Operational Efficiency with Google Cloud whitepaper is full of insights on how to optimize IT Operations. It also highlights how to optimize costs, and plan for a more agile and scalable future. 2. Protect your organizationLegacy enterprises that are used to monolithic applications and are starting their cloud journey are often challenged by different aspects of security in the cloud: application security, secure access to internal apps, or security analytics. Protecting the organization, and detecting and stopping threats are always a priority. In this pillar, I would like to share a few modern approaches that can make a difference. We, at Google Cloud, believe that they can significantly help make it easier to defend your business. Let’s go over three areas where cloud technologies can be transformative: 1. Security analytics and operationsAnalytics and operations is a security topic that presents significant challenges, as many enterprises don’t have the ability to store and analyze large amounts of security telemetry. The goal is to reduce the cost to analyze and store this data and increase the speed of gaining insight from this data. Cost is often a reason why enterprises limit the retention of their security telemetry data, reducing their capabilities to analyse and detect threats. Our solution based on Chronicle and VirusTotal offers painless scalability combined with intelligent identification. The result of that is that you can analyze many risks at the speed of Google search while reducing cost. Read this Chronicle customer case study of a global healthcare company to learn more.2. Application SecurityProtecting users and applications requires constantly updated knowledge to new security threats. Our Application Security solution, which includes reCAPTCHA Enterprise and our WebRisk product, relies on Google’s years of experience in defending our own services. This means you can better protect your apps from fraud and abuse with an enterprise solution that can easily integrate into site or mobile apps, in the cloud or on-premises.3. BeyondCorp Remote AccessVPNs were not intended to be used for always-on remote access, and in these times where remote work is the norm, they can be a significant productivity sink for end users and IT admins. BeyondCorp Remote Access delivers simple and secure access to internal apps for your employees and extended workforce without the use of a VPN. Learn more about BeyondCorp, the Zero-Trust security model, and how Airbnb implemented it using Google Cloud in this video.3. Drive digital innovationInnovation has always been a key driver to accelerate growth and prevent future disruptions. Driving digital innovation is the third pillar of our RIS-Model. Unfortunately, innovation is often done in iterative cycles, without taking into account the entire IT strategy. I believe that innovation is a holistic topic that must be driven consciously by the top of the enterprise, and by the architecture teams. The goal is to let the business units drive the innovation on behalf of their customers. That’s why digital innovation at Google is part of our DNA. You can find out how Google Cloud helps you solve for innovation here.This third pillar lets you build business capabilities and services to remain relevant in future. Google Cloud is tackling these challenges by focusing on reimagining how to manage apps and infrastructure with an agile and open architecture. We have introduced a new Google Cloud Application Modernization Program (CAMP) during our recent Next conference. It is based on our experience of driving application delivery at speed and scale, and relies on the principles developed by the DevOps Research and Assessment (DORA) team which is based on six years of research and data from over 31,000 professionals. Read more about CAMP and how to get to the future faster. 4. Architect for resiliencyThe fourth pillar of the RIS model is designing IT architectures that are flexible, resilient, and scalable. In other words, part of this mission means building flexibility into your architecture, staying agile, and adopting an open cloud architecture in order to respond to change. Furthermore, architect for scalable and resilient solutions across your organization to build resilient systems. Scalability to adjust capacity to meet demand and resiliency to design to withstand failures. These are two essential goals within this pillar. Google Cloud has introduced some patterns and practices for scalable and resilient apps that helps you architect with these principles.In addition, Google has built the Site Reliability Engineering (SRE) methodology through years of running global apps serving billions of users. You can see SRE as an implementation of the DevOps principles in your organization. Culture has always been a key part of the DevOps, Agile, and Lean movements, driving both software delivery performance and organizational performance. We found that SRE principles like “Accept Failure as Normal,” “Reduce Organisational Silos,” “Implement Gradual Change,” “Leverage Tooling & Automation,” and “Measure Everything” are providing a common theme to work across organizations. These principles also support a culture and way to work. Read more on how to start and assess your journey for SRE.5. Update your data strategyA clear data management strategy to generate business value is a critical success factor for any business. Enterprise businesses today often struggle to achieve this goal because CRM, ERP, consumer and customer data are often residing in data silos. That’s why the fifth pillar of our RIS-Model is about your data strategy and how you can update and build your data strategy for the modern era. Each customer’s journey is different and, with that, so is the data strategy that you define. Enterprise leaders are keen to find new ways to use data to improve customer experiences, find new business opportunities, and generate unmatched value and competitive advantage. They are looking for opportunities to embrace technologies like open source and multi-cloud to avoid vendor lock-in. Google Cloud introduced Anthos, a new platform for managing applications in today’s multi-cloud world. However, if executed poorly, a multi-cloud strategy increases the data silos problem. For this reason, you should strive for a consistent data experience across clouds. A modern multi-cloud data strategy is needed to let you extract value from data, regardless of type, size, and independently of where your data is stored. This ability brings the power of analytics to where your data lives, in different public clouds (Google Cloud, Amazon Web Services, and Azure) and provides a single-pane-of-glass for your data. In a multi-cloud world, businesses need to break down data silos without moving data between providers and gain critical business insights seamlessly across clouds. Google Cloud has recently introduced BigQuery Omni to help you build this pillar: it lets you query your data in Google Cloud, AWS and Azure (coming soon).Here’s a step-by-step guide which provides you insights on how to update your data strategy. The report shares different aspects on how to expand your data strategy, along with customer case studies that complement this pillar. 6. Deliver actionable predictive insightsUnlocking data’s value is every company’s crucial and challenging mission that is covered in the sixth pillar of the RIS-Model. Leveraging data, becoming data-driven, and empowering predictive analytics; these are the goals of many enterprise businesses. The previous pillars should have highlighted the main required steps to build a good framework to really benefit from all the value that lives inside your data. This pillar is about gaining insights from your business, partners and customers. By using Artificial intelligence (AI) and machine learning on Google Cloud, you can implement many different use cases to solve your business pain points and deliver business value to your customers. With that you can gain real-time insights that improve decision-making and accelerate innovation, in order to reimagine your business. For example, learn how the State of Illinois is using AI to help residents who lost their job because of COVID-19 file hundreds of thousands of unemployment claims.To summarize, the methodology helps you navigate these difficult times by focusing your work on a resilient IT Strategy through Google Cloud. The six pillars represent disciplines that you need to build, maintain, and evolve to transform your business across the key success factors in order to keep it successful. Ultimately the approach is a guideline for business and IT stakeholders, which should return stability, value, and growth on your journey with Google Cloud.Thank you to Théo Chamley, Solutions Architect at Google Cloud, for his help on this article.Related Article4 steps to a successful cloud migrationDownload this white paper to help guide your migration to Google Cloud.Read Article
Quelle: Google Cloud Platform
At the start of 2020, Google Cloud set out to reimagine the application development space by acquiring AppSheet, an intelligent no-code application development platform that equips both IT and line-of-business users with the tools they need to quickly build apps and automation without writing any code. In the months that followed, we’ve experienced change, growth and a few surprises along the way. Let’s take a look back at 2020 and examine how AppSheet has helped organizations and individuals across the globe create new ways to work.Responding to the COVID-19 pandemicIn retrospect, the timing of the AppSheet acquisition—which happened right as the pandemic’s impact was becoming better understood—placed Google Cloud in a unique position to support individuals and organizations responding to the crisis. People all around the world, many of whom had no experience writing code, built powerful applications on the AppSheet platform that helped their organizations and communities respond in these uncertain times:USMEDIC, a provider of comprehensive equipment maintenance solutions to healthcare and medical research communities, built a medical equipment tracking and management solution to support various healthcare organizations, including overrun hospitals struggling to locate equipment.The Mthunzi Network, a not-for-profit organization that distributes aid to vulnerable populations, built an easy-to-use app to automate the distribution and redemption of digital food vouchers.The AppSheet Community at large rallied around a particular app that was created for local communities to organize their efforts to support those in need. This single app was built in a matter of days and translated into over 100 languages to make support accessible for anyone who needed it. It has been humbling and inspiring to witness how no-code app creators have risen to this year’s many challenges. As the issues surrounding the pandemic continue, we areextending AppSheet’s COVID-19 support through June 2021.Reimagining workHistory has demonstrated that innovation is born from necessity. The Guttenberg press, for example, found its notoriety during the plague of the 14th century due to both social and cultural demands. So too has 2020 provided the ultimate forcing function to accelerate digital innovation. It’s forced organizations to reimagine collaboration, productivity, and success, demanding that everyone, not just IT, find new ways to get things done.For example, Globe Telecom, a leading mobile network provider in the Philippines, adopted AppSheet to accelerate application development. In June, the company announced a no-code hackathon open to all teams, originally planned in 2019 as an in-person event but changed in the wake of the pandemic to an online-only event. Despite the change, organizers were surprised when over 100 teams entered the hackathon, a signal that employees across the organization had an appetite to contribute to the company’s culture of innovation.The winning team created an app that reports illegal signal boosting. The app captures field data and, if the data shows malfeasance, it triggers automated reports that alert the correct employees to handle the problem, reducing the reporting time from two days to two hours and enabling faster resolution for reported incidents.We also saw app creators at small businesses and universities build useful no-code solutions with AppSheet. A fifth-generation family business operatorcreated a customer retention app and inventory management app for his jewelry store. An event coordinator built multiple apps tomanage registration and logistics for his company’s world-class athletic racing events. A medical studentbuilt a flashcard app with a little extra customization and functionality he couldn’t find elsewhere.Preparing for the futureOn our end, we’ve worked tirelessly to improve the platform with nearly 200 releases this year. We’ve made great strides in making AppSheet easier to use for even more users:The platform’s integrations with Google Workspace, as well as AppSheet’s inclusion in Google Workspace enterprise SKUs, allow people to redefine tasks and processes—and they also add more governance control, boosting AppSheet’s ability to accelerate innovation while avoiding the risks of shadow ITEasy-to-use app templates help people get started faster and incorporate Google Workspace functionality into their AppSheet-powered appsCustomization features such as Color Picker give app builders more control over their appsWith new connectors, like the Apigee API connector, app creators can link AppSheet to new data sources, opening up a new realm of possibilitiesFinally, we would be remiss if we didn’t mention AppSheet capabilities that weannounced in September at Google Cloud Next ‘20 OnAir, such as Apigee datasource for AppSheet, which lets AppSheet users harness Apigee APIs, andAppSheet Automation, which offers a natural language interface and contextual recommendations that let users automate business processes. These efforts, combined with the ongoing integration of Google technologies into AppSheet, give the platform an even better understanding of an app creator’s intent, through a more human-centric approach that makes it easier than ever to build apps without writing any code. While 2020 has been a challenging year for everyone, we’re proud of what we’ve accomplished. At Google Cloud, we will continue to support the transformative solutions created by citizen developers—people who, because they don’t have traditional coding abilities, may have otherwise not been able to build apps. We look forward to seeing what you build in 2021!
Quelle: Google Cloud Platform
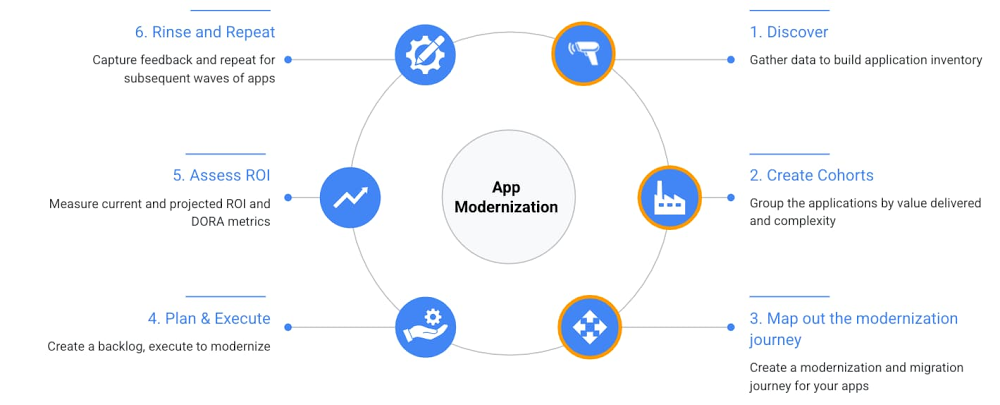
Application rationalization is a process of going over the application inventory to determine which applications should be retired, retained, reposted, replatformed, refactored or reimagined. This is an important process for every enterprise in making investment or divestment decisions. Application rationalization is critical for maintaining the overall hygiene of the app portfolio irrespective of where you are running your applications i.e. in cloud or not. However, if you are looking to migrate to the cloud, it serves as a first step towards a cloud adoption or migration journey. In this blog we will explore drivers and challenges while providing a step-by-step process to rationalize and modernize your application portfolio. This is also the first blog post in a series of posts that we will publish on the app rationalization and modernization topic.There are several drivers for application rationalization for organizations, mostly centered around reducing redundancies, paying down technical debt, and getting a handle on growing costs. Some specific examples include: Enterprises going through M&A (mergers and acquisitions), which introduces the applications and services of a newly acquired business, many of which may duplicate those already in place.Siloed lines of businesses independently purchasing software that exists outside the scrutiny and control of the IT organization.Embarking on a digital transformation and revisiting existing investments with an eye towards operational improvements and lower maintenance costs. See the CIO guide for app modernization to maximize business value and minimize risk.What are the challenges associated with application rationalization? We see a few:Sheer complexity and sprawl can limit visibility, making it difficult to see where duplication is happening across a vast application portfolio.Zombie applications exist! There are often applications running simply because retirement plans were never fully executed or completed successfully. Unavailability of up to date application inventory. Are newer applications and cloud services accounted for?Even if you know where all your applications are, and what they do, you may be missing a formal decisioning model or heuristics in place to decide the best approach for a given application.Without proper upfront planning and goal setting, it can be tough to measure ROI and TCO of the whole effort leading to multiple initiatives getting abandoned mid way through the transformation process.Taking an application inventoryBefore we go any further on app rationalization, let’s define application inventory. Application inventory is defined as a catalog for all applications that exist in the organization. It has all relevant information about the applications such as business capabilities, application owners, workload categories (e.g. business critical, internal etc.), technology stacks, dependencies, MTTR (mean time to recovery), contacts, and more. Having an authoritative application inventory is critical for IT leaders to make informed decisions and rationalize the application portfolio. If you don’t have an inventory of your apps, please don’t despair, start with a discovery process and catalogue all the app inventory and assets and repos in one place. The key for successful application rationalization and modernization is approaching it like an engineering problem—crawl, walk, run; iterative process with a feedback loop for continuous improvement. Create a blueprintA key concept in application rationalization/modernization is figuring out the right blueprint for each application. Retain—Keep the application as is, i.e. host it in the current environmentRetire—Decommission the application and compute at source Rehost—Migrate it similar compute elsewhereReplatform—Upgrade the application and re-install on the target Refactor—Make changes to the application to move towards cloud native traitsReimagine—Re-architect and rewrite6 steps to application modernizationThe six step process outlined below is a structured, iterative approach to application modernization. Step 1-3 depicts the application rationalization aspects of the modernization journey.Fig. Application modernization process including steps 1-3 for app rationalizationStep 1: Discover—Gather the dataData is the foundation of the app rationalization process. Gather app inventory data for all your apps in a consistent way across the board. If you have multiple formats of data across lines of businesses, you may need to normalize the data. Typically some form of albeit outdated app inventory can be found in CMDB databases or IT spreadsheets. If you do not have an application inventory in your organization then you need to build one either in an automated way or manually. For automated app discovery there are tools that you can use such as Stratozone, M4A Linux and Windows assessment tools, APM tools such as Splunk, dynatrace, newrelic, and appdynamics and others may also be helpful to get you started. App assessment tools specific to workloads like WebSphere Application Migration Toolkit, Redhat Migration Toolkit for Applications, VMWare cloud suitability analyzer and .NET Portability Analyzer can help paint a picture of technical quality across the infrastructure and application layers. As a bonus, similar rationalization can be done at the data, infrastructure and mainframe tiers too. Watch this space.Fig. Discovery ProcessAt Google, we think of problems as software first and automate across the board (SRE thinking). If you can build an automated discovery process for your infrastructure, applications and data it helps track and assess the state of the app modernization program systematically over the long run. Instrumenting the app rationalization program with DORA metrics enables organizations to measure engineering efficiency and optimize the velocity of software development by focusing on performance.Step 2: Create cohorts—Group applications Once you have the application inventory, categorize applications based on value and effort. Low effort e.g. stateless applications,microservices or applications with simple dependencies etc. and high business value will give you the first wave candidates to modernize or migrate.Fig. Creating and mapping cohortsStep 3: Map out the modernization journeyFor each application, understand its current state to map it to the right destination on its cloud journey. For each application type, we outline the set of possible modernization paths. Watch out for more content in this section in upcoming blogs.Not cloud ready (Retain, Rehost ,Reimagine)—These are typically monolithic, legacy applications which run on the VM, take a long time to restart, not horizontally scalable. These applications sometimes depend on the host configuration and also require elevated privileges. Container ready (Rehost, Refactor and Replatform)—These applications can restart, have readiness and liveliness probes, logs to stdout. These applications can be easily containerized. Cloud compatible (Replatform)—In addition to container ready, typically these applications have externalized configurations, secret management, good observability baked in. The apps can also scale horizontally. Cloud friendly—These apps are stateless, can be disposed of, have no session affinity, and have metrics that are exposed using an exporter.Cloud Native—These are API first, easy to integrate cloud authentication and authorization apps. They can scale to zero and run in serverless runtimes. The picture below shows where each of this category lands on the modernization journey and a recommended way to start modernization. This will drive your cloud migration journey, e.g. lift and shift, move and improve etc.Fig. Application migration/modernization MapOnce you have reached this stage, you have established a migration or change path for your applications. It is useful to think of this transition to cloud as a journey, i.e. an application can go through multiple rounds of migration and modernization or vice-versa as different layers of abstractions become available after every migration of modernization activity. Step 4: Plan and ExecuteAt this stage you have gathered enough data about the first wave of applications. You are ready to put together an execution plan, along with the engineering, DevOps and operations/SRE teams. Google Cloud offers solutions for modernizing applications, one such example for Java is here.At the end of this phase, you will have the following (not an exhaustive list):An experienced team who can run and maintain the production workloads in cloud Recipes for app transformation and repeatable CI/CD patternsA security blueprint and data (in transit and at rest) guidelinesApplication telemetry (logging, metrics, alerts etc.) and monitoringApps running in the cloud, plus old apps turned off realizing infrastructure and license savingsRunbook for day 2 operationsRunbook for incident managementStep 5: Assess ROIROI calculations include a combination of: Direct costs: hardware, software, operations, and administrationIndirect costs: end-user operations and downtimeIt is best to capture the current/as is ROI and projected ROI after the modernization effort. Ideally this is in a dashboard and tracked with metrics that are collected continuously as applications flow across environments to prod and savings are realized. The Google CAMP program puts in place a data-driven assessment and benchmarking, and brings together a tailored set of technical, process, measurement, and cultural practices along with solutions and recommendations to measure and realize the desired savings. Step 6: Rinse and RepeatCapture the feedback from going over the app rationalization steps and repeat for the rest of your applications to modernize your application portfolio. With each subsequent iteration it is critical to measure key results and set goals to create a self propelling, self improving fly wheel of app rationalization. SummaryApp rationalization is not a complicated process. It is a data driven, agile, continuous process that can be implemented and communicated within the organization with the executive support. Stay tuned: As a next step, we will be publishing a series of blog posts detailing each step in the application rationalization and modernization journey and how Google Cloud can help.Related ArticleGoogle Cloud Application Modernization Program: Get to the future fasterThe Google Cloud App Modernization Program (CAMP) can help you accelerate your modernization process and adopt DevOps best practicesRead Article
Quelle: Google Cloud Platform
Recently our CEO Scott Johnston took a look back on all that Docker had achieved one year after selling the Enterprise business to Mirantis and refocusing solely on developers. We made significant investments to deliver value-enhancing features for developers, completed strategic collaborations with key ecosystem partners and doubled down on engaging its user community, resulting in a 70% year-over-year increase in Docker usage.
Even though we are winding down the calendar year, you wouldn’t know it based on the pace at which our engineering and product teams have been cranking out new features and tools for cloud-native development. In this post, I’ll add some context around all the goodness that we’ve released recently.
Recall that our strategy is to deliver simplicity, velocity and choice for dev teams going from code to cloud with Docker’s collaborative application development platform. Our latest releases, including Docker Desktop 3.0 and Docker Engine 20.10, accelerate the build, share, and run process for developers and teams.
Higher Velocity Docker Desktop Releases
With the release of Docker Desktop 3.0.0, we are totally changing the way we distribute Docker Desktop to developers. These changes allow for smaller, faster Docker Desktop releases for increased simplicity and velocity. Specifically:
Docker Desktop will move to a single release stream for all users. Now developers don’t have to choose between stability versus getting fixes and features quickly.All Docker Desktop updates will be provided as deltas from the previous version. This will reduce the size of a typical update, speeding up your workflow and removing distractions from your day.Updates will be downloaded in the background for a more simple experience. All a developer needs to do is restart Docker Desktop. A preview of Docker Desktop on Apple M1 silicon, the most in-demand request on our public roadmap.
These updates build upon what was a banner year for Docker Desktop. The team has been super hard at work having also collaborated with Snyk on image scanning and collaborating with AWS and Microsoft to deploy from Desktop straight to AWS and Azure, respectively. We also invested in performance improvements to the local development experience, such as CPU improvements on Mac and the WSL2 backend on Windows.
Docker Engine 20.10
Docker Engine is the industry’s de facto container runtime. It powers millions of applications worldwide, providing a standardized packaging format for diverse applications. This major release of Docker Engine 20.10 continues our investment in the community Engine adding multiple new features including support for cgroups V2, moving multiple features out of experimental into GA including `RUN –mount=type=(cache|secret|ssh|…)`and rootless mode, along with a ton of other improvements to the API, client and build experience. These updates enhance security and increase trust and confidence so that developers can move faster than before.
More 2020 Milestones
In addition to these latest product innovations, we continued to execute on our developer strategy. Other highlights from the year that was 2020 include:
11.3 million monthly active users sharing apps from 7.9 million Docker Hub repositories at a rate of 13.6 billion pulls per month – up 70% year-over-year. Collaborated with Microsoft, AWS, Snyk and Canonical to enhance the developer experience and grow the ecosystem. Docker ranked as the #1 most wanted, the #2 most loved, and the #3 most popular platform according to the 2020 Stack Overflow Survey. Hosted DockerCon Live with more than 80,000 registrants. All of the DockerCon Live 2020 content is on-demand if you missed it.Over 80 projects accepted to our open source program.
Keep an eye out in the new year for the latest and greatest from Docker. You can expect to see us release features and tools that enhance the developer experience for app dev environments, container image management, pipeline automation, collaboration and content. Happy holidays and merry everything! We will “see” you in 2021, Docker fam.
The post Closing Out 2020 with More Innovation for Developers appeared first on Docker Blog.
Quelle: https://blog.docker.com/feed/