Urteil: Vodafone verliert im Streit um fingierte Vertragsabschlüsse
Falls Vodafone damit weitermacht, droht laut Verbraucherzentrale ein Ordnungsgeld von bis zu 250.000 Euro. (Vodafone, Rechtsstreitigkeiten)
Quelle: Golem

Falls Vodafone damit weitermacht, droht laut Verbraucherzentrale ein Ordnungsgeld von bis zu 250.000 Euro. (Vodafone, Rechtsstreitigkeiten)
Quelle: Golem

Ein Team mit Mitgliedern aus verschiedenen Ländern ist für jede Führungskraft eine Herausforderung – mit Culture Maps und viel reden geht es aber. Ein Erfahrungsbericht von Bernard Oakley (Arbeit, Fachkräftemangel)
Quelle: Golem

Das Einkaufen im Internet spielt gerade jetzt und auch zukünftig eine immer größere Rolle für Verbraucher. Eine verbesserte User Experience trägt maßgeblich dazu bei, erfolgreich Kunden zu gewinnen. Die folgenden sieben Trends muss jeder Händler auf dem Screen haben. (E-Commerce)
Quelle: Golem

Das gibt Hoffnung, dass Nvidia zumindest hier liefern kann. Allerdings sind auch hier höhere Preise zu erwarten. (Geforce RTX, Grafikhardware)
Quelle: Golem

Der Verbraucherschutzverbund Euroconsumers verlangt Entschädigungszahlungen für Betroffene, da diese sich unnötigerweise ein neues Smartphone gekauft haben könnten. (Apple, iPhone)
Quelle: Golem
Editor’s note: We’re hearing today from Songkick, a U.K.-based concert discovery service owned by Warner Music Group. Annually, Songkick helps over 175 million music fans from all around the world to track their favorite artists, discover concerts and live streams, and buy tickets with confidence online and via their mobile apps and website. Here’s how the team was able to streamline their process and open up new potential by moving their data from physical servers to the cloud.Since 2007, we have specialized in making it as easy, fun, and fair as possible for fans to see their favorite artists live. We do this by gathering information shared by artists, promoters, and ticketing partners, storing it on a database of event information, and cross-referencing against user-flagged data in a tracking database. This lets our users know who is playing in their favorite venues, where their favorite artists are performing, and how to get tickets as soon as they’re on sale.For many years, all of this depended on physical server space. We managed three racks in an offsite location, so whenever we had any hardware issues, it meant that someone would need to physically go to the location to make changes, even if it was the middle of the night. This meant more unnecessary, time-consuming work for our team and a greater potential for long downtimes. When we were acquired by Warner Music Group, we evaluated what we should focus on and what kind of value we want to deliver as an engineering team. It became clear that maintaining physical machines or database servers were not part of it. Moving to a global venueMoving to the cloud was the obvious solution, and when we did our research, we found that Google Cloud was the best option for us. By adopting Google Cloud managed services, all of our database infrastructure is managed for us, meaning we don’t have to deal with issues like hardware failure—especially not at 4 a.m. It also meant that we no longer had to deal with one of the biggest infrastructure headaches—software upgrades—which, between testing and prep work, previously would have taken over a month to upgrade the physical offsite servers. Honestly, we are just happy to let Google deal with that and our engineers can focus on creating software.Migration was thankfully very easy with Google Cloud. Using external replication, we moved one database instance at a time, with about five minutes of downtime for each. We could have made it with almost zero downtime but it was not necessary for our scenario. Today, all four of our databases run on Cloud SQL for MySQL with the largest databases—musical event information and artist tour and show tracking information—hosted on dedicated instances. These are quite large; our total data usage is around 1.25TB, which includes about 400 GB of event data and 100 GB of tracking data. The two larger databases are 8 CPU, 30 GB of RAM, and the other two are 4 CPU, with 15 GB RAM. We duplicate that data into our staging environment, so total data in CloudSQL is about 2.5 TB.Overall, we get to spend less time thinking about and dealing with MySQL, and more time making improvements that directly impact the business.Keeping data clean and clear with Cloud SQLOne of the great things about Songkick is that we get data directly from artists, promoters, venues, and ticket sellers, meaning that we can get more accurate information as soon as it’s available. The drawback of this is that when data comes from all of these sources, it means that it comes in multiple formats that often weren’t created to work together. It also means that we often get the same information from multiple sources, which can make things confusing for users.Cloud SQL acts as our source-of-truth datastore, ensuring that all of our teams and the 30 applications that contain our business logic are sharing the same information. We apply dedupe and normalization rules on incoming data before it is stored in Cloud SQL, thus reducing the risk of incorrect, inconsistent, duplicated, or incomplete data.This is only the beginning of what we’re looking to improve at Songkick on Google Cloud. We’re planning to expand our data processing operations, including creating a service for artists that will show them where their most engaged audiences are, helping them plan better tours. We want to streamline this process by aggregating queries on BigQuery, then storing the summarized results back in Cloud SQL. That means a better experience for the fans and the artists, and it all starts with a better database in the cloud.Learn more about Songkick and about Google Cloud databases.Related ArticleCloud SQL now supports PostgreSQL 13Fully managed Cloud SQL cloud database service now supports PostgreSQL 13.Read Article
Quelle: Google Cloud Platform
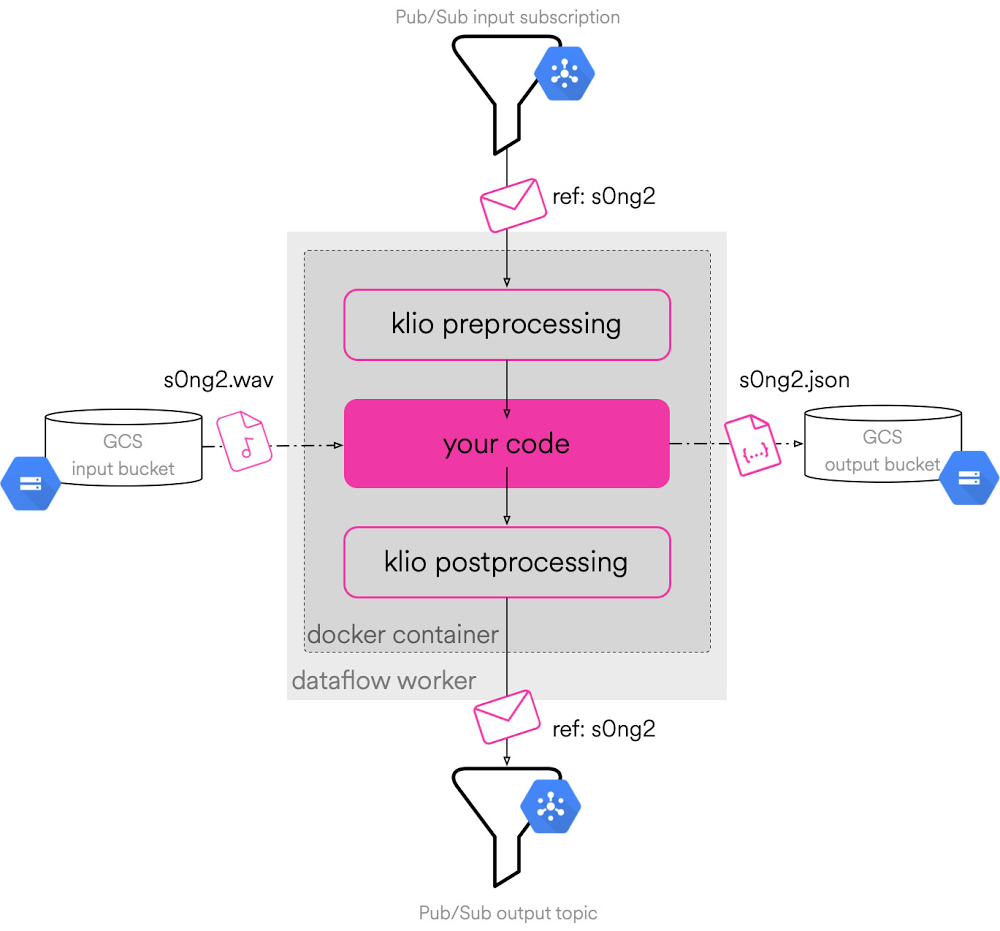
On any given day, music streaming service Spotify might process an audio file a hundred different ways—identifying a track’s rhythm and tempo, timestamping beats, and measuring loudness—as well as more sophisticated processing, such as detecting languages and separating vocals from instruments. This might be done to develop a new feature, to help inform playlists and recommendations, or for pure research.Doing this kind of processing on a single audio file is one thing. But Spotify’s music library is over 60 million songs, growing by 40,000 tracks a day, not including the rapidly expanding podcast catalog. Then, factor in that hundreds of product teams are processing these tracks at the same time, all around the world, and for different use cases. This scale and complexity—plus, the difficulty of handling large binary files to begin with—can hinder collaboration and efficiency, bringing product development to a grinding halt. That’s unless you have Klio.What is Klio?In order to productionize audio processing, Spotify created Klio—a framework built on top of Apache Beam for Python that helps researchers and engineers alike run large-scale data pipelines for processing audio and other media files (such as video and images). Spotify originally created Klio after realizing that ML and audio researchers across the company were performing similar audio processing tasks, but were struggling to deploy and maintain them. Spotify saw an opportunity to produce a flexible, managed process that would support a variety of audio processing use cases over time—efficiently and at scale—and got to work. At a high level, Klio allows a user to provide a media file as input, perform the necessary processing, and output intelligent features and data. There are a multitude of possible use cases for audio alone, from standardizing common audio-processing tasks with ffmpeg or librosa to running custom machine learning models. Klio simplifies and standardizes pipeline creation for these tasks, increasing efficiency and letting users focus on their business objectives rather than maintaining the processing infrastructure. Now that Klio has been released as open source, anyone can use the framework to build their own scalable and efficient media processing workflows.How does Klio work?Klio job overviewKlio currently enables a few key steps to create the desired pipeline. First, it assumes that the pipeline will accept a large binary file as input. This can be audio, images, or video. This file is stored in Cloud Storage. As part of this, the job sends a unique message to Pub/Sub, where it announces that a file has been uploaded. Klio then reads this message and downloads the file to begin processing. At this step, Klio can begin performing the necessary logic to intelligently process the desired outcome for the particular use case, such as language extraction. Once the processing is complete, it uploads its output artifact to another Cloud Storage bucket for storage. The overall orchestration of the whole pipeline is done by Apache Beam, which allows for a traditional Python interface for audio/ML users and traditional pipeline execution. One of Klio’s key benefits is its support for directed acyclic graphs (DAGs), which allow users to configure dependent jobs and their order of execution so that a parent job can trigger corresponding children jobs.In this example, there are three teams all relying on the same overall parent job, called Downsample. This downsampling adjusts the number of samples in an audio file to essentially compress the file to a specified rate that may be required for later jobs. As a result, now Team A, B, and C’s jobs may begin to launch their needed processing. This might be detecting the “speechiness” or amount of spoken word, “instrumentalness” or the lack of vocals, and much more. Another key feature of Klio is its ability to optimize the order of execution. It’s not always efficient or necessary to run every Klio job in the graph for a given file. Maybe you want to iterate on your own job without triggering sibling or downstream jobs. Or you have a subset of your media catalogue that requires some backfill processing. Sometimes this means running the parent Klio jobs to fill in missing dependencies. With that, Klio supports bottom-up processing when needed, like this:A Klio job will first check to see if work has already been processed for a given file. If so, work is skipped for that job. However, if the job’s input data is not available (i.e., if the Energy job does not have the output from the Beat Tracking job for a given audio), Klio will recursively trigger jobs within its direct line of execution without triggering work for sibling jobs.What’s next for Klio?This initial release of Klio represents two years of building, testing, and practical application by different teams all across Spotify. From the beginning, Klio was made with open source in mind.With this overall architecture, users are free to add in their particular customizations as needed to cater to their requirements. Klio is cloud-agnostic, meaning that it can support a variety of runners, both locally and in the cloud. In Spotify’s case, this meant Google Cloud, using Apache Beam to call the Dataflow Runner. But it can be extended to other runners as well. If you’re interested in contributing back, they welcome more collaborations with the open source community. While Klio was initially built for audio, it is capable of serving all types of media. At Spotify, they’ve already seen success in a variety of different internal use cases. Specifically, it separates the vocals and instruments to enable Sing Along functionality in Japan as well as fingerprints common audio attributes, such as “danceability” and “tempo,” in their Audio Features API. Based on the early success from these use cases, it will be exciting to see what other media processing problems Klio can help solve, whether it is enabling large-scale content moderation or performing object detection across large video streams.How to get startedTo learn more, read the rest of the Klio story on the Spotify Engineering blog. Or jump in and get started with Klio now.
Quelle: Google Cloud Platform

Whether you run services in Google Cloud, on-premises, in other clouds, or all of the above, the fundamental challenges of application networking remain the same: How do you get traffic to these services? And how do these services talk to each other?Traffic Director is a fully managed control plane for service mesh and load balancing. We built Traffic Director with the vision that it could solve these challenges, no matter where your services live. Today, we’re delivering on another part of that vision so that we can better support your multi-environment needs.With Traffic Director, you can now send traffic to services and gateways that are hosted outside of Google Cloud. Traffic is routed privately, over Cloud Interconnect or Cloud VPN, according to the rules that you configure in Traffic Director.This capability enables services in your VPC network to interoperate more seamlessly with services in other environments. It also enables you to build advanced solutions based on Google Cloud’s portfolio of networking products, such as Cloud Armor protection for your private on-prem services. Whether you’re only running workloads in Google Cloud, or have advanced multi-environment needs, Traffic Director is a versatile tool in your networking toolkit.Introducing Hybrid Connectivity NEGsThis is all made possible through support for Hybrid Connectivity Network Endpoint Groups (NEGs). Now generally available, think of a Hybrid Connectivity NEG as a collection of IP addresses and ports (“endpoints”) that clients can use to reach your application.You probably already use NEGs when configuring Traffic Director with GKE-based services. Hybrid Connectivity NEGs are special because they don’t need to resolve to a destination within Google Cloud. Instead, they can resolve to a destination outside of your VPC network (like a gateway in an on-prem data center or an application on another public cloud).If you’re sending traffic from Google Cloud to another environment, that traffic travels over hybrid connectivity (for example, Cloud Interconnect or Cloud VPN). This allows you to have workloads in another environment and reach them securely from Google Cloud, without having to make those workloads accessible via the public internet.Here’s a simple example of how you might use Hybrid Connectivity NEGs with Traffic Director:Imagine you have a virtual machine (VM) running on-prem and that VM can be reached from your VPC network via Cloud VPN interconnect at 10.0.0.1 on port 80. In Traffic Director, you create a service called `on-prem-service` and add a Hybrid Connectivity NEG with an endpoint with IP address 10.0.0.1 and port 80. Traffic Director then sends that information to its clients (for example, Envoy sidecar proxies running alongside your applications). Thus, when your application sends a request to `on-prem-service`, the Traffic Director client inspects the request and directs it to `10.0.0.1:80`.What can I do with it?With this feature, you can now build powerful solutions that involve existing Traffic Director capabilities as well as Cloud Load Balancing’s global network edge services. Here are a few examples:Route mesh traffic to on-prem or another cloudThe simplest use case for this feature is plain old traffic routing. For example:You want to get traffic from one environment to another. In the above example, when your application sends a request to the `on-prem` service, the Traffic Director client inspects the outbound request and updates its destination. The destination gets set to an endpoint associated with the `on-prem` service (in this case, `10.2.0.1`). The request then travels over VPN or Interconnect to its intended destination.If you need to add more endpoints, you just add them to your service by updating Traffic Director. You don’t need to make any changes to your application code.Migrate a service between environmentsBeing able to send traffic privately to an endpoint outside of Google Cloud is powerful. But things get even more interesting when you combine this with Traffic Director capabilities like weight-based traffic splitting.The above example extends the previous pattern, but instead of configuring Traffic Director to send all traffic to the `on-prem` service, you configure Traffic Director to split traffic across two services using weight-based traffic splitting.Traffic splitting allows you to start by sending 0% of traffic to the `cloud` service and 100% to the `on-prem` service. You can then gradually increase the proportion of traffic sent to the `cloud` service. Eventually, you send 100% of traffic to the `cloud` service and you can retire the `on-prem` service.Use Google Cloud’s edge services with workloads in other environmentsFinally, you can combine this functionality with Cloud Load Balancing to bring global edge capabilities to workloads that are outside of your VPC network. Cloud Load Balancing offers a wide range of network edge services, such as globally distributed ingress, Cloud Armor for DDoS protection, and Cloud CDN.You can now use these with Traffic Director to support workloads that are not exposed to the public internet: if you have Cloud VPN or Cloud Interconnect between Google Cloud and another environment, your traffic will travel via that private route. We previously posted about how you can use Cloud Armor with on-prem and cloud workloads that can be reached via the public internet. In the approach described below, workloads in other environments don’t need to be publicly reachable.In this example, traffic from clients travels over the public internet and enters Google Cloud’s network via a Cloud Load Balancer such as our global external HTTP(S) load balancer. You can use network edge services, for example, Cloud Armor DDoS protection or Identity-Aware Proxy user authentication when traffic reaches the load balancer.After you’ve secured your ingress path, the traffic makes a brief stop in Google Cloud, where an application or standalone proxy (configured by Traffic Director) forwards it across Cloud VPN or Cloud Interconnect to your on-prem service.Get started todayWith Traffic Director, we’ve been focused on enterprise needs since day one, and we’re excited about the class of problems that Hybrid Connectivity NEGs solve for enterprises that operate beyond GCP.Get started today with Traffic Director, Google Cloud Load Balancing and Cloud Armor to set up a secure global ingress solution for private multi-environment workloads. This is just a first step on our journey to delivering on Traffic Director’s mission of being a truly universal application networking solution. More to come!Related ArticleGoogle Cloud networking in depth: How Traffic Director provides global load balancing for open service meshGoogle Cloud’s new Traffic Director control-plane management tool brings load balancing a resiliency to environments running on a service…Read Article
Quelle: Google Cloud Platform

Our biggest conference of the year couldn’t happen in person. We’ve pushed everything online. That’s fine, we’re Google, we know how to do websites. And demos. And apps. We got this!Turns out there were some hiccups along the way. Settle down with your favorite beverage, I’d like to tell you a story.Back in the spring, as we were gearing up for Cloud Next 2020, Terry Ryan (@tpryan) and the Cloud Marketing team put their heads together to figure out what a fully online Next conference would be like. Demos are always a big part of Next, giving Google’s product teams a chance to show off new products and features to a large audience, in person. These demos are often interactive, frequently eye-catching, and meant to both excite and educate. They include staffers available to walk attendees through a demo and to explain the complicated bits. A lot to accomplish in person; now even harder to move them entirely online!Terry took the lead on making this all happen, working across 27 demos to oversee building, testing and deploying these projects to the NextOnAir site in time for the summer launch. Below we’ll talk through some lessons learned from that process, and some of what he built to accomplish this feat.Each demo had a different Google team (or an agency) behind it, doing the coding and visual development. Each one their own application, using whatever frontend framework that team is most comfortable with, or best fits the use case. The teams had a lot of flexibility in making their choice: in the end they just needed to deliver a web app that we would host. All demos were served by App Engine, which we chose because it is easy to use, scales up and down quickly, and provides built-in security.Next we head to implementation, where the developer team works to create what the designers envisioned. Here’s our first challenge, on the Google side:1. How do we get code from the agencies?In the past all demos focused on delivering a working demo for the event show floor. Formatting and communication could take any form imaginable: an emailed .zip file, a Github repo, a Drive folder, a carrier pigeon. We knew that wouldn’t scale. So Terry set up an individual Github repo for each demo for the agencies to push code to, allowing a single control plane (and logging system) to manage all the demo code. Already a major improvement, and much simpler to manage.Additionally, now that every demo is going through Github, we can use some existing Continuous Integration / Continuous Deployment (CICD) tools to automate. Without automation every step of the way Terry would have to manually push each build or each demo to get them published. Not a fun manual chore.. Okay, next up, making changes:2. How do we update these demos in production when code changes?Lucky for us we have strong integrations between Cloud Build and Github, so we can trigger a new build each time the master branch is updated in Github (by the team making that demo). We can even automate deploying that new build to App Engine to speed things up.All code hosted by Google is required to pass through rigorous security and privacy reviews. This is true in all cases but even more important when the code is created by a third party. However these projects frequently require multiple last minute, urgent updates in response to stakeholder requests. 3. How do we control deployment so only reviewed code is pushed?In most cases, third party code has to be pushed to Google hosted sites by a Google employee, so Terry had to be a bottleneck there. With Github tools, he could prevent unapproved merging of pull requests, set himself up as the required reviewer, then approve the code to trigger a push to the production version of the App Engine apps, so nothing would get into production without his express authorization. With this system in place Terry was able to manage a rapid flurry of updates as the deadlines approached, even if all he had was his phone! But with so much happening simultaneously, there’s still another challenge:4. How do we keep these systems moving forward consistently?For that Terry made scripts. So many scripts! He used scripts to activate individual services and service accounts. To bind Cloud Build as an App Engine admin for each project. To perform initial git commits before sharing to Github. To add functionality to Cloud Build pipelines so they could report on whether or not the builds succeeded.What about securing all these projects and apps?A script to set up Identity-Aware Proxy for each project, to restrict access to the applications. On the Github side, adding people to each repo and locking down the master branch – Scripts!We’ll use this to set up the default project and get Cloud Build going.[Set the gcloud default project and to kick off a Cloud Build session. ]And here we establish some essential APIs we need to use, add some access policy for security, and start the GitHub project with an initial commit.[Spin up the APIs we need to run these demos, and initialize the GitHub project]Next we need to get our email tool so Terry can find out when a build completes, or has an error.[Deploy our mail-sending tool in a Cloud Function, to notify on build completion or problems]And we’re going to add Identity-Aware Proxy for controlling web-app access to only the right people, since we don’t want a publicly available IP just yet.[Set up and tear down IAP so only our organization’s logged in people can look at these apps]Finally we get the directories established, with our template to save time on manual file creation.[Script to set up project directories, and copy a template in]And then once it’s all flowing:5. How do I keep track of all this work?Guess what? It’s more scripts. And notifications. Terry made scripts to collect stats on the whole thing, so we know there were 281 commits, 312 code reviews, and 27 demos launched. Setting up the right set of notifications allowed a rapid response time when new code got pushed, and allowed Terry to keep the turnaround tight. When rapidly collaborating with these outside partners that speed becomes critical. These projects averaged 5 minutes from code approval to application pushed out to production. And if the new code push fails, a notification from Cloud Build tells Terry and the development team what went wrong.This project brought together many moving parts, many access and authorization challenges, and a tricky form of remote collaboration, but with some clever process design (and a ton of scripting) Terry got it all launched in time for our big show. Congratulations!Related ArticleCloud Build brings advanced CI/CD capabilities to GitHubTighter integration between Cloud Build and GitHub opens up advanced CI/CD workflows for DevOps shops.Read Article
Quelle: Google Cloud Platform
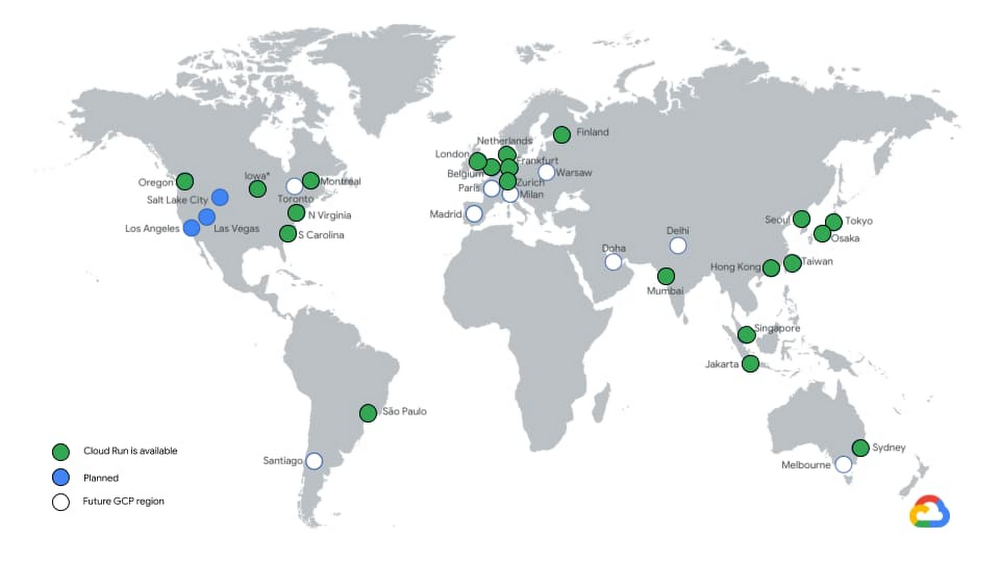
Cloud Run is built on a simple premise: combine the flexibility of containers with the simplicity, scalability, and productivity of serverless. In a few clicks, you can use Cloud Run to continuously deploy your Git repository to a fully managed environment that autoscales your containers behind a secure HTTPS endpoint. And because Cloud Run is fully managed, there’s no infrastructure management, so you can focus on delivering your applications quickly. Cloud Run has been generally available (GA) for a full year now! Here’s a recap of how Cloud Run has evolved in that time.Enterprise readyWe’ve been hard at work expanding Cloud Run to 21 regions and are on track to be available in all the remaining Google Cloud regions by the end of the year.Cloud Run services can now connect to resources with private IPs or use Cloud Memorystore Redis and Memcached by using Serverless VPC connectors, which support shared VPCs so you can connect to resources on-premises or in different projects. By routing all egress through the VPC, you benefit from a static outbound IP address for traffic originating from Cloud Run, which can be useful for making calls to external services that only allow certain IP ranges.You can now also harness the power of Cloud Load Balancing with Cloud Run: bring your own TLS certificates, specify which versions of SSL you accept, or configure custom URL-based routing on your load balancer to serve content from different backends.Global Load Balancing also enables you to run globally-distributed applications by serving traffic from multiple regions, serve static content cached on the edge via Cloud CDN, or protect your endpoints with the Cloud Armor web application firewall.With API Gateway support, you can build APIs for your customers and run them on Cloud Run without having to implement authentication and other common concerns around hosting APIs.With gradual rollouts and rollbacks, you can now safely release new revisions of your Cloud Run services by controlling the percentage of traffic sent to each revision, and testing specific revisions behind dedicated URLs.Developer friendlyAs developers ourselves, we are proud to work on a product that is so well received by the developer community.Novice users are able to build and deploy an app on their first try in less than 5 minutes. It’s so fast and easy that anyone can deploy multiple times a day. We love hearing your stories about how Cloud Run makes you more productive, so you can ship code faster. The Cloud Run user interface displays the build history and links to the git repositoryIn the past year, we added a number of features to improve developer productivity:We added an easy user interface to set up Continuous Deployment from Git repositories. Every time you push a commit to a particular branch or tag a new release, it’s automatically built and deployed to Cloud Run using Cloud Build.We also made it easier to develop applications. You can now deploy and run Cloud Run applications locally using Cloud Code. If you’re just getting started, Cloud Code can create a new application template for you, and you can run or debug your code locally in the emulator.Hate writing Dockerfiles? With Google Cloud Buildpacks, you can now turn your application code directly into a container image for supported languages. This is great if you’re bringing an existing application to Cloud Run. Similarly, buildpacks let you convert your Cloud Functions to container images, thanks to the Functions Framework.Then, to help you monitor the performance of your services and easily identify latency issues, requests sent to Cloud Run services are now captured out-of-the-box in Cloud Trace. If you want to do distributed tracing between your services, all you need to do is to pass on the trace header that you get to the outgoing requests and the trace spans will automatically correlate.While Cloud Run is able to respond to requests, and to privately and securely process messages pushed by Pub/Sub, we also added the ability to trigger Cloud Run services from 60+ Google Cloud sources. And for more powerful orchestration, you can leverage Workflows to automate and orchestrate processing using Cloud Run.FlexibilityWe’re constantly pushing the limits of Cloud Run, so you can run more workloads in a fully managed environment. You can now allocate up to 4GB of memory and 4 CPUs to your container!We also heard you want to minimize “cold starts,” notably when scaling from zero. To help, we added the ability to keep a minimum number of warm container instances to handle requests without hitting the cold starts. These idle instances are priced cheaper than active instances when they’re not handling requests. If cold starts are bothering you, give this a try.gRPC and server-side streaming let you reduce the time-to-first-byte of services by letting you send partial responses as they are computed, and write applications that stream data from the server side. With this capability, you are no longer limited to 32MB responses and you can implement HTTP/2 server push and server-sent events (SSE).With one-hour request timeouts, a single request can now run up to an hour. Combined with server-side streaming, you can now stream large responses (such as documents or videos) or handle long-running tasks from Cloud Run.Finally, graceful instance termination sends your process a termination signal (SIGTERM) before Cloud Run scales down your container instance. This gives you the opportunity to flush out any telemetry data that was kept local, and clean up the open connections, release locks, and so on.What’s next for Cloud Run?It was a great first year for Cloud Run, but this is just the beginning. We’re working hard to improve Cloud Run so you can use it for more and more diverse workloads. At the same time, we’re still laser-focused on providing you with a delightful developer experience and addressing key enterprise requirements. Stay tuned for more exciting releases, like mounting secrets from Cloud Secret Manager, integration with Identity-Aware Proxy, bidirectional streaming and WebSockets.To follow past and future Cloud Run features, take a spin through the release notes. And to learn more about these new features, check out this video.Related ArticleCloud Run, a managed Knative service, is GACloud Run, based on Knative, is available on GCP and for AnthosRead Article
Quelle: Google Cloud Platform