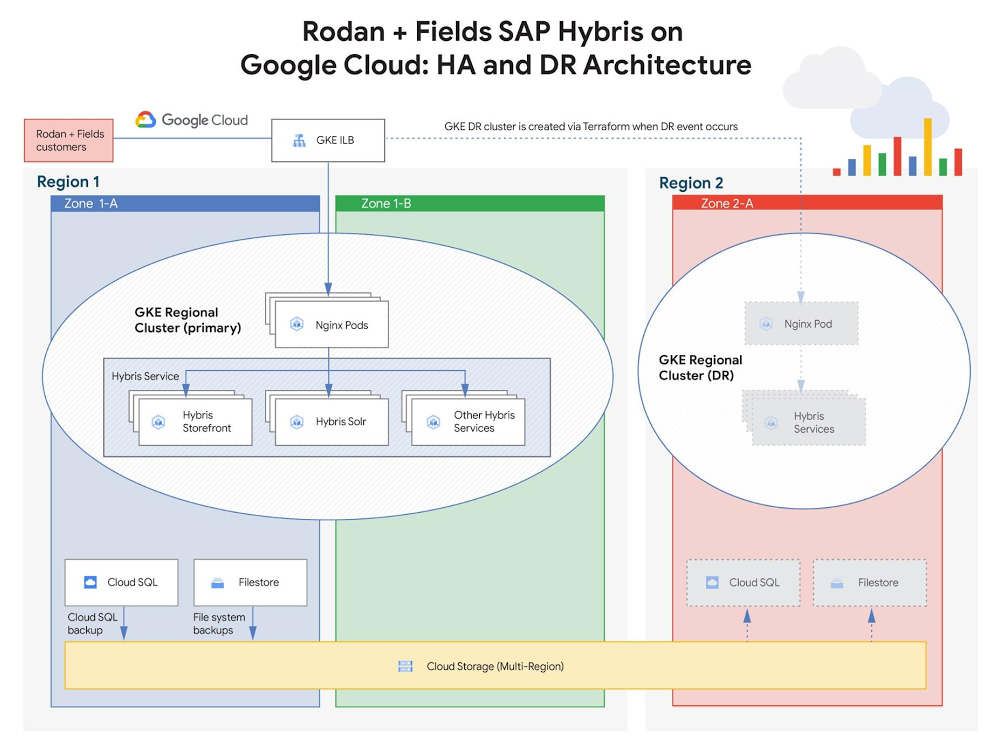
Since its founding in 2002, Rodan + Fields, one of the leading skincare brands in the U.S., has been delighting customers worldwide with its innovative product portfolio. Recently, however, after taking stock of its pre-existing IT infrastructure, Rodan + Fields realized it needed a more modern, scalable solution—one that could keep pace with the company’s growth while simplifying management of critical SAP workloads and delivering access to cutting-edge IT services. After carefully considering their options, the Rodan + Fields team decided to move the company’s mission-critical SAP workloads to Google Cloud.Ensuring business continuity was a top priority driving the company’s move to Google Cloud. Rodan + Fields needed an infrastructure solution that would protect against unpredictable, potentially catastrophic business disruptions, such as user error, malicious activities, natural disasters. To achieve this, Rodan + Fields partnered with Google Cloud to design and implement a cloud-native, automated resilience strategy, protecting the two core elements of its business infrastructure:SAP Hybris: The e-commerce platform supporting online shopping and customer experience managementSAP ERP:The resource planning platform supporting logistics for product manufacturing and distributionBuilding e-commerce resilience using SAP Hybris on Google Cloud With SAP Hybris powering Rodan + Fields’ online shopping experience, ensuring business continuity for the associated workloads was a must. Rodan + Fields consultants assist customers and execute sales entirely online, so the e-commerce site is responsible for all of the company’s global revenue and must operate reliably 24×7. If customers are unable to quickly and seamlessly browse products, place orders, and access support, the company risks substantial damage to its sales and reputation. The Rodan + Fields IT team defined the following key data protection requirements to mitigate risk to critical e-commerce services :High-availability (HA): The e-commerce infrastructure must deliver uptime resilience against local failures.Disaster recovery (DR): The e-commerce infrastructure must support rapid, automated recovery in the event of a larger-scale failure (e.g. geo-impact caused by a natural disaster).To address these requirements, Rodan + Fields partnered with Google Cloud to design and implement an architecture leveraging container-based application management and geo-redundant storage.High-availability and disaster recovery for SAP HybrisRodan + Fields decided to implement Google Kubernetes Engine (GKE), due to both its scalability (specifically, GKE supports clusters with up to 15,000 nodes. This is the most supported nodes of any cloud-based Kubernetes service) and its native high-availability features. With its Hybris application stack running on GKE, Rodan + Fields can spin up (or spin down) Kubernetes clusters to match its user volume. Like many retailers, Rodan + Fields experiences traffic in bursts, with especially high volume a few days of each month. As a result, the elasticity provided by GKE helps minimize costs by enabling infrastructure to be “right-sized” in alignment with the company’s business needs.As depicted in the diagram above, GKE also delivers on Rodan + Fields’ high availability requirements for the Hybris service, as GKE will automatically (and immediately) redeploy Hybris pods in the event of a failure. Also, since the Hybris service leverages GKE’s regional clustering capability, pods can also be redeployed in a secondary zone, which provides operational resilience for Rodan + Fields’ critical e-commerce infrastructure—even in the event of a zonal outage. In the cloud, “disaster recovery” typically refers to the ability to recover from an unexpected regional failure. To support this, Rodan + Fields implemented the following DR strategy to protect the three key elements of its Hybris infrastructure:Hybris service: Terraform infrastructure-as-code (IaC) scripts were developed by Rodan + Fields to automate recreation and configuration of the GKE-based Hybris service (and the associated load balancing) in a secondary region.E-commerce databases: Cloud SQL is configured to periodically store backups on multi-region Cloud Storage. This ensures accessibility in the secondary region if the primary region becomes unavailable.Shared file storage for e-commerce assets (e.g. media files, pictures of products, etc.): File system backups are stored periodically on multi-region Cloud Storage—again, ensuring accessibility in the secondary region if the primary region becomes unavailable.With these DR protection strategies in place, Rodan + Fields achieved an automated, testable failover process. If the primary region supporting Hybris were to become unavailable, the Terraform scripting can redeploy the Hybris service infrastructure in the secondary region and restore the associated databases and shared storage from backups.Delivering logistics resilience with SAP ERPTo prevent costly manufacturing/distribution issues, Rodan + Fields’ ERP systems also require cloud-native business continuity strategies. Those systems leverage SAP ERP Central Component (ECC), which supports operations planning and logistics processes worldwide. SAP ECC needs to run 24×7, which creates the following key protection requirements:Backup: ECC must be capable of restoring to a prior state in order to mitigate the potential impact of user error or malicious activity.Disaster recovery: ECC must support rapid recovery in the event of a larger-scale failure (e.g. geo-impact caused by a natural disaster).To address these ECC protection requirements, Rodan+Fields designed and implemented a backup and DR architecture leveraging VM snapshots, SAP database replication, and geo-redundant storage, as depicted below.Rodan + Fields leverages persistent disk snapshots to provide recoverable backups of SAP ECC VM system state (e.g. config data) and data disks. These snapshots are taken periodically, based on predefined policies, and are stored on multi-region Cloud Storage. If needed—for instance, to recover from a user or system error—the ECC VMs can be rapidly returned to a prior, known-good state by restoring from a selected snapshot. Rodan + Fields also implemented an automated multi-tier architecture to support disaster recovery, which protects the key elements of its ERP application stack:SAP ECC VM system state: Protected by the same VM snapshots that support backup. Since the snapshots reside on multi-region Cloud Storage, they can be recovered in the secondary region if the primary region becomes inaccessible.Shared NFS data (supporting SAP ECC VMs): Stored on a scale-out Filestore (formerly Elastifile) NFS storage cluster and replicated asynchronously to a live cluster in the secondary regionTo complement the DR strategy employed to protect Hybris, Rodan + Fields also implemented an automated, testable DR process to protect SAP ECC. Terraform scripting, created by Rodan + Fields integration partner, NTT, automates ERP DR processes, delivering 1) automated creation of new VMs in the failover region (from PD snapshots) and 2) automated failover to use the secondary Filestore cluster in the failover region. The Terraform scripts, which are stored on GitHub, contain the ECC configuration information required to regenerate the ERP service.Next steps on the cloud journeyBy shifting its SAP workloads to Google Cloud, Rodan + Fields is enjoying the benefits of modern, scalable infrastructure, while also protecting its business with a robust business continuity strategy. To support a peak in user access, Rodan + Fields was able to scale Hybris infrastructure by 10X in 10 minutes, supporting millions in additional revenue. In addition, as of the date of this blog publication, Rodan + Fields has experienced zero unplanned ERP outages in the year since the company migrated to running production on Google Cloud. And they aren’t stopping there… To gain additional business value, Rodan + Fields plans to continue modernizing its workflows to leverage additional cloud-native Google features and services, including:Using machine images to further simplify protection architecturesIntegrating ERP data with BigQuery to enhance data warehouse capabilities Learn more about Rodan + Fields SAP deployment on Google Cloud. For more stories of SAP customer deployments on Google Cloud, check out our solution page and YouTube channel.Related ArticleSAP on Google Cloud: 2 analyst studies reveal quantifiable business benefitsFrom uptime and infrastructure to efficiency and productivity—both Forrester and IDC identified major benefits to companies that have mad…Read Article
Quelle: Google Cloud Platform