Geheimprojekt: Apple soll US-Regierung bei geheimem iPod geholfen haben
Ein US-Unternehmen der Verteidigungsindustrie soll einen iPod umgebaut haben – möglicherweise, um radioaktive Strahlung zu erfassen. (iPod, Apple)
Quelle: Golem

Ein US-Unternehmen der Verteidigungsindustrie soll einen iPod umgebaut haben – möglicherweise, um radioaktive Strahlung zu erfassen. (iPod, Apple)
Quelle: Golem

As more and more people across the world turn to multiplayer games, developers must scale their game to meet increased player demand and provide a great gameplay experience, while managing complex underlying global infrastructure.To solve this problem, many game companies build and manage their own costly proprietary solutions, or turn to pre-packaged solutions that limit developer choice and control.Earlier this year, we announced the beta release of Game Servers, a managed service built on top of Agones, an open source game server scaling project. Game Servers uses Kubernetes for container orchestration and Agones for game server fleet orchestration and lifecycle management, providing developers with a modern, simpler paradigm for managing and scaling games. Today, we’re proud to announce that Game Servers is generally available for production workloads. By simplifying infrastructure management, Game Servers empowers developers to focus their resources on building better games for their players. Let’s dive into a few foundational concepts that will better illustrate how Game Servers helps you run your game.Clusters & RealmsA game server cluster is the most atomic level concept in Game Servers, and is simply a Kubernetes cluster running Agones. Once defined by the user, clusters must be added to a realm.Realms are user-defined groups of game server clusters that can be treated as a cohesive unit from the perspective of the game clients. Although developers can define their realms in any way they choose, the geographic distribution of a realm is typically dictated by the latency requirement of your game. For that reason, most games will define their realms on a continental basis, with realms in gaming hotspots such as the U.S., England, and Japan serving players in North America, Europe, and Asia.Regardless of whether you expect your game to build momentum in certain countries over time, or be a global hit from day one, we recommend running multiple clusters in a single realm to ensure high availability and a smooth scaling experience.Deployments & ConfigsOnce you have defined your realms and clusters, you can roll out your game software to them using concepts we call deployments and configs. A game server deployment is a global record of a game server software version that can be deployed to any or all game server clusters worldwide. A game server config specifies the details of the game server versions being rolled out across your clusters.Once you have defined these concepts, key distinctions between Agones and Game Servers begin to emerge.First, you now have the control to define your own custom auto-scaling policies. The segmentation of your game into realms and clusters, in combination with self-defined scaling policies, provides developers with an ideal mix of precision, control and simplicity. For example, you could specify a policy at the realm level that automatically provisions more servers to match geo-specific diurnal gaming patterns, or you can scale up all clusters globally simultaneously in preparation for a global in-game event.Second, you have the flexibility to roll out new game server binaries to different areas of the world by targeting specific realms with your deployments. This allows you to A/B or canary test new software rollouts in whichever realm you choose.And finally, although we are building Game Servers to be as customizable as possible, we also recognize technology is only half the battle (royale). Google Cloud’s gaming experts work collaboratively with your team to prepare for a successful launch, and Game Servers is backed by Google Cloud support to ensure your game continues to grow over the long term.Building an open architecture for gamesYour game is unique, and we recognize that control is paramount to game developers. Developers can opt out of Game Servers at any time and manage Agones clusters themselves. Furthermore, you always have direct access to the underlying Kubernetes clusters, so if you need to add your own game specific additions on top of the Agones installation, you have the power to do so. You are always in control.Choice is also important. Today, Game Servers supports clusters that run on Google Kubernetes Engine, and we are currently working on the ability to run your clusters on any environment, be it Google Cloud, other clouds, or on premise. With hybrid and multi-cloud support, developers will have the freedom to run their game server workloads wherever it makes the most sense for the player. You can also use Game Servers’ custom scaling policies to optimize the cost of deploying a global fleet across hybrid and multi-cloud environments as you see fit. “As a Google Cloud customer for many years, we’re now following the progress of Google Cloud Game Servers closely,” said Elliot Gozanksy, Head of Architecture at Square Enix. “We believe that containers and multi-cloud capabilities are extremely compelling for future large multiplayer games, and Google Cloud continues to prove its commitment to gaming developers by creating flexible, open solutions that scale worldwide.”Game Servers is free until the end of the year, and you will be billed only for the underlying use of Kubernetes clusters. To learn more about Game Servers, please visit our Game Server product page, or get started immediately with our quickstart guide. You can also join us for Solutions for Launching Massive Global Games in the Cloud at Google Cloud Next ‘20: OnAir (register here for free) and learn more about how Google Cloud is helping game developers of all sizes connect their games with players across the world.
Quelle: Google Cloud Platform
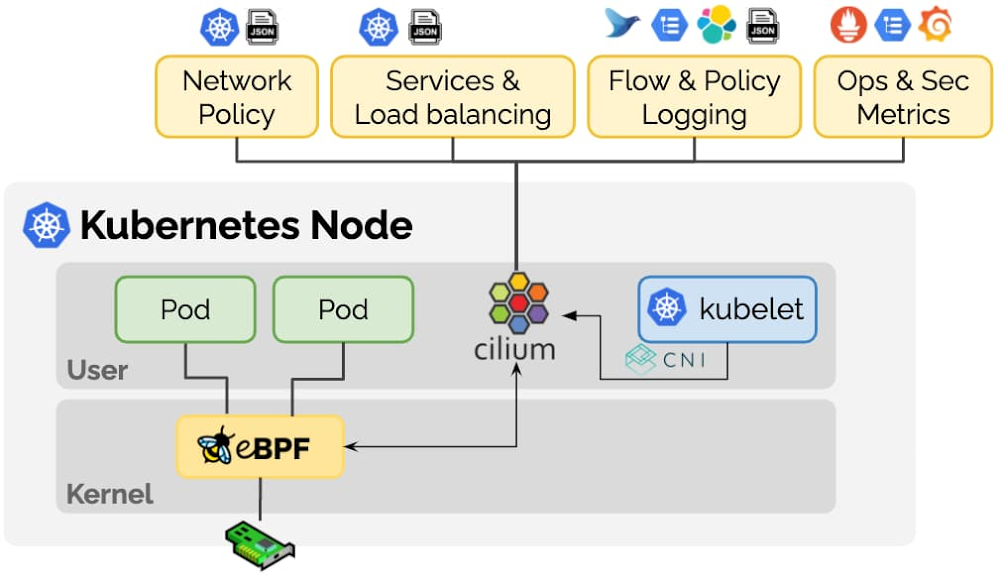
One of Kubernetes’ true superpowers is its developer-first networking model. It provides easy-to-use features such as L3/L4 services and L7 ingress to bring traffic into your cluster as well as network policies for isolating multi-tenant workloads. As more and more enterprises adopt Kubernetes, the gamut of use cases is widening with new requirements around multi-cloud, security, visibility and scalability. In addition, new technologies such as service mesh and serverless demand more customization from the underlying Kubernetes layer. These new requirements all have something in common: they need a more programmable dataplane that can perform Kubernetes-aware packet manipulations without sacrificing performance.Enter Extended Berkeley Packet Filter (eBPF), a new Linux networking paradigm that exposes programmable hooks to the network stack inside the Linux kernel. The ability to enrich the kernel with user-space information—without jumping back and forth between user and kernel spaces—enables context-aware operations on network packets at high speeds.Today, we’re introducing GKE Dataplane V2, an opinionated dataplane that harnesses the power of eBPF and Cilium, an open source project that makes the Linux kernel Kubernetes-aware using eBPF. Now in beta, we’re also using Dataplane V2 to bring Kubernetes Network Policy logging to Google Kubernetes Engine (GKE).What are eBPF and Cilium?eBPF is a revolutionary technology that can run sandboxed programs in the Linux kernel without recompiling the kernel or loading kernel modules. Over the last few years, eBPF has become the standard way to address problems that previously relied on kernel changes or kernel modules. In addition, eBPF has resulted in the development of a completely new generation of tooling in areas such as networking, security, and application profiling. These tools no longer rely on existing kernel functionality but instead actively reprogram runtime behavior, all without compromising execution efficiency or safety.Cilium is an open source project that has been designed on top of eBPF to address the new scalability, security and visibility requirements of container workloads. Cilium goes beyond a traditional Container Networking Interface (CNI) to provide service resolution, policy enforcement and much more as seen in the picture below.The Cilium community has put in a tremendous amount of effort to bootstrap the Cilium project, which is the most mature eBPF implementation for Kubernetes out there. We at Google actively contribute to the Cilium project, so that the entire Kubernetes community can leverage the advances we are making with eBPF.Using eBPF to build Kubernetes Network Policy LoggingLet’s look at a concrete application of how eBPF is helping us solve a real customer pain point. Security-conscious customers use Kubernetes network policies to declare how pods can communicate with one another. However, there is no scalable way to troubleshoot and audit the behavior of these policies, which makes it a non-starter for enterprise customers. With the introduction of eBPF to GKE, we can now support real-time policy enforcement as well as correlate policy actions (allow/deny) to pod, namespace, and policy names at line rate with minimal impact on the node’s CPU and memory resources.The image above shows how highly specialized eBPF programs are installed into the Linux kernel to enforce network policy and report action logs. As packets come into the VM, the eBPF programs installed in the kernel decide how to route the packet. Unlike IPTables, eBPF programs have access to Kubernetes-specific metadata including network policy information.This way, they can not only allow or deny the packet, they can also report annotated actions back to user space. These events make it possible for us to generate network policy logs that are meaningful to a Kubernetes user. For instance, the log snippet shown below pinpoints which source pod was trying to connect to which destination pod and which network policy allowed that connection.Under the hood, Network Policy logging leverages GKE Dataplane V2. Not only does GKE Dataplane V2 expose the information needed for policy logging, it also completely abstracts away the details of configuring network policy enforcement from the user. That is, when you use Dataplane V2, you no longer have to worry about explicitly enabling network policy enforcement or picking the right CNI to use network policy on your GKE clusters. Talk about making Kubernetes easy to use!Besides network policy, Kubernetes load balancing can also use eBPF to implement Direct Server Return (DSR) mode. DSR eliminates the additional NAT problem that loses the client’s IP address when using Kubernetes LoadBalancer services. eBPF’s ability to encode metadata into a network packet on the fly allows us to provide additional information to the destination node such that it can directly converse with the original client. With DSR, we can reduce the bandwidth requirements of each node as well as avoid port exhaustion.eBPF’s ability to augment network packets with custom metadata enables a long list of possible use cases. We are as excited about the future of Kubernetes and eBPF as you are, so stay tuned for more innovations.How you can benefit from thisEnterprises are always looking to improve their security posture with better visibility into their infrastructure. They want to be able to quickly identify abnormal traffic patterns such as pods that are unexpectedly talking to the internet and denial-of-service attacks. With Kubernetes Network Policy logging, you can now see all allowed and denied network connections directly in the Cloud Logging console to troubleshoot policies and spot irregular network activity.To try out Kubernetes Network Policy logging for yourself, create a new GKE cluster with Dataplane V2 using the following command.Google would like to thank Thomas Graf, co-founder of the Cilium project, for his contributions to this blog post.
Quelle: Google Cloud Platform
For many decades, databases have been the engines fueling the most business-critical enterprise workloads across industries such as retail, banking, manufacturing, and healthcare. These are the systems that, for example, allow money to move around the world and supplies to get to hospitals and patients when they need it most. These workloads require the highest levels of reliability, durability, and performance. As the keepers of the world’s most critical data, databases are top of mind as enterprises accelerate their adoption of cloud and consider how to meet new and changing demands. We have partnered with some of the largest global enterprises and have seen some clear trends emerge. While the amount of data managed by applications continues to grow at an unbelievable rate, companies are rethinking how they handle this data. They want to increase the speed at which they build and launch new features and not get bogged down in maintaining and scaling databases, which ultimately stifles innovation. They’re increasingly adopting databases with open APIs—freeing themselves from restrictive licenses and maintaining portability of their data. They’re having to meet new, stringent regulations for security and data sovereignty, like the GDPR or CCPA, which introduce new complexity and the need for more controls as they scale globally. As these companies map out their cloud journeys, multi-cloud and hybrid strategies are the default. What’s most exciting to see is how they’re looking to transform their business through new data-driven applications that deliver always-on availability, local experiences at a global level, and synchronization across all channels. These trends are top of mind as customers embark on their journey to cloud, and there is no single path that’s right for everyone. We believe in meeting customers where they are so they can reap the benefits of the cloud and catalyze what they can deliver to their business. Taking a three-phase journeyWhether it’s to increase their agility and pace of innovation, better manage costs, or entirely shut down data centers, we’re seeing customers accelerate their move to cloud and follow a three-phase journey: migration, modernization, and transformation. We have customers who are trying to move as many as thousands of applications and databases to the cloud, frequently on a tight timeline. They need a fast-track approach to lift and shift what they’re running today to the cloud. This “as-is” migration already adds tremendous value, even if it doesn’t provide the full benefits of cloud-native capabilities. We’ve partnered closely with our customers to transition large database estates of both commercial and open source databases to our environment in this migration phase. Fully managed database services such as Cloud SQL (offered for MySQL, PostgreSQL, and SQL Server) provide familiarity while letting customers offload the 24/7 management of their databases to Google Cloud. By adopting managed services, they can refocus their resources on moving the business forward and improving productivity, leaving the heavy lifting of ensuring a highly available environment to us. Our Bare Metal Solution for Oracle workloads allows customers to lower overall costs while maintaining existing investments.Once migrated, many of our customers seek to modernize their database environments by transitioning off legacy databases and onto open source databases. The lack of licensing flexibility, high costs, and constrained deployment options highly motivate customers to make the needed investment to transition off. With open source databases having become enterprise-ready, customers are able to remove operational limitations and seamlessly handle unpredictable demand, all without compromising on performance and reliability. By modernizing, DevOps teams can better manage their development and testing cycles, push new releases faster, and improve accuracy and predictability overall.To release new features to customers faster, Autotrader migrated their Oracle database to Cloud SQL. This meant the teams could make changes with less risk and, by moving to a managed service, AutoTrader can focus more on improving its products. After migrating, AutoTrader’s release cadence improved by over 140% (year over year) with an improved success rate of 99.87%.For customers looking to build next-gen applications entirely in the cloud, they are in the transformation phase. This is about unlocking new possibilities and competitive differentiation for businesses. For relational workloads, Cloud Spanner leads in its ability to run at global scale with strong consistency, all while delivering industry-leading reliability (5 9s). For non-relational workloads, this same global consistency with 5 9s availability is achieved with Cloud Firestore—enabling an unmatched experience to build mobile, web, and IoT applications with live synchronization. Building transformational applications goes beyond any specific service; it’s about how they can work together to deliver game-changing benefits. Cloud-native databases integrate with other services in Google Cloud, enabling you to run your IT systems and apps as microservices and apply advanced analytics and AI to your data. In just one example, social media platform ShareChat saw their traffic grow 500% in the span of just a few days, and were able to scale Spanner horizontally with zero lines of code change.Wherever the customer is in this journey, we’re focused at Google Cloud on supporting them with the services, best practices, and tooling ecosystem to enable their success. Whether they’re all-in on transformation, or just looking to take the first step, we enable them to mix and match these options to migrate at the pace that’s realistic and manageable for their teams and organization. This week at Google Cloud Next ‘20: OnAir, check out expert sessions and demos to learn more about our entire suite of database offerings. And explore how organizations rely on Google Cloud databases to power their most critical applications, drive new innovation, and build better experiences for their customers.
Quelle: Google Cloud Platform
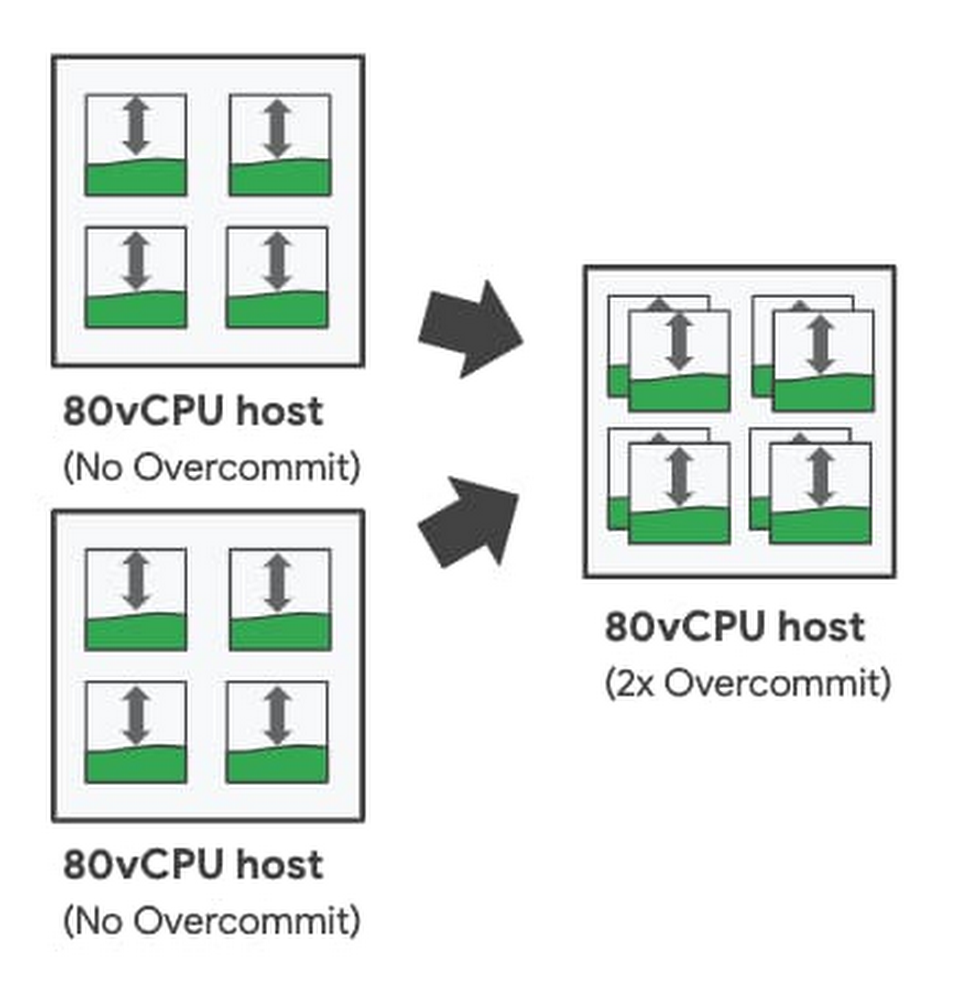
As part of our commitment to provide the most enterprise-friendly, intelligent, and cost effective options for running workloads in the cloud, we are excited to announce CPU overcommit for sole-tenant nodes is now generally available. With CPU overcommit for sole-tenant nodes, you can over-provision your dedicated host virtual CPU resources by up to 2X. CPU overcommit automatically reallocates virtual CPUs across your sole-tenant nodes from idle VM instances to VM instances that need additional resources. This allows you to intelligently pool CPU cycles to reduce compute requirements when running enterprise workloads on dedicated hardware.CPU overcommit for sole-tenant nodes addresses common enterprise challenges such as:Running cost-efficient virtual desktops in the cloud- CPU overcommit for sole-tenant nodes enables building cost-efficient virtual desktop solutions by intelligently sharing resources across VMs based on usage when dedicated hardware requirements from licensing requirements exist. Improving host utilization and helping to reduce infrastructure costs – CPU overcommit allows you to further increase the available host CPUs on each sole-tenant node. Coupled with custom machine types, CPU overcommit helps optimize memory usage and supports higher utilization for workloads with lower memory footprints.Reducing license costs – For licenses based on host physical-cores — such as bring-your-own-license for Windows Server or Microsoft SQL Server — CPU overcommit for sole-tenant nodes allows you to place more VMs on each licensed server. This allows you to persist on-prem licensing constructs and can help greatly reduce your licensing cost burden when running on Google Cloud.Flexible controlCPU overcommit for sole-tenant nodes is controlled at the VM instance-level by setting the minimum number of guaranteed virtual CPUs per VM along with the maximum burstable virtual CPUs per VM. This gives you flexible per-VM control to mix-and-match VM sizes and overcommit levels on a single sole-tenant node, so you can meet your specific workload needs. For example, when running a traditional virtual desktop workload, you can choose to uniformly overcommit all instances on a sole-tenant node; while for custom application deployments, you can choose tailored CPU overcommit levels (or no overcommit) for workloads with greater performance sensitivity. With up to a 2X overcommit setting per instance, you can oversubscribe each sole-tenant node by up to twice the number of base virtual CPUs. This means that for an n2-node-80-640 with 80 virtual CPUs, CPU overcommit allows you to treat the node as if there were up to 160 virtual CPUs.Configuring Instance-level CPU OvercommitIntelligent monitoringCPU overcommit for sole-tenant nodes offers detailed metrics to monitor your VM instancesto help you better tune your instance overcommit settings. Using the built-in Scheduler Wait Time metric available in Cloud Monitoring, you can view instance-level wait-time statistics to see the impact of oversubscription on your workload. The scheduler wait-time metric allows you to measure the amount of time your instance is waiting for CPU cycles so that you can appropriately adjust overcommit levels based on workload needs. To help you take action quickly, you can set up Cloud Monitoring to trigger alerts for instance wait-time thresholds.Pricing and availabilitySole-tenant nodes configured for CPU overcommit incur a fixed 25% premium charge. CPU overcommit configured sole-tenant nodes are available on N1 and N2 nodes in regions and zones with sole-tenant node availability. Click here to learn more about Compute Engine and sole-tenant nodes.
Quelle: Google Cloud Platform
It’s Week 6 of Google Cloud Next ‘20: OnAir, and this week we’re covering all things databases, from running your favorite open source database with Cloud SQL to building new enterprise solutions using Cloud Spanner. We have a lot of great content to share with you this week, so let’s dig in.Whatever database questions you have—Should I use SQL or NoSQL? Is it horizontally scalable and disaster recovery-ready?—you can get help answering them during this week’s sessions at Next OnAir and through some cool demos showing how to choose your database and how a high availability setup works (I am very proud of our team’s creativity!).After checking out some must-see sessions below, if you have questions, I’ll be hosting a live developer- and operator-focused recap and Q&A session this Friday, August 21 at 9 AM PST. Or, join our APAC team for a recap Friday at 11 AM SGT. Hope to see you then.Personally, I am looking forward to sharing all the amazing things the Cloud SQL team did in the past year with the session: What’s New With Cloud SQL: So much good material, and the highly anticipated PITR (point in time recovery) for PostgreSQL.Another session we couldn’t miss is this one, super useful for those using Kubernetes and maybe need a little help with the connectivity between the products: Connecting to Cloud SQL from Kubernetes: Your application is scaling with all those nodes; how about adding your persistent data storage into Cloud SQL and taking advantage of our high-availability setup?Speaking of Kubernetes, we couldn’t let the cloud-native databases be forgotten:Simplify complex application development using Cloud Firestore: Get a look at how the Firestore database service makes it easy for developers to scale new and existing applications while adding real-time client data synchronization and offline mode capabilitiesModernizing HBase workloads with Cloud Bigtable: See how to move from your preferred NoSQL database to Bigtable using HBase.And if you’re still not sure which is the right tool for you, check out these sessions:How to Choose the Right Database For Your Workloads:Where you’ll see the advantages of each technology according to your needs.Optimally Deploy an Application Cache with Memorystore: Caching everywhere, folks!Also, this week’s Cloud Study Jam will give you an opportunity to participate in hands-on labs on how to use BigQuery tables across different locations and create data transformation pipelines, so you can get real-world data management experience. You’ll get a chance to learn more about how to prepare for Google Cloud’s Professional Data Engineer Certification as well.One thing to remember about databases is that there’s so much you can solve with just one database, and Google Cloud has a broad set of tools to help you solve your data problems. You may have your single source of truth on a Cloud SQL instance, but want to improve your login and product catalog by adding a caching layer with Cloud Memorystore. Being able to use these products together leads to better management and productivity—essential in a modern, fast-moving world.Next OnAir is running now until Sep. 8. You can check out the full session catalog and register at g.co/cloudnext.
Quelle: Google Cloud Platform
The trend toward the use of massive AI models to power a large number of tasks is changing how AI is built. At Microsoft Build 2020, we shared our vision for AI at Scale utilizing state-of-the-art AI supercomputing in Azure and a new class of large-scale AI models enabling next-generation AI. The advantage of large scale models is that they only need to be trained once with massive amounts of data using AI supercomputing, enabling them to then be “fine-tuned” for different tasks and domains with much smaller datasets and resources. The more parameters that a model has, the better it can capture the difficult nuances of the data, as demonstrated by our 17-billion-parameter Turing Natural Language Generation (T-NLG) model and its ability to understand language to answer questions from or summarize documents seen for the first time. Natural language models like this, significantly larger than the state-of-the-art models a year ago, and many orders of magnitude the size of earlier image-centric models, are now powering a variety of tasks throughout Bing, Word, Outlook, and Dynamics.
Training models at this scale requires large clusters of hundreds of machines with specialized AI accelerators interconnected by high-bandwidth networks inside and across the machines. We have been building such clusters in Azure to enable new natural language generation and understanding capabilities across Microsoft products, and to power OpenAI on their mission to build safe artificial general intelligence. Our latest clusters provide so much aggregated compute power that they are referred to as AI supercomputers, with the one built for OpenAI reaching the top-five publicly disclosed supercomputers in the world. Using this supercomputer, OpenAI unveiled in May their 175-billion-parameter GPT-3 model and its ability to support a wide range of tasks it wasn’t specifically trained for, including writing poetry or translation.
The work that we have done on large-scale compute clusters, leading network design, and the software stack, including Azure Machine Learning, ONNX Runtime, and other Azure AI services, to manage it is directly aligned with our AI at Scale strategy. The innovation generated through this process is ultimately making Azure better at supporting the AI needs of all our customers, irrespective of their scale. For example, with the NDv2 VM series, Azure was the first and only public cloud offering clusters of VMs with NVIDIA’s V100 Tensor Core GPUs, connected by high-bandwidth low-latency NVIDIA Mellanox InfiniBand networking. A good analogy is how automotive technology is pioneered in the high-end racing industry and then makes its way into the cars that we drive every day.
New frontiers with unprecedented scale
“Advancing AI toward general intelligence requires, in part, powerful systems that can train increasingly more capable models. The computing capability required was just not possible until recently. Azure AI and its supercomputing capabilities provide us with leading systems that help accelerate our progress” – Sam Altman, OpenAI CEO
In our continuum of Azure innovation, we’re excited to announce the new ND A100 v4 VM series, our most powerful and massively scalable AI VM, available on-demand from eight, to thousands of interconnected NVIDIA GPUs across hundreds of VMs.
The ND A100 v4 VM series starts with a single virtual machine (VM) and eight NVIDIA Ampere A100 Tensor Core GPUs, but just like the human brain is composed of interconnected neurons, our ND A100 v4-based clusters can scale up to thousands of GPUs with an unprecedented 1.6 Tb/s of interconnect bandwidth per VM. Each GPU is provided with its own dedicated topology-agnostic 200 Gb/s NVIDIA Mellanox HDR InfiniBand connection. Tens, hundreds, or thousands of GPUs can then work together as part of a Mellanox InfiniBand HDR cluster to achieve any level of AI ambition. Any AI goal (training a model from scratch, continuing its training with your own data, or fine-tuning it for your desired tasks) will be achieved much faster with dedicated GPU-to-GPU bandwidth 16x higher than any other public cloud offering.
The ND A100 v4 VM series is backed by an all-new Azure-engineered AMD Rome-powered platform with the latest hardware standards like PCIe Gen4 built into all major system components. PCIe Gen 4 and NVIDIA’s third-generation NVLINK architecture for the fastest GPU-to-GPU interconnection within each VM keeps data moving through the system more than 2x faster than before.
Most customers will see an immediate boost of 2x to 3x compute performance over the previous generation of systems based on NVIDIA V100 GPUs with no engineering work. Customers leveraging new A100 features like multi-precision Tensor Cores with sparsity acceleration and Multi-Instance GPU (MIG) can achieve a boost of up to 20x.
“Leveraging NVIDIA’s most advanced compute and networking capabilities, Azure has architected an incredible platform for AI at scale in the cloud. Through an elastic architecture that can scale from a single partition of an NVIDIA A100 GPU to thousands of A100 GPUs with NVIDIA Mellanox Infiniband interconnects, Azure customers will be able to run the world’s most demanding AI workloads.” – Ian Buck, General Manager and Vice President of Accelerated Computing at NVIDIA
The ND A100 v4 VM series leverages Azure core scalability blocks like VM Scale Sets to transparently configure clusters of any size automatically and dynamically. This will allow anyone, anywhere, to achieve AI at any scale, instantiating even AI supercomputer on-demand in minutes. You can then access VMs independently or launch and manage training jobs across the cluster using the Azure Machine Learning service.
The ND A100 v4 VM series and clusters are now in preview and will become a standard offering in the Azure portfolio, allowing anyone to unlock the potential of AI at Scale in the cloud. Please reach out to your local Microsoft account team for more information.
Quelle: Azure

This post was co-authored by Jie Feng Principal Program Manager, and Sumi Venkitaraman Senior Product Manager, Microsoft Azure.
Microsoft Azure Data Share is an open, easy, and secure way to share data at scale by enabling organizations to share data in-place or as a data snapshot. Microsoft Azure Data Explorer is a fast and highly scalable data analytics service for telemetry, time-series, and log data.
Fueled by digital transformation, modern organizations want to increasingly enable fluid data sharing to drive business decisions. Seamlessly sharing data for inter-departmental and inter-organizational collaboration can unlock tremendous competitive advantage. Maintaining control and visibility, however, remains an elusive goal. Even today, data is shared using File Transfer Protocols (FTPs), application programming interfaces (APIs), USB devices, and email attachments. These methods are simply not secure, cannot be governed, and are inefficient at best.
Azure Data Share in-place Sharing for Azure Data Explorer, now generally available, enables you to share big data easily and securely between internal departments and with external partners, vendors, or customers for near real-time collaboration.
Once data providers share data, recipients (data consumers) always have the latest data without needing any additional intervention. Additionally, data providers maintain control over the sharing and can revoke access at will. By being able to centrally manage all shared relationships, data providers gain full control of what data is shared and with whom. Operating within a fully managed environment that can scale on-demand, data providers can focus on the logic while Data Share manages the infrastructure.
Here is what our customers are saying:
“Our clients love that ability to easily, seamlessly, and securely connect to their data and then build their own custom reports and analytics. And near real-time sharing with Azure Data Explorer and Azure Data Share permits cross-organizational data collaboration without compromising data security.” —Paul Stirpe, CTO, Financial Fabric
“We’re excited by the prospect of leveraging in-place sharing with Azure Data Explorer and Azure Data Share. The ability to give stakeholders near real-time access will allow them to prioritize product development and improve customer uptime. With a focus on data privacy, we have also been able to ensure secure and easy analysis of telemetry data, with no performance impact to our core infrastructure.” —Saajan Patel, IT Product Manager, Daimler Trucks North America
How in-place data sharing works
Data providers can initiate sharing by specifying the Azure Data Explorer cluster or database they want to share, who to share with, and terms of use. Next, the Data Share service sends an email invitation to the data consumer who can accept the sharing.
After the sharing relationship is established, Data Share creates a symbolic link between the provider and consumer's Azure Data Explorer cluster. This enables the data consumer to read and query the data in near real-time. Access to the data uses compute resources from the consumer's Azure Data Explorer cluster.
With Azure Data Explorer, data is cached, indexed, and distributed on the compute nodes within the cluster and persisted on Azure storage. Since the compute and storage are decoupled, multiple consuming clusters can be attached to the same source storage with different set of caching policies without impacting the performance and security of the source cluster.
The in-place sharing capability is a game changer for organizations looking for near real-time big data collaboration between internal departments or with external partners and customers.
Get started
To learn more and get started today using Azure Data Share in-place sharing for Azure Data Explorer see these resources:
Watch the Azure Friday video, How to share data in place from Azure Data Explorer.
Read the QuickStart guide, Create Azure Data Explorer cluster and database.
Read Use Azure Data Share to share data with Azure Data Explorer.
See the Financial Fabric case study.
Read the Share IoT and Log data in real-time using Azure Data Share and Azure Data Explorer blog.
Quelle: Azure

Was am 19. August 2020 neben den großen Meldungen sonst noch passiert ist, in aller Kürze. (Kurznews, Google)
Quelle: Golem

Mit 5G und Glasfaser soll in Kiel eine autonome Verkehrskette mit umweltfreundlichen Bus- und Fährverkehren entstehen. Vodafone baut das 5G-Netz dafür. (5G, Vodafone)
Quelle: Golem