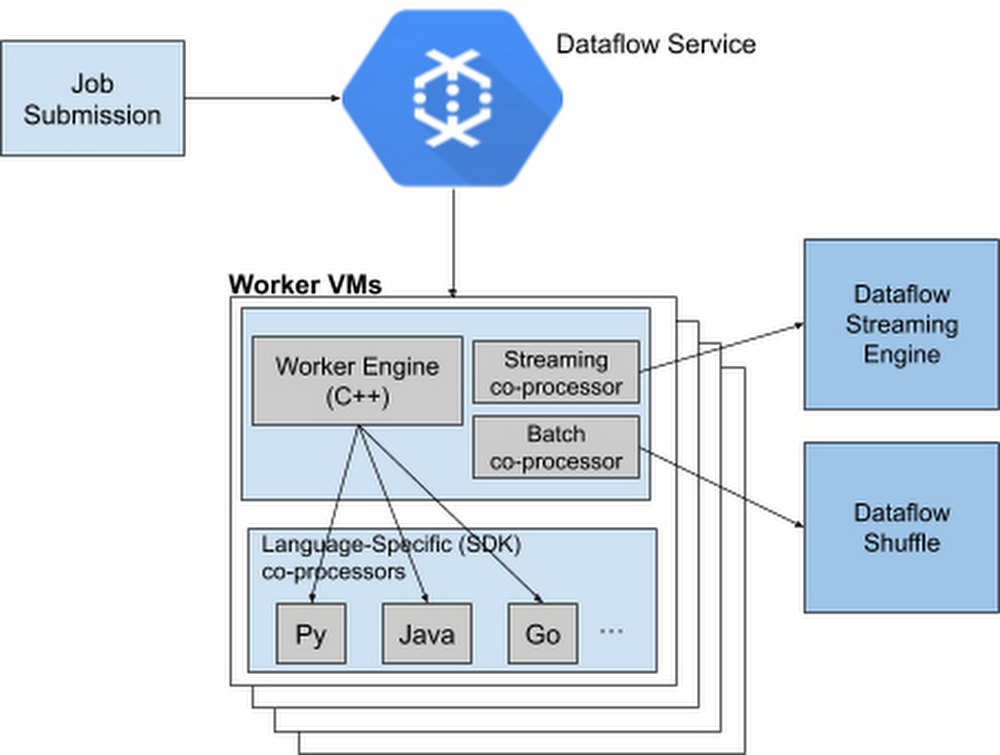
Editor’s note: This is the second blog in a three-part series examining the internal Google history that led to Dataflow, how Dataflow works as a Google Cloud service, and how it compares and contrasts with other products in the marketplace. Check out part 1: Dataflow Under the Hood: the origin story.In the first post in this series, we explored the genesis of Dataflow within Google, and talked about how it compares to Lambda Architectures. Now, let’s look a little closer at some of the key systems that power Dataflow. As mentioned in the first post, we’ve taken advantage of a number of technologies that we had built for previous systems, and also developed some new techniques.The origins of our timer system go back to the original MillWheel system, which provided users with direct access to setting timers for triggering processing logic. Conceptually, these are similar to other scheduling systems, where users set an arbitrary number of alarms, and the system is responsible for triggering those alarms at an appropriate time. For durability, we journal these timers to a backing store (like the Cloud Bigtabledatabase), and cache a subset of them in memory, such that all upcoming timers are in memory, and the cache can be refreshed asynchronously without putting storage reads on the hot path. One subtlety for timers arises from the need to support event time timers, which depend on the completeness of data for previous stages in order to trigger. We call these completion markers watermarks, and they are managed by a separate component, which communicates with all the nodes that are responsible for processing a given stage in order to determine current watermark value. This watermark component then publishes these values to all relevant downstream computations, which can use the watermark to trigger event time timers. To help illustrate why this is important, let’s consider a classic IoT use case—a manufacturing line where the equipment is instrumented with sensors. These sensors will emit reams of data, and the watermarks associated with the data will help group together this data by time, or perhaps by manufacturing run, and ensure we don’t miss data in our analysis just because it came in late or out of order.Understanding state managementState management in Dataflow takes advantage of a number of similar concepts as timers. State is journaled to a durable store, and cached for speed and efficiency. One thing that we learned from our experience with MillWheel was the need to provide useful abstractions for users to interact with state—some applications want to read and write the entirety of the stored state for each incoming record, but others want to read only a subset, or append to a list that is only occasionally accessed in full. In Dataflow, we’ve worked hard to provide relevant state abstractions that are integrated with the right caching and persistence strategies, so that the system is efficient and fast out of the box. We’ve also found it important to commit state modifications in an atomic operation with record processing. Many other systems take the approach of telling users to use an external state system, which is very difficult to get working correctly. Thinking back to the IoT use case we just discussed, Dataflow’s state management features would make it easy—meaning involving trivial amounts of user code—to do things like aggregating and counting equipment revolutions per minute, calculating the average temperature from a sensor over a given period of time, or determining the average deviation from a cutting or molding process without complicated retry logic for interacting with a secondary system.A major reason for the popularity of the Lambda Architecture is the challenges of providing exactly once processing in streaming processing systems (see this blog series for additional details). Dataflow provides exactly once processing for records by storing a fingerprint of each record that enters a given stage, and uses that to deduplicate any retries of that record. Of course, a naive strategy for this would create an unbounded number of fingerprints to check, so we use the watermark aggregator to determine when we can garbage-collect the fingerprints of records that have fully traversed the system. This system also makes ample use of caching, as well as some additional optimizations, including the use of rotating Bloom filters.One final aspect of Dataflow that we’ll touch upon is its ability to support autoscaling of pipeline resources. It is able to support dynamic scaling (both up and down) of both streaming and batch pipelines by having a means of dynamically reallocating the underlying work assignments that power the system. In the case of streaming pipelines, this corresponds to a set of key ranges for each computation stage, which can be dynamically shifted, split, and merged between workers to balance out the load. The system responds to changes in usage by increasing or decreasing the overall number of nodes available, and is able to scale these independently from the disaggregated storage of timers and state. To visit our IoT factory floor example one last time, these autoscaling capabilities would mean that adding more sensors or increasing their signal frequency wouldn’t require the long operations and provisioning cycles you would have needed in the past.Next, be sure to check out the third and final blog in this series, which aims to compare and contrast Dataflow with some of the other technologies available in the market.
Quelle: Google Cloud Platform