Videostreaming: Disney+ funktioniert auf einigen Samsung-TVs nicht
Wer einen Samsung-TV besitzt, kann unter Umständen derzeit Disney+ nicht nutzen. (Disney+, Samsung)
Quelle: Golem

Wer einen Samsung-TV besitzt, kann unter Umständen derzeit Disney+ nicht nutzen. (Disney+, Samsung)
Quelle: Golem

Das 60. Firmenjubiläum feiert Sega mit einem Mini-Handheld, das in vier Farben mit jeweils unterschiedlichen Spielen erscheint. (Sega, Games)
Quelle: Golem

Der Bedarf an Videokonferenzen ist dank des Corona-bedingten Homeoffices gestiegen – trotz Sicherheitsbedenken setzen viele auf Zoom. (Zoom, Videotelefonie)
Quelle: Golem
blog.mayadata.io – As OpenEBS Director is a multitenant software, CstorPoolAuto needs to maintain backward compatibility. Hence CstorPoolAuto must manage both versions of CSPC to handle tenants with different OpenEBS v…
Quelle: news.kubernauts.io
containo.us – The Ingress Object itself already has a long history with K8s. It is still considered beta, which is kinda surprising for something that has been so long present in K8s. But why is that? And when wil…
Quelle: news.kubernauts.io
Starting a blog is easy and free on WordPress.com. But what if you’re new to blogging? If you need guidance on best practices, actionable tips on how to grow your audience and find inspiration to write, and constructive feedback from experts and fellow bloggers, you should join us at Blogging: From Concept to Content. It’s a three-day, hands-on, intensive workshop that will take you from “I’m not entirely sure what I’m doing?” to “I’m a blogger!”
Date: June 16–18, 2020Time: 7:00 a.m. – 11:00 a.m. PDT | 8:00 a.m. –12:00 p.m. MDT | 9:00 am-1:00 pm CDT | 10:00 a.m. – 2:00 p.m. EDT| 14:00 – 18:00 UTCLocation: Online via Zoom and private blogCost: Early Bird Price — US$99 until 23:59 UTC on June 8, 2020. Regular price — US$179 from June 9 – June 15, 2020.Register now: https://wordpress.com/blogging-basics-workshop/
Featuring guest speakers and WordPress.com experts in areas like content and writing, SEO, design, and digital marketing, the workshop will include daily assignments and interactive discussions. You’ll also have plenty of opportunities to interact directly with the instructors as well as with Happiness Engineers. At the end of the workshop, you’ll walk away with:
A ready-to-launch blog.An editorial calendar for the next 8–12 weeks.A well-stocked toolkit of tips and techniques to continue to develop your blog and grow its reach.Finally, and at least as important: a community of new blogging friends to learn from and grow with long after the workshop has ended.
We created this workshop for new bloggers who crave a structured, step-by-step approach to creating a blog that reflects their vision and voice, and who don’t want to waste time looking for answers all over the web. Be prepared to dive in and do the work! You won’t regret this investment, and you’ll be in great company.
Seats are limited to facilitate interaction between participants and instructors, so register now to save your slot. By registering this week, you’ll take advantage of our Early Bird Price of US$99 through June 8, after which the regular registration price of $179 will take effect.
See you then!
Quelle: RedHat Stack
Finding the right cloud talent and expertise is important for virtually all businesses today. Almost 70 percent of IT leaders report that hiring was somewhat or extremely difficult in 2019 and that finding qualified cloud computing talent was a top challenge. Our Google Cloud training allows you to build cloud skills while our certifications help organizations grow the expert cloud talent they need to effectively transform their business and help individuals elevate their IT careers with validated cloud skills. As thousands of technical professionals are looking for ways to stay productive and keep their skills current, we have seen a spike in demand for Google Cloud learning resources. In the month of April, enrollments in Google Cloud training on Coursera increased by more than 500% year-over-year. Google Cloud training completions more than doubled year-over-year across all platforms and partners. We’re committed to developing cloud professionals across all stages of their career as well as enabling enterprises who need cloud expertise to respond, adapt, and transform to dynamic market pressures. To help, we continue to grow our training and certification programs to empower both learners and employers.Today, we’re excited to announce three new initiatives. Firstly, we are introducing Google Cloud skill badges which will recognize and help employers identify those of you with demonstrated Google Cloud technology skills. For experienced professionals, we’ve created new six-week learning paths to guide you through the certification preparation journey. Lastly, in response to overwhelming market demand, we’ve made remote certification exams available, so you can take your exam from home. Show your growing cloud skillset with skill badges Demonstrate your growing Google Cloud-recognized skillset to employers and share your progress with your network through exclusive digital Google Cloud skill badges. The digital badges are earned through completing labs and a rigorous hands-on skill test on Qwiklabs. We’ve made Qwiklabs available at no cost for 30 days through the end of 2020, making hands-on practice and skill building accessible to anyone interested in starting a career in cloud. We have several skill badges available now for beginners, such as deploying and managing cloud environments and performing foundational data, machine learning and AI tasks. Get started with free access to Qwiklabs and skill badges here.Start your certification preparation journey These six-week learning paths will outline recommended Google Cloud training to help experienced cloud professionals prepare for either the Associate Cloud Engineer, Professional Data Engineer, or the Professional Cloud Architect certifications. Through our training partner, Pluralsight, the first month of training will be available at no cost as well as 30 days of unlimited Qwiklabs access at no cost. To start, choose either the Associate Cloud Engineer, Professional Data Engineer, or Professional Cloud Architect certification, and we’ll send you a dedicated learning path with relevant training offers. If you’d like to prepare for certifications not covered by the learning paths, you can check out our latest offers for training courses here. If you’re interested in mastering the ability to deploy applications, monitor operations, and manage enterprise solutions, the Associate Cloud Engineer learning path is for you. We recommend at least six months of hands on experience with Google Cloud before attempting the Associate Cloud Engineer exam. To earn the Professional Data Engineer certification, you have to prove your expertise in designing, building, operationalizing, securing, and monitoring data processing systems. We recommend you have three or more years of cloud industry experience and at least one year of experience designing and managing solutions using Google Cloud prior to preparing for this certification. The Google Cloud Professional Cloud Architect certification, which was ranked the highest-paying IT certification for the second year in a row in the US, is recommended for individuals with three or more years cloud industry experience, including at least one year of Google Cloud experience. The learning path for this certification will guide you through how to securely design, develop, and manage robust, scalable, highly available, and dynamic solutions to drive business objectives. Take your certification exam We know many of you have already prepared and are ready to take your certification exams but are unable to do so because exam centers around the world are closed in response to COVID-19. To help, we’re making online proctored testing available for three of our exams; Associate Cloud Engineer, Professional Data Engineer, and Professional Cloud Architect. You can learn more about online proctored testing here and register for exams here. You can start earning your Google Cloud skill badges here. Already have some cloud experience and ready to begin your certification preparation journey? Sign up here to get started with your six-week learning plan.
Quelle: Google Cloud Platform
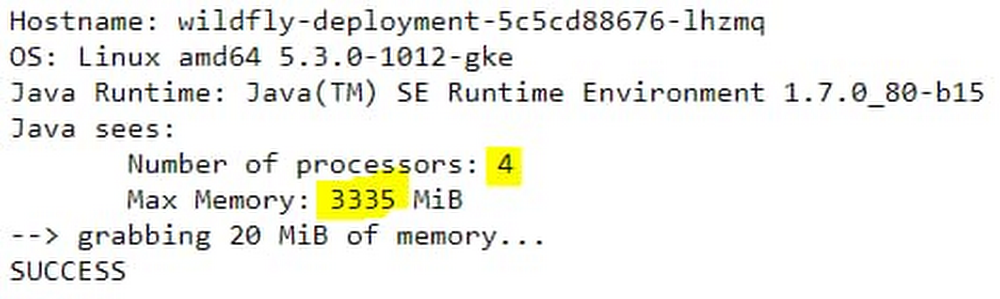
Recently, we’ve been highlighting all the ways that Anthos, our hybrid and multi-cloud application platform, can help you modernize your Java applications and development and delivery processes. This week we’ll focus on how Migrate for Anthos, which takes your existing VM-based applications and intelligently converts them to run in containers on Google Kubernetes Engine (GKE), can also help you move your legacy Java applications. Whether it’s to enable new functionality, decommission an on-premises data center, or to save on maintenance costs, many organizations are actively trying to modernize legacy Java applications—preferably by running them in containers on GKE and Anthos. Unfortunately, the way that some legacy applications acquire resource configuration and usage information is incompatible with standard-issue Kubernetes, and requires some complicated workarounds. To help with this, the most recent release of Migrate for Anthos has a new feature to help streamline and simplify legacy application migration, automatically augmenting container resource visibility for legacy Linux-based applications, such as those that use Oracle Java SE 7 and 8 (prior to update 191). This is crucial if you want to successfully convert your legacy Java applications into containers without having to upgrade or refactor them. Migrate for Anthos helps you successfully move Java applications into containers by transparently and automatically implementing a userspace filesystem that addresses the limitations of the Linux filesystem. As you probably know, Linux uses cgroups to enforce container resource allocations. However, a known issue when running in Kubernetes, is that the Kubernetes node’s procfs /proc file system is mounted by default in the container, and reflects host resources rather than those allocated to the container itself. And because some legacy applications still acquire resource configuration and usage information from files like meminfo and cpuinfo in the /proc directory, rather than from cgroups files, running those applications in a container can result in errors and instability. For example, older Java versions may use the information from meminfo and cpuinfo to determine how much memory to allocate to its JVM heap, how many threads to run in parallel for garbage collection (GC), etc. Running an older Java application in a container that hasn’t been properly configured can result in processes being killed due to out-of-memory errors, which can be difficult to triage and troubleshoot. For legacy applications for which you cannot upgrade Java versions, Migrate for Anthos takes a common approach used in the community: it implements the LXCFS filesystem. It does this without requiring user intervention, special configuration or application rebuild. Our goal is to help you migrate all your applications—not just the easy ones—quickly and effectively, so you can make progress on your modernization goals.The sample legacy Java web applicationLet’s take a look at the difference in behaviors of a legacy Java application migrated with and without Migrate for Anthos. For this test, we’re using a JBOSS 8.2.1 server using an older version of Oracle Java SE 7 update 80. You can download this version from Oracle’s Java SE 7 Archives. We package it in two ways: as a regular Docker container image, and as a server VM from which we have migrated the application to a container using Migrate for Anthos. For the application, we use a sample JBoss node-info application with some additional lines of code to simulate memory pressure for each request served. The following modifications were applied:src/main/java/pl/goldmann/work/helloworld/NodeInfoServlet.javaTesting the application on GKEWhen deploying the two application containers, we apply the following resource restrictions in the GKE Pod spec, allocating 1 vCPU and 1 GiB of RAM, on a GKE node that has 4 vCPU and 16 GiB of RAM:We then run the two application instances. First let’s check basic application output by directing a web browser to the application URL.Here’s what happens on the standard container:But here’s what happens on the Migrate for Anthos migrated container:You can immediately see a difference between the results. In the standard container, as already reported in many such tests, Java reports resource values from the host node, and not from the container resource allocations. In the standard container, the reported maximum heap size is derived from Java 7’s sizing algorithm, which, by default, is one quarter of the host’s physical memory. However, in this case of the Migrate for Anthos migrated container, the values are reported correctly.You can see a similar impact when querying the Java Garbage Collection (GC) threading plan. Connect to shell, and run:java -XX:+PrintFlagsFinal -version | grep ParallelGCThreadsOn the standard container, you get: uintx ParallelGCThreads = 4 {product}But on the migrated workload container, you get: uintx ParallelGCThreads = 0 {product}So here as well, you see the correct concurrency from the Migrate for Anthos container, but not in the standard container.Now let’s see the impact of these differences under load. We generate application load using Hey. For example, the following command generates application load for two minutes, with a request concurrency of 50: ./hey_linux_amd64 -z 2m http://##.###.###.###:8080/node-info/Here are the test results with the standard container:Status code distribution: [200] 332 responses [404] 8343 responsesError distribution: [29] Get http://##.###.###.###:8080/node-info/: EOF [10116] Get http://##.###.###.###:8080/node-info/: dial tcp ##.###.###.###:8080: connect: connection refused [91] Get http://##.###.###.###:8080/node-info/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headersThis is a clear indication that the service is not handling the load correctly, and indeed when inspecting the container logs, we see multiple occurrences of *** JBossAS process (79) received KILL signal ***This is due to an out-of-memory (OOM) error. The Kubernetes deployment took care of automatically restarting the OOM-killed container, during which time the service was unavailable. The reason for this is a miscalculated Java heap size from considering the host resources, instead of the container resource constraints. When not calculated right, Java tries to allocate more memory than available and therefore gets killed, disrupting the app.In contrast, executing the same load test on the container migrated with Migrate for Anthos results in:Status code distribution: [200] 1676 responses [202] 76 responsesThis indicates the application handled the load successfully even when memory pressure was high.Unlock the power of containers for your legacy appsWe showed how Migrate for Anthos automatically augments a known container resource visibility issue in Kubernetes. This helps ensure that legacy applications that run on older Java versions behave correctly after being migrated, without having to manually tune or reconfigure them to fit dynamic constraints applied through the Kubernetes Pod specs. We also demonstrated how the legacy application remains stable and responsive under memory load, without experiencing errors or restarts. With this feature, Migrate for Anthos can help you harness the benefits of containerization and container orchestration with Kubernetes, to modernize your operations and management of legacy applications. You’ll be able to leverage the power of CI/CD with image-based management, non-disruptive rolling updates, and unified policy and application performance management across cloud native and legacy applications, without requiring access to source code or application rewrite. For more information, see our original release blog that outlines support for day-two operations and more or fill out this form for more info (please mention ‘Migrate for Anthos’ in the comment box).
Quelle: Google Cloud Platform

Telefónica lässt Ericsson in den 5G-Core. Huawei und Nokia übernehmen das RAN (Radio Access Network). (Huawei, Telefónica)
Quelle: Golem

Gesundheitspass, Temperaturmessung, Maskenpflicht – sieht so der Urlaubsflug in Corona-Zeiten aus? (Coronavirus, Politik/Recht)
Quelle: Golem