Creating a secure email ecosystem and blocking COVID-19 cyberthreats in India, Brazil, and the UK
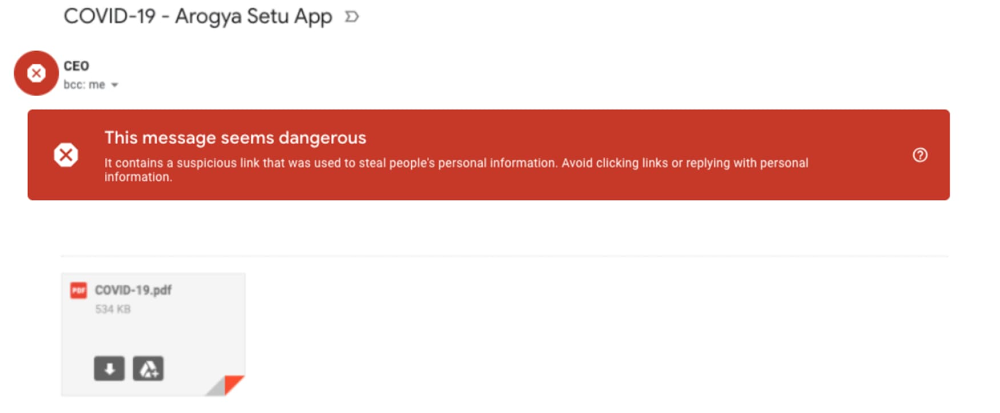
As the world continues to adapt to the changes brought on by the COVID-19 pandemic, cyberthreats are evolving as well. From mimicking stimulus payments, to providing purchase opportunities for items in short supply, bad actors are tailoring attacks to mimic authoritative agencies or exploit fear of the pandemic.Last month, we posted about the large amount of COVID-19 related attacks we were seeing across the globe. At that time, Gmail was seeing 18 million daily malware and phishing emails, and more than 240 million spam emails, specifically using COVID-19 as a lure. To keep you updated on where the threat landscape stands, today we’d like to share some additional email threat examples and trends, highlight some ways we’re trying to keep users safe, and provide some actionable tips on how organizations and users can join the fight.The attacks we’re seeing (and blocking) in India, Brazil, and the UKAs COVID-19 attacks continue to evolve, over the past month we’ve seen the emergence of regional hotspots and threats.Specifically, we’ve been seeing COVID-19-related malware, phishing, and spam emails rising in India, Brazil, and the UK. These attacks and scams use regionally relevant lures, financial incentives, and fear to create urgency and entice users to respond. Let’s look at some examples from these countries.IndiaIn India, we’ve seen an increase in the number of scams targeting Aarogya Setu, an initiative by the Indian Government to connect the people of the country with essential health services.Also, as India is opening back up and employees are getting back to their workplaces, we’re starting to see more attacks masquerading as COVID-19 symptom tracking.And with more and more people looking to buy health insurance in India, phishing scams targeting insurance companies have become more prevalent. Often these scams rely on quoting established institutions, and getting viewers to click on malicious links.The United KingdomWith the UK government announcing measures to help businesses get through the COVID-19 crisis, attackers are imitating government institutions to try to gain access to personal information.These attackers often try to masquerade as Google, as well. But whether they’re imitating the government or Google, these attacks are automatically blocked.BrazilWith the increased popularity of streaming services, we’re seeing increased phishing attacks targeting these services.Here’s another example that relies on fear, suggesting that the reader will be subject to fines if they don’t respond.How we’re blocking novel threats Overall, Gmail continues to block more than 99.9% of spam, phishing, and malware from reaching our users. We’ve put proactive monitoring in place for COVID-19-related malware and phishing across our systems and workflows. In many cases, however, these threats are not new—rather, they’re existing malware campaigns that have simply been updated to exploit the heightened attention on COVID-19. While we’ve put additional protections in place, our AI-based protections are also built to naturally adapt to an evolving threat landscape, picking up new trends and novel attacks automatically. For example, the deep-learning-based malware scanner we announced earlier this year continues to scan more than 300 billion documents every week, and boosts detection of malicious scripts by more than 10%. These protections, newly developed and already existing, have allowed us to react quickly and effectively to COVID-19-related threats, and will allow us to adapt quickly to new ones. Additionally, as we uncover threats, we assimilate them into our Safe Browsing infrastructure so that anyone using the Safe Browsing APIs can automatically stop them. Safe Browsing threat intelligence is used across Google Search, Chrome, Gmail, Android, as well as by other organizations across the globe.G Suite protectionsOur advanced phishing and malware controls come standard with every version of G Suite, and are automatically turned on by default. This is a key step as we move forward to a safe-by-default methodology for Google Cloud products. Our anti-abuse models look at security signals from attachments, links, external images, and more to block new and evolving threats. Keeping email safe for everyoneWhile many of the defenses in Gmail leverage our technology and scale, we recognize that email as a whole is a large and complex network. This is why we’re working not just to keep Gmail safe, but to help keep the entire ecosystem secure. We’re doing this in many ways, from developing and contributing to standards like DMARC (Domain-based Message Authentication, Reporting, and Conformance) and MTA-STS (Mail Transfer Agent Strict Transport Security), to making our technology available to others, as we have with Safe Browsing and TensorFlow Extended (TFX). We’re also contributing to working groups where we collaborate and share best practices with others in the industry. For example, Google is a long-time supporter and contributor to the Messaging, Malware, and Mobile Anti-Abuse Working Group (M3AAWG), an industry consortium focused on combating malware, spam, phishing, and other forms of online exploitation. The M3AAWG community often comes together to support important initiatives, and today we’re co-signing a statement on the importance of authentication. You can help keep email safe for everyone by bringing authentication to your organization.Bringing authentication to your organizationSpeaking of authentication, as we mentioned above, Gmail recommends senders adopt DMARC to help prevent spam and abuse. DMARC uses Sender Policy Framework (SPF) and DomainKeys Identified Mail (DKIM) to help ensure that platforms receiving your email have a way to know that it originally came from your systems. Adopting DMARC has many benefits, including:It can provide a daily report from all participating email providers showing how many messages were authenticated, how often invalidated messages were seen, and what kind of policy actions were taken on those messages It helps create trust with your user base—when a message is sent by your organization, the user receiving it can be sure it’s from youIt helps email providers such as Gmail handle spam and abuse more effectivelyBy using DMARC, we all contribute to creating a safe email ecosystem between providers, organizations, and users. In our previous post, we shared that we worked with the WHO to clarify the importance of an accelerated implementation of DMARC. The WHO has now completed the transition of the entire who.int domain to DMARC and has been able to stop the vast majority of impersonated emails within days after switching to enforcement. You can find more information on setting up DMARC here. Our safety recommendations for users As a user, there are also steps you can take to become even more secure:Take the Security Checkup. We built this step-by-step tool to give you personalized and actionable security recommendations and help you strengthen the security of your Google account.Avoid downloading files that you don’t recognize; instead, use Gmail’s built-in document preview.Check the integrity of URLs before providing login credentials or clicking a link—fake URLs generally imitate real ones and include additional words or domains. Report phishing emails. Turn on 2-step verification to help prevent account takeovers, even in cases where someone obtains your password. Consider enrolling in Google’s Advanced Protection Program (APP)—we’ve yet to see anyone in the program be successfully phished, even if they’re repeatedly targeted. Be thoughtful about sharing personal information such as passwords, bank account or credit card numbers, and even your birthday. Safety and security are a priority for us at Google Cloud, and we’re working to ensure all our users have a safe-by-default experience, no matter what new threats come our way.
Quelle: Google Cloud Platform







