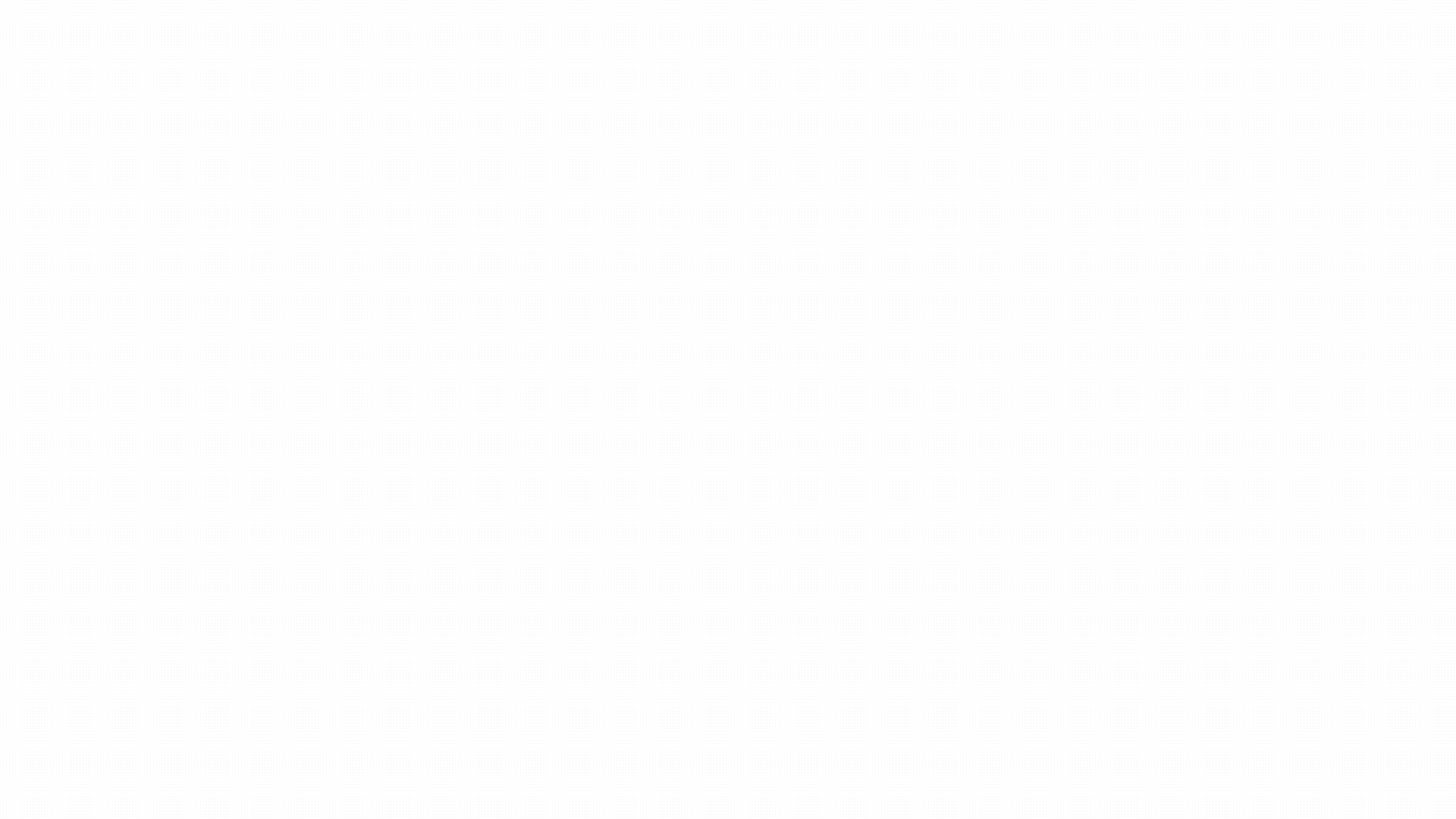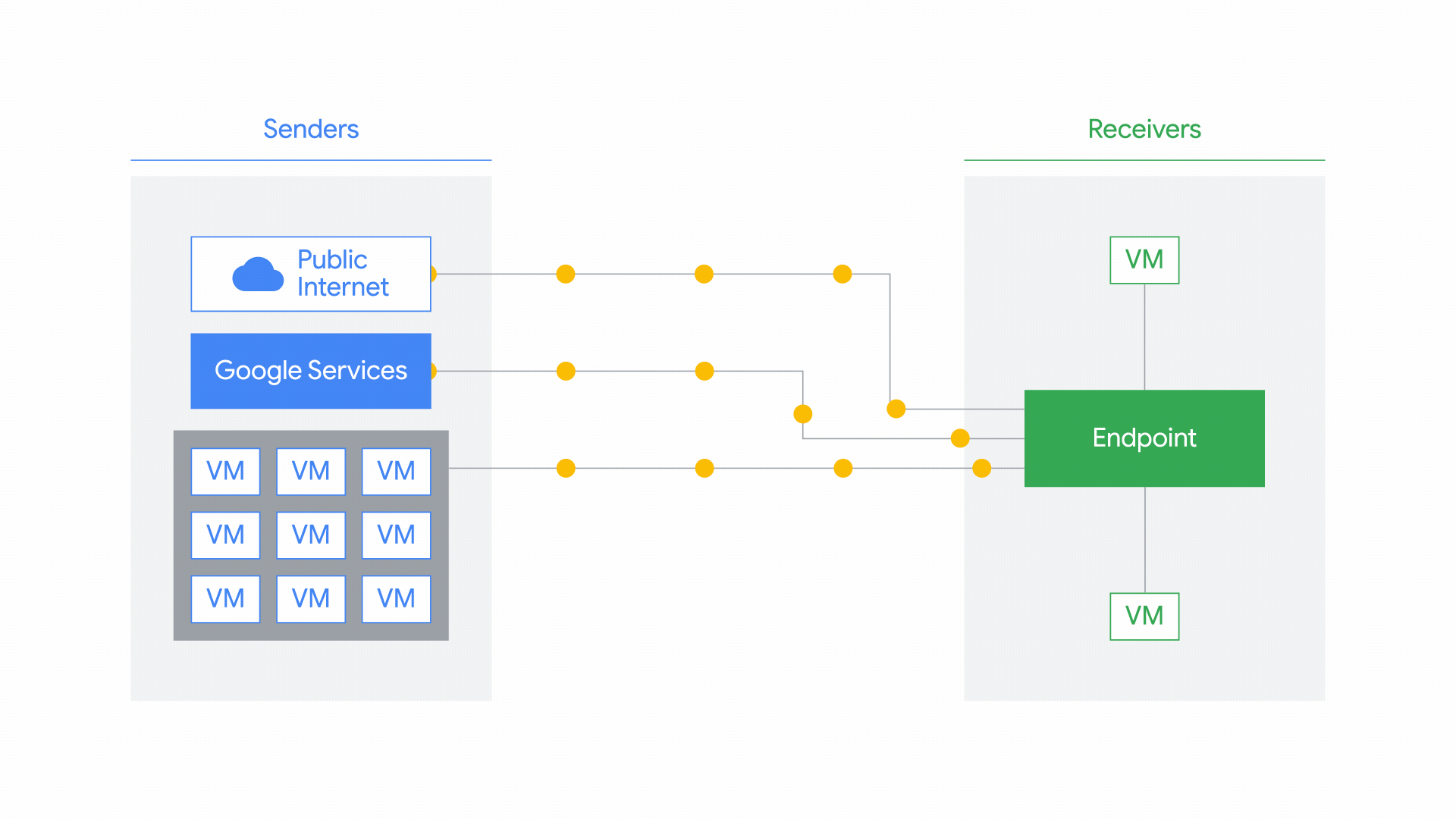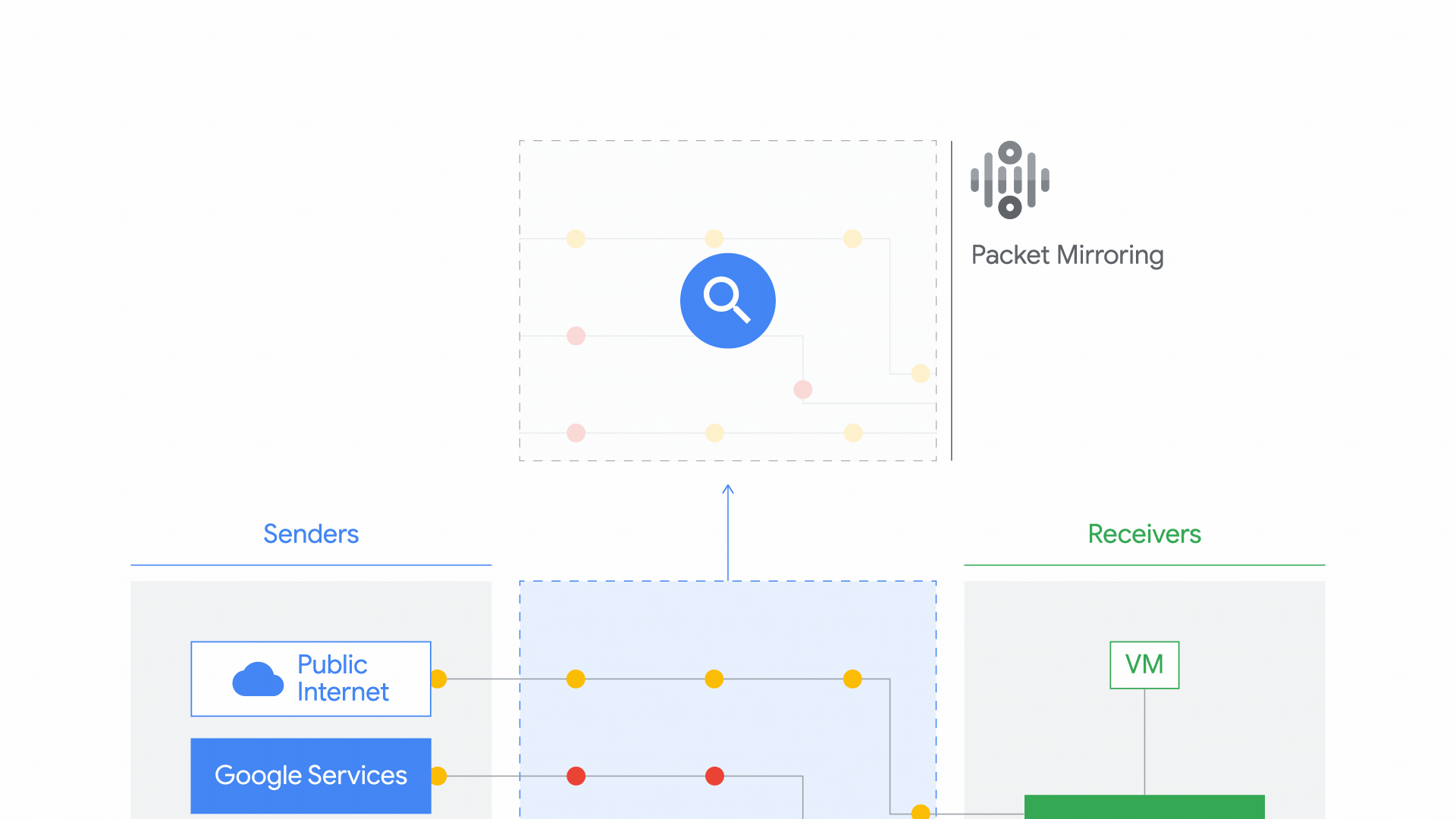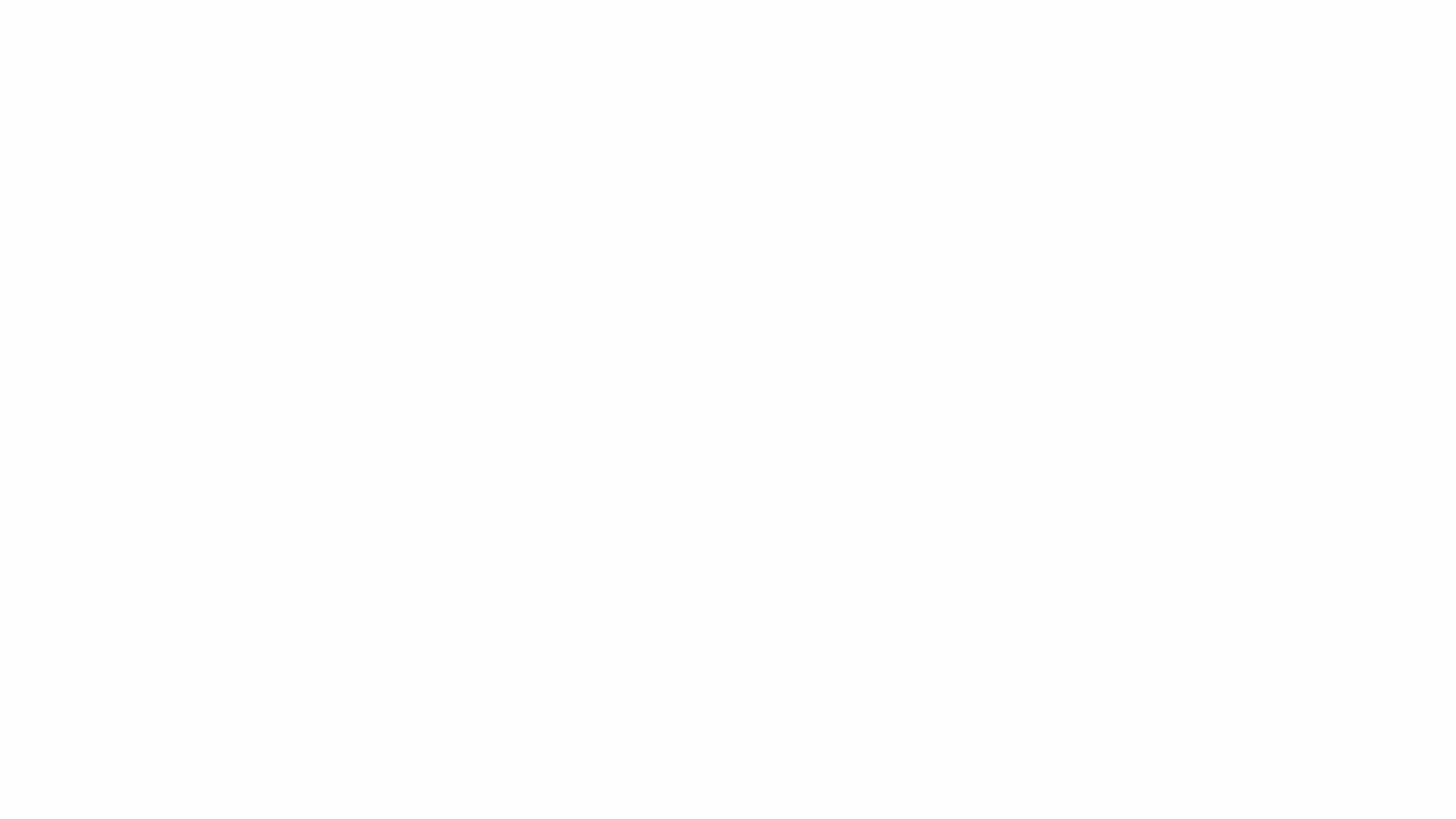
Setting up advanced network threat detection with Packet Mirroring
When you’re trying to detect—or thwart—an attack, the network can be a good line of defense: attackers could compromise a VM and you could lose access to endpoint data, but you likely still have access to network data. An effective threat detection strategy is to use network data, logs, and endpoint data to gain visibility into your network during an attack, so you can investigate the threat quickly and minimize damage.In public cloud environments, getting access to full network traffic can be challenging. Last year, we launched Packet Mirroring in beta, and we’re excited to announce that it’s now generally available. Packet Mirroring offers full packet capture capability, allowing you to identify network anomalies within and across VPCs, internal traffic from VMs to VMs, traffic between end locations on the internet and VMs, and also traffic between VMs to Google services in production. Then, once Packet Mirroring is enabled, you can use third-party tools to collect and inspect network traffic at scale. For example, you can deploy intrusion detection solutions (IDS) or network traffic analysis (NTA) to protect workloads running in Compute Engine and Google Kubernetes Engine (GKE). You can also choose to deploy third-party solutions for network performance monitoring and troubleshooting, especially if you are using one on-prem and prefer to use the same vendor for your hybrid cloud deployment. See the overview video.Packet Mirroring use cases and ecosystemAlready, in a few short months, Packet Mirroring has assumed an important role in early adopters’ network threat detection and analysis practices. Below are the three most common use cases we see with our customers, with Packet Mirroring providing the full packet data captures that get fed to the partner solutions to perform the analysis:Deploy intrusion detection systems – Customers migrating to cloud typically have an IDS deployed on-prem to meet their security and compliance requirements. Packet Mirroring allows you to deploy your preferred IDS in the cloud. And because Packet Mirroring is deployed out-of-band, you don’t have to change your traffic routing or re-architect your application, thereby accelerating your cloud migration. Customers that prefer intrusion prevention and want to block malicious traffic can deploy a next generation firewall in-line and that deployment does not need packet mirroring.Perform advanced network traffic analysis – Sending mirrored data to an NTA tool can help you detect suspicious network traffic that other security tools might miss. Advanced NTA tools leverage machine learning and advanced analytics to inspect mirrored packet data, baselining the normal behavior of the network and then detecting anomalies that might indicate a potential security attack. Gain visibility into network health – You can also integrate Packet Mirroring data into third-party network performance monitoring solutions to gain better visibility into network health, quickly troubleshoot network issues and receive proactive alerts.Packet Mirroring enables these use cases through deep integration with leading network monitoring and security solutions. For example, you could use Google Cloud Packet Mirroring with Palo Alto VM-Series for IDS, helping you meet compliance requirements such as PCI DSS. Or, you could use Packet Mirroring with ExtraHop Reveal(x) to get improved visibility into your cloud (click here to learn how ULTA Beauty scaled its ecommerce operations with that combination). To date, we’ve built an extensive ecosystem of partners, and are actively exploring new ones. Having the right partner solution deployed in conjunction with packet mirroring is critical to get the security insights and avoid missing potential security attacks.Getting started with Packet MirroringTo get started with Packet Mirroring and mirroring traffic to and from particular instances, you need to create a Packet Mirroring policy, which has two parts: mirrored sources and a collector destination. Mirrored sources are compute instances that you can select by specifying subnets, network tags, or instance names. A collector destination is an instance group that is behind an internal load balancer. The mirrored traffic can be sent to the collector destinations where you’ve deployed one of our partners’ network monitoring or security solutions. Within the Google Cloud Console, you can find Packet Mirroring from the VPC Network dropdown menu. First, click “Create Policy” from the UI, then follow these five steps:Define policy overviewSelect VPC NetworkSelect mirrored sourceSelect collector destinationSelect mirrored trafficStep 1: Define policy overviewIn the first step, enter information about the policy, such as the name, or region that includes the mirrored sources and collector destination. Note that the Packet Mirroring policy must be in the same region as the source and destination. You can select Enabled to activate the policy at the time of creation or leave it disabled and enable it later. Step 2: Select VPC networkNext, select the VPC networks where the mirrored source and collector destination are located. The source and destination can be in the same or different VPC networks. If they are in the same VPC network, just select that network. However, if they are in different networks, select the mirrored source network first, and then the collector destination network. If they are in two different networks, make sure the two networks are connected via VPC Peering.Step 3: Select mirrored sourceYou can select one or more mirrored sources. Mirroring happens on the selected instances that you specify by selecting one or more subnets, network tags or instance names. Google Cloud mirrors any instance that matches at least one of your selected sources.Step 4: Select collector destinationTo set the collector destination’s instance group, we recommend that you use managed instance groups for their auto-scaling and auto-healing capabilities. When you specify the collector destination, enter the name of a forwarding rule that is associated with the internal load balancer. You can also create a new internal load balancer if needed. Google Cloud then forwards the mirrored traffic to the collector instances. Then, on the collector instances, deploy a partner solution (e.g. IDS) to perform the advanced threat detection.Step 5: Select mirrored trafficBy enabling Packet Mirroring, Google Cloud mirrors all traffic for the selected instances. If you want to limit the traffic that’s mirrored as part of your policy, select Mirror filtered traffic. You can then specify additional filters such as filtering based on specific protocols (TCP, UDP, ICMP) or specific IP ranges. These filters help you control the volume of mirrored traffic and also manage your costs. Click Submit to create the packet mirroring policy and if your policy is enabled, traffic should get mirrored to the collector instances.Start using Packet Mirroring todayPacket Mirroring is available in all Google Cloud regions, for all machine types, for both Compute Engine instances and GKE clusters. From a pricing perspective, you pay for the amount of traffic that is mirrored, regardless of how many VMs you are running. For details, see Packet Mirroring pricing. Click to learn more about using Packet Mirroring.
Quelle: Google Cloud Platform