Low code programming with Node-RED comes to GCP
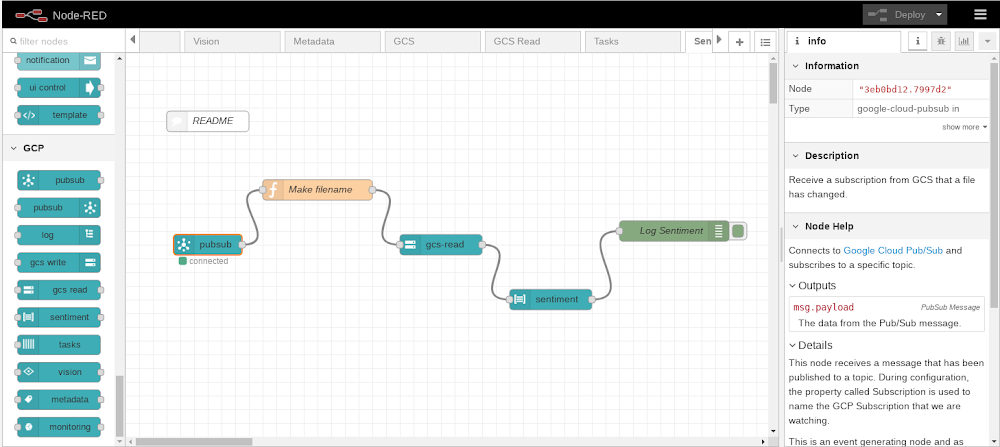
Wouldn’t it be great if building a new application were as easy as performing some drag and drop operations within your web browser? This article will demonstrate how we can achieve exactly that for applications hosted on Google Cloud Platform (GCP) with Node-RED, a popular open-source development and execution platform that lets you build a wide range of solutions using a visual programming style, while still leveraging GCP services.Through Node-RED, you create a program (called a flow) using supplied building blocks (called nodes). Within the browser, Node-RED presents a canvas area alongside a palette of available nodes. You then drag and drop nodes from the palette onto the canvas and link those nodes together by drawing connecting wires. The flow describes the desired logic to be performed by specifying the steps and their execution order, and can then be deployed to the Node-RED execution engine.One of the key features that has made Node-RED successful is its ability to be easily extended with additional custom nodes. Whenever a new API or technology becomes available, it can be encapsulated as a new Node-RED node and added to the list of available nodes found in the palette. From the palette, it can then be added into a flow for use in exactly the same way that the base supplied nodes are used. These additional nodes can then be published by their authors as contributions to the Node-RED community and made available for use in other projects. There is a searchable and indexed catalog of contributed Node-RED nodes.A node hides how it internally operates and exposes a clean consumable interface allowing the new function to be used faster. Now, let’s take a look at how to run Node-RED on GCP and use it with GCP services.Installing Node-REDYou can use the Node Package Manager (npm) to install Node-RED on any environment that has a Node.JS runtime. For GCP, this includes Compute Engine, Google Kubernetes Engine (GKE), Cloud Run, Cloud Shell as well as other GCP environments. There’s also a publically available Docker image, which is what we’ll use for this example.Now, let’s create a Compute Engine instance using the Google Cloud Console and specify the public Node-RED docker image for execution.Visit the Cloud Console and navigate to Compute Engine. Create a new Compute Engine instance. Check the box labeled “Deploy a container image to this VM instance”. Enter “nodered/node-red” for the name of the container image:You can leave all the other settings as their defaults and proceed to completing the VM creation.Once the VM has started, Node-RED is running. To work with Node-RED, you must connect to it from a browser. Node-RED listens on port 1880. The default VPC network firewall deliberately restricts incoming requests which means that requests to port 1880 will be denied. The next step will be to allow a connection into our network at the Node-RED port. We strongly discourage you from opening up Node-RED for development for unrestricted access. Instead, define the firewall rule to only allow ingress from the IP address that your browser presents. You can find your own browser address by performing a Google search on “my ip address”.Connecting to Node-REDNow that Node-RED is running on GCP, you can connect to it from a browser, by passing the external public IP address of the VM at port 1880. For example:http://35.192.185.114:1880You can now see the Node-RED development environment within your browser:Working with GCP nodesAt this point, you have Node-RED running on GCP and can start constructing flows by dragging and dropping nodes from the palette onto the canvas and wiring them together. The nodes that come pre-supplied are merely a starter set—there are many more available that you can install and use in future flows. At Google, we’ve built a set of GCP nodes to illustrate how to extend Node-RED to interact with GCP functions. To install these nodes, navigate to the Node-RED system menu and select “Manage palette”:Switch to the Palette tab and then switch to the Install tab within Palette. Search for the node set called “node-red-contrib-google-cloud” and then click install.Once installed, scroll down through the list of available palette nodes and you’ll find a GCP section containing the currently available GCP building blocks.Here’s a list of currently available GCP nodes:PubSub in – The flow is triggered by the arrival of a new message associated with a named subscriptionPubSub out – A new message is published to a named topicGCS read – Reads the content of a Cloud Storage objectGCS write – Writes to a new Cloud Storage objectLanguage sentiment – Performs sentiment analysis on a piece of textVision – Analyzes an image for distinct attributesLog – Writes a log message to Stackdriver LoggingTasks – Initiates a Cloud Tasks instanceMonitoring – Writes a new monitoring record to StackdriverSpeech to Text – Converts audio input to a textual data representationTranslate – Converts textual data from one language to anotherDLP – Performs Data Loss Prevention processing on input dataBigQuery – Interacts with Google’s BigQuery databaseFireStore – Interacts with Google’s Firestore databaseMetadata – Retrieves the metadata for the Compute Engine upon which Node-RED is runningGoing forward, we hope to make additional GCP nodes available. It’s also not hard to create a custom node yourself—check out the public Github repository to see how easy it is to create one.A sample Node-RED flowHere is an example flow:At a high level, this flow listens on incoming REST requests and creates a new Google Cloud Storage object for each request received.This flow starts with an HTTP input node which causes Node-RED to listen on the /test URL path for an HTTP GET request. When an incoming REST request arrives, the incoming data undergoes some manipulations:Specifically, two fields are set: one called msg.filename, which is the name of a file to create in Cloud Storage, and the other called msg.payload, which is the content of the new file we are creating. In this example, the query parameters passed in the HTTP request are being logged.The next node in the flow is a GCP node that performs a Cloud Storage object write that writes/creates a new file. The final node sends a response back concluding the original HTTP request that triggered the flow.Securing Node-REDNode-RED is designed to get you up and running as quickly as possible. To that end, the default environment isn’t configured for security. We don’t recommend this. Fortunately, Node-RED provides security features that can be quickly enabled. These features include authorization to be able to make flow changes and enablement of SSL/TLS for encryption of incoming and outgoing data. When initially studying Node-RED, define a firewall rule that only permits ingress from your browser’s IP address.Visual programming on GCP the Node-RED wayNode-RED has proven itself as a data flow and event processor for many years. Its extremely simple architectural model and low barrier to entry means that even a novice user can get value from it in a very short period of time. A quick Internet search reveals many tutorials on YouTube, the documentation is mature and polished, and the community active and vibrant. With the addition of the rich set of GCP nodes that we’ve contributed to the community, you can now incorporate GCP services into Node-Red whether it’s hosted on GCP, on another public cloud, or on-premises. ReferencesNode-RED – The Node-RED home pageGithub: Google Cloud Node-RED repositorySecuring Node-RED
Quelle: Google Cloud Platform


