Google Cloud Firewall Rules Logging: How and why you should use it
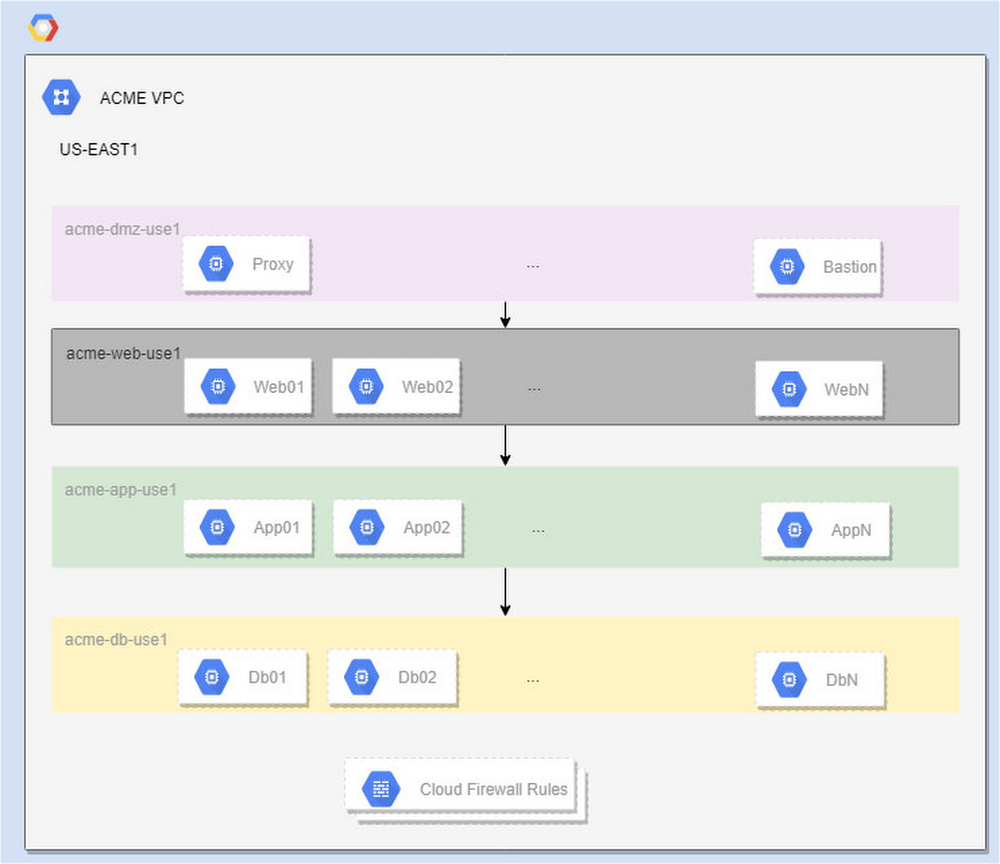
Google Cloud Platform (GCP) firewall rules are a great tool for securing applications. Firewall rules are customizable software-defined networking constructs that let you allow or deny traffic to and from your virtual machine (VM) instances. To secure applications and respond to modern threats, firewall rules require monitoring and adjustment over time. GCP Firewall Rules Logging, which Google Cloud made generally available in February 2019, is a feature that allows the network administrators to monitor, verify and analyze the effects of firewall rules in Google Cloud. In this blog (the first of many on this topic), we’ll discuss the basics of Firewall Rule Logging, then look at an example of how to use it to identify mislabeled VMs and refine firewall rules with minimal traffic interruption.GCP Firewall Rules Logging: The BasicsFirewall Rules Logging provides visibility to help you better understand the effectiveness of rules in troubleshooting scenarios. It helps answer common questions, like: How can I ensure the firewall rules are doing (or not doing) what they were created for?How many connections match the firewall rules I just implemented? Are firewall rules the root cause of some application failures?Unlike VPC flow logs, firewall rules logs are not sampled. Every connection is logged (subject to some limits. Please refer to the Appendix for details). The Firewall Rule log format can be found here.Additionally, network administrators have the options to export firewall logs toGoogle Cloud Storage for long term log retention,to BigQuery for in-depth analysis using standard SQL, or to Pub/Sub to integrate with popular security information and event management software (SIEM), such assplunk for detecting/alerting traffic abnormalities and threats at near real time.For reference, GCP firewall rules are software-defined constructs with the following properties:GCP firewalls are VM-centric. Unlike traditional firewall devices, which are applied at the network edge, GCP firewall rules are implemented at VM level. This means the firewall rules can exist between your instances and other networks, and also between individual instances within the same VPC.GCP firewall rules always have targets. The targets are considered source VMs when defining egress firewall rules, and destination VMs when defining ingress firewall rules. Do not confuse “target” with the “destination” in the traditional firewall concept.GCP firewall rules are defined within the scope of aVPC network. There is no concept of subnets when defining firewall rules. However, you can specify source CIDR ranges, which give you better flexibility than subnets.Every VM has two immutable implied firewall rules: implied allow of egress, and implied deny of ingress at lowest priority. However, Firewall Rule Logging does not generate any entries for these implied firewall rules.While GCP firewall rules support many protocols—including TCP, UDP, ICMP, ESP, AH, SCTP, and IPIP—Firewall Rule Logging only logs entries for TCP and UDP connections.Firewall Best Practices Follow the least privilege principle — make firewall rules as tight as possible. Only allow well-documented and required traffic (ingress and egress), and deny all others. Use a good naming convention to indicate each firewall rule’s purpose.Use fewer and broader firewall rule sets when possible. Observe the standard quota of 200 firewall rules per project. The complexity of the firewall also matters. A good rule of thumb is to not throw too many atoms (tags/service accounts, protocols/ports, source/destination ranges) at the firewall rules. Please refer to the Appendix for more on firewall quota/limits.Progressively define and refine rules; start with the broader rules first, and then use rules to narrow down to a smaller set of VMs.Isolate VMs using service accounts when possible. If you can’t do that, use network tags instead. But do not use both. Service account access is tightly controlled by IAM. While network tags are more flexible, anyone with the instanceAdmin role can change them. More on filtering using service accounts versus network tags can be foundin our firewall rules overview.Conserve network space by planning proper CIDR blocks (segmentations) for your VPC network to group related applications in the same subnet.Use firewall rule logging to analyze traffic, detect misconfigurations, and report real-time abnormalities.In practice, there are many uses for Firewall Rule Logging. One common use case is to help identify mislabeled VM instances. Let’s walk through this scenario in more detail.Scenario: Mislabeled VM instancesACME, Inc. is migrating on-prem applications to Google Cloud. Their network admins implemented a shared VPC to centrally manage the entire company’s networking infrastructure. There are dozens of applications, run by multiple engineering teams, deployed in each GCP region with multi-tiered applications. User-facing proxies in the DMZ talk to the web servers, which communicate with the application servers, which, talk to database layers.This diagram represents one of many regions, each of which has multiple subnets. This region, US-EAST1, includes:acme-dmz-use1: 172.16.255.0/27acme-web-use1: 10.2.0.0/22acme-app-use1: 10.2.4.0/22acme-db-use1: 10.2.8.0/22Here are the traffic directions and firewall rules in place for this region:Proxy can access web servers in acme-web-use1:firewall rule: acme-web-use1-allow-ingress-acme-dmz-use1-proxyWeb servers can access app servers in acme-app-use1:firewall rule: acme-app-use1-allow-ingress-acme-web-use1-webserverApp servers can access database servers in acme-db-use1:firewall rule: acme-db-use1-allow-ingress-acme-app-use1-appsvrThis setup has granular partitions of network space that categorize compute resources by application function. This makes it possible for firewall rules to control the network space and lock the network infrastructure to comply with the least-privilege principle.For large organizations with thousands of VMs provisioned by dozens of application teams, we use service accounts or network tags to group the VMs, in conjunction with subnet CIDR ranges to define firewall rules. For simplicity, we use the network tags to demonstrate each use case.The problemIt’s not unusual for large enterprises to have hundreds of firewall rules due to the scale of the infrastructure and the complexity of network traffic patterns.With so much going on, it’s understandable, that application teams sometimes mislabel the VMs when they migrate them from on-prem to cloud and scale-up applications after migration. The consequences of mislabeling range from an application outage to a security breach. The same problem can also arise if we (mis)use service accounts.Going back to our example, an ACME application team mislabeled one of their new VMs as “appsrv” when it should actually be “appsvr”. As a result, the web server’s requests to access app servers are denied.Solution 1In order to identify the mislabeling and mitigate the impact quickly, we can enable the firewall rule logging for all the firewall rules using the following gcloud command.Next, we export the logs to BigQuery for further analysis with following steps: Create a BigQuery dataset to store the Firewall Rule Log entries:Create the BigQuery sink to export the firewall rules logs:You can also export individual firewall rules by adding filters on the jsonPayload.rule_details.reference. Here is a sample filter:When the BigQuery sink is created, a service account is generated automatically by the GCP. The service account follows the naming convention of “p<project_number>-[0–9]*@gcp-sa-logging.iam.gserviceaccount.com” and is used to write the log entries to the BigQuery table. We need to grant this service account the Data Editor role on the BigQuery dataset as following three steps:Once the logs are populated to the BigQuery sink, you can run queries to determine which rule denies what as following:The BigQuery table will be loaded with the log entries from the logFileName filter, which, in this case, contains all the firewall rules logs. The BigQuery table schema is directly mapped to the log entry’s json format. To keep it simple, for our example we’ll use the log viewer to inspect the log entries.Since we have implicit ingress and the denial rule is not being logged, we create a “deny all” rule with priority 65534 to capture anything that gets denied.The firewall rules for this scenario are:As we can see in the viewer, “acme-deny-all-ingress-internal” is taking effect, and “acme-allow-all-ingress-internal” is disabled, so we can ignore it.Below, we can see that the connection from websvr01 to the new appsvr02 (with the incorrect “appsrv” label) is denied.While this approach works for this example, it presents two potential problems:If we have a large amount of traffic, it will generate too much data for real-time analysis. In fact, one of our clients implemented this approach and ended up generating 5TB of firewall logs per day.Mislabeled VMs can cause traffic interruptions. The firewall is doing what it is designed to do, but nobody likes outages.So, we need a better approach to address both of the issues above.Solution 2To resolve the potential issues mentioned above, we can create another ingress rule to allow all traffic at priority 65533 and turn it on for a short period of time whenever there are new deployments.In this scenario, we don’t need to turn on all the Firewall Rules Logging. In fact, we could turn off most of it to save space.Any allowed evaluation logged by this firewall rule is a violator, and we do not expect many of them. The suspects are identified in real time.Now, we fix the label.As we can see, the connection from websvr01 to appsvr02 now works fine.After all the mislabels are fixed, we can turn off the allow and capture rule. Everyone is happy… until the next time new resources are added to the network.ConclusionWith Firewall Rules Logging, we can refine our firewall rules by following a few best-practices and identify undesired network traffic in near real-time. In addition to firewall rules logging, we’re always working on more tools and features to make managing firewall rules and network security in general easier. AppendixFirewall quotas and limitsThe default quota is 200 firewall rules per project, but can be bumped up to 500 through quota requests. If you need more than 200 firewall rules, we recommend that you review the firewall design to see whether there is a way to consolidate the firewall rules. The upcoming hierarchical firewall rules can define firewall rules at folders/org level, and are not counted toward the per-project limit.The maximum number of source/target tags per firewall rule is 30/70, and the maximum number of source/target per service account is 10/10. A firewall rule can use network tags or service accounts, but not both.As mentioned, the complexity of the firewall rules also matters. Anything that is defined in firewall rules, such as source ranges, protocol/ports, network tags, and service accounts, counts towards an aggregated per-network hard limit. This number is at the scale of tens of thousands, so it doesn’t concern most customers, except in rare cases where a large enterprise may reach this limit.There are per-VM maximum number of logged connections in a 5-second interval depending on machine types: f1-macro (100), g1-small (250), and other machine types (500 per vCPU up to 4,000 in total).
Quelle: Google Cloud Platform







