Acacia Communications: Cisco kauft für 2,84 Milliarden Dollar optischen Ausrüster
Cisco braucht Transponder für Glasfasernetze, die sehr hohe Datenraten erreichen. Dafür wird Acacia Communications übernommen. (Cisco, Prozessor)
Quelle: Golem

Cisco braucht Transponder für Glasfasernetze, die sehr hohe Datenraten erreichen. Dafür wird Acacia Communications übernommen. (Cisco, Prozessor)
Quelle: Golem

Nach Niedersachsens Ausstieg beim Digitalradio DAB+ warnt der Intendant von Deutschlandradio vor der Alternative 5G. Diese sei teuer und der Ausbau der Netze dauere noch viele Jahre. (Fernsehen, Technologie)
Quelle: Golem

Die aktuelle Version 68 des Firefox liefert Nutzern eine neue Verwaltung für Addons und Erweiterungen, baut das Blocken von unerwünschten Inhalten aus und liefert einen dunklen Lesemodus. Das Zusammenspiel mit Antivirus-Software wird auch besser. (Firefox, Browser)
Quelle: Golem
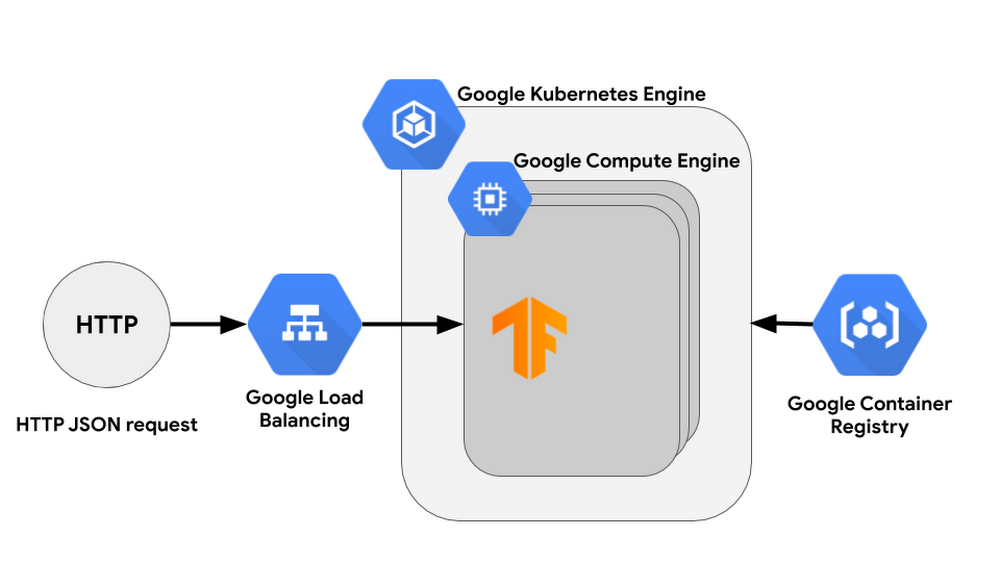
Editor’s note: Today’s post comes from Rustem Feyzkhanov, a machine learning engineer at Instrumental. Rustem describes how Cloud Functions can be used as inference for deep learning models trained on TensorFlow 2.0, the advantages and disadvantages of using this approach, and how it is different from other ways of deploying the model.TensorFlow is an established framework for training and inference of deep learning models. Recent updates to version 2.0 offer a number of enhancements, including significant changes to eager execution. But one of the challenges with this new framework is deploying TensorFlow 2.0 deep learning models. Google Cloud Functions offer a convenient, scalable and economic way of running inference within Google Cloud infrastructure and allows you to run the most recent version of this framework.This post will explain how to run inference on Cloud Functions using TensorFlow 2.0.We’ll explain how to deploy a deep learning inference including:How to install and deploy Cloud FunctionsHow to store a modelHow to use the Cloud Functions API endpointThe components of our systemGoogle Cloud Platform (GCP) provides multiple ways for deploying inference in the cloud. Let’s compare the following methods for deploying the model:Compute Engine cluster with TF servingCloud AI Platform PredictionsCloud FunctionsTensorFlow ServingTypically you might use a cluster as inference for the model. In this case, TF servingwould be a great way to organize inference on one or more VMs —then, all you need to do is add a load balancer on top of the cluster. You can use the following products to deploy TF serving in AI Platform:Deep Learning VM imagesDeep Learning Containers This approach has the following advantages:Great response time as the model will be loaded in the memoryEconomy of scale, meaning cost per run will decrease significantly when you have a lot of requestsAI Platform PredictionsAI Platform provides an easy way to serve pre-trained models through AI Platform Predictions. This has many advantages for inference when compared to the cluster approach:Codeless inference makes getting started easyScalable infrastructureNo management of infrastructure requiredSeparate storage for the model, which is very convenient for tracking versions of the model and for comparing their performanceNote: You can use Cloud Functions in combination with AI Platform Predictions (you can learn more in this post).Cloud FunctionsWhen comparing Deep Learning VMs and AI Platform Predictions, the full serverless approach provides the following advantages:Simple code for implementing the inference, which at the same time allows you to implement custom logic.Great scalability, which allows you to scale from 0 to 10k almost immediatelyCost structure which allows you only to pay for runs, meaning you don’t pay for idle servers.Ability to use custom versions of different frameworks (Tensorflow 2.0 or PyTorch)In summary, please take a look at this table:Since Google Cloud also provides some free invocations of Cloud Functions per month, this kind of setup would be perfect for a pet project or for a start-up that wants to get early customer feedback on a prototype. Also, it would be useful in cases where you have to process peak loads. The downside would be that in cases where the model is too big, the cold start could take some time and it would be very hard to achieve real-time performance. Also we need to keep in mind that serverless infrastructure doesn’t provide economy of scale, meaning the price of an individual run won’t go down when you have a large number of requests, so in these types of cases, it may be cheaper to use a cluster with TF serving as inference.As we can see, Compute Engine pricing per hour looks extremely attractive (with utilizing preemptible instances or commitment use, the price will be even lower), but the catch here is that cost of instance is per one second, with a minimum of one minute. Cloud Functions, on the other hand, have billing per 100ms without a minimum time period. This means Cloud Functions are great for short, inconsistent jobs, but if you need to handle a long, consistent stream of jobs, Compute Engine might be a better choice.Architecture OverviewOur system will be pretty simple. We will train the model locally and then upload it to Google Cloud. Cloud Functions will be invoked through an API request and will a download model and a test image from Cloud Storage.There are several things to consider when you design a system to use serverless infrastructure as an inference.First of all, keep in mind differences between cold invocation, when the function needs time to download and initialize the model, and warm invocation, when function uses a cached model. Increasing the ratio of warm invocations to cold invocations not only allows you to increase processing speed, it also decreases the cost of your inference. There are multiple ways you can increase the ratio. One way could be warming up functions so they will be warm when a high load comes in. Another way is to use Pub/Sub to normalize a load so that it will be processed by warm containers.Secondly, you can use batching to optimize the cost and speed of processing. Because a model can run on the whole batch instead of running separately on each image, batching allows you to decrease the difference between cold and warm invocation and improve overall speed.Finally, you can have some part of your model saved as part of your libraries. This allows you to save time downloading the model during cold invocation. You could also try to divide the model into layers and chain them together on separate functions. In this case, each function will send an intermediate activation layer down the chain and neither of the functions would need to download the model.CostIn the demo which we will deploy we use 2GB Cloud Function. Cold invocation takes 3.5s and warn invocation takes 0.5s. In terms of pricing we get 0.0001019$ per cold invocation and 0.0000149$ per warm invocation. It means that for 1$ we get ~10k cold invocations and ~65k warm invocations. With free tier provided by Google Cloud you would get for free ~20k cold invocations and ~140k warm invocations per month. Feel free to check the pricing for your use cases using pricing calculator.TensorFlow 2.0 exampleFirst, let’s install Tensorflow 2.0 beta on your computer. You can install it either on your system python or by creating a virtual environment:Let’s use fashion MNIST with TensorFlow 2.0b as an example. Here is how the code for training and exporting model weights would look like:Based on the example:The code will produce the following files:We will need to store the model separately from the code as there is a limit on local file size on the Cloud Functions. You can upload them to the Cloud Storage bucket along with the test image.Cloud FunctionsOne of the main upsides of Cloud Functions is that you don’t have to manually generate the package. You can just use a requirements.txt file and list all used libraries there. Also, remember to have the model as a global variable in your python code so it will be cached and reused in warm invocations of Cloud Functions.Therefore we will have two files:requirements.txtand main.pyDeployment through the command lineYou can easily deploy and run Cloud Functions using gcloud.The response would be:Deployment through the web consoleFirst, let’s start from the Cloud Functions dashboard. To create a new Cloud Function, choose the “Create function” button. In the “Create function” window, set the function’s name (“tensorflow2demo”), allocated memory (2 GB in our case for the best performance), trigger (HTTP trigger in our case) and runtime (python 3.7).Next, set the main.py and requirements.txt files. You can just copy the code and libraries from the files at the repo. Finally, w push the “Create” button and initialize the creation of the function.Once the function is deployed, you can test it in the “Testing” section of theCloud Functions dashboard. You can also customize incoming events and see output as well as logs.As you can see, our pretrained model successfully classified image as trousers. If we run the functions one more time, we will see that it will run a lot faster because we saved the model to the cache and won’t need to reload it during warm invocation.ConclusionWith this post, you should now be able to create a TensorFlow 2.0 endpoint on GCloud Functions. Setting the project up is easy, and can save a lot of time when compared to the traditional approach of using a cluster of VMs. As you can see, Cloud Functions provide an easy way to start with contemporary frameworks and deploy pre-trained models in a matter of minutes. As a hobby, I port a lot of libraries to make the serverless friendly. Feel free to check my repos with other examples like headless chrome or pandas with numpy on Cloud Functions. They all have an MIT license, so feel free to modify and use them for your project.Learn more about Cloud Functions here, and consider starting a free trial.Acknowledgements: Gonzalo Gasca Meza, Developer Programs Engineer contributed to this post.
Quelle: Google Cloud Platform

Cloud Memorystore for Redis provides a fully managed Redis service on Google Cloud Platform (GCP) that lets you build low-latency, highly scalable applications. This in-memory data store brings super-fast access to data, and is used for caching, session stores, rate limiting, job queues, fast ingest, messaging and more. Since the beta launch, one of the most requested features has been the ability to migrate data into Cloud Memorystore and back up instance data, in order to leverage fully managed Cloud Memorystore services. We are pleased to announce the availability of import-export in beta for Cloud Memorystore, which lets you import data into Cloud Memorystore instances using RDB (Redis Database Backup) snapshots, as well as back up data from existing Redis instances. The use of the RDB format allows seamless migration of your data in and out of Google Cloud.Along with import-export, we are also pleased to announce the general availability of support for Redis version 4.0. How to use import-exportThe new import-export feature allows you to import and export data using the native Redis RDB format. Once you import the RDB file, it will be stored in a Google Cloud Storage bucket of your choosing, so you have control over where your files are located. To import data into Cloud Memorystore, start by backing up your existing instance data using BGSAVE, the native Redis command that will take an RDB snapshot. Once you have the RDB file, upload it into a regional Cloud Storage bucket. Once the file is available in a regional bucket, it is very easy to import the file into a Cloud Memorystore instance. To do this, in the GCP Console, navigate to the instance details page and select “Import,” then select the RDB file you want to bring in. Click on the “Import” button.Exporting data from an instance is similar; simply choose the Cloud Storage bucket where you want to store the RDB file being exported. To learn more, check out the documentation. And take a look at this session from Next ‘19 to see a Cloud Memorystore for Redis demo:What’s next for Cloud MemorystoreWe are continuing to work on top requests from our customers. Stay tuned for new features, like updated Redis versions. Let us know what other features and capabilities you’d like to see with our Issue Tracker and by joining the Cloud Memorystore discussion group.
Quelle: Google Cloud Platform

A leader in geosciences, CGG has been imaging the earth’s subsurface for more than 85 years. Their products and solutions help clients locate natural resources. When a customer asked whether the cloud could speed the creation of the high-resolution reservoir models that they needed, CGG turned to Azure high performance computing (HPC).
CGG is a team of acknowledged imaging experts in the oil and gas industry. Their subsurface imaging centers are internationally acclaimed, and their researchers are regularly recognized with prestigious international awards for their outstanding technical contributions to the industry. CGG was an early innovator in seismic inversion, the technique of converting seismic survey reflection data into a quantitative description of the rock properties in an oil and gas reservoir. From this data, highly detailed models can be made, like the following image showing the classification of rock types in a 3D grid for an unconventional reservoir interval. These images are invaluable in oil and gas exploration. Accurate models help geoscientists reduce risk, drill the best wells, and forecast production better.
The challenge is to get the best possible look beneath the surface. The specialized software is compute-intensive, and complex models can take hours or even days to render.
Figure 1. An advanced seismic model, using CGG’s Jason RockMod.
Azure provides the elasticity of compute that enables our clients to rapidly generate multiple high-resolution rock property realizations with Jason RockMod for detailed reservoir models.”
– Joe Jacquot, Strategic Marketing Manager, CGG GeoSoftware
The challenge: prove it in the cloud
An oil and gas company in Southeast Asia asked CGG to work with them to find the optimum way to deploy reservoir characterization technology for their international team. The customer also wondered if they could take advantage of the cloud to save on hardware costs in their datacenter, where they already ran leading-edge CGG geoscience software solutions. They knew the theory of the cloud’s elasticity and on-demand scalability were familiar with its use in oil exploration, but they didn’t know if their applications would perform as well in the cloud as they did on-premises.
In a rapidly moving industry, performance gains translate to speedier decision making, accelerated exploration, and development timelines, so the company asked CGG to provide a demonstration. As geoscience experts, CGG wanted to show their software in the best possible light. They turned to the customer advisors at AzureCAT (led by Tony Wu) for help creating a proof of concept that demonstrated how the cloud capacity could help the company get insights faster.
Demo 1: CGG Jason RockMod
CGG Jason RockMod overcomes the limitations of conventional reservoir characterization solutions with a geostatistical approach to seismic inversion. The outcome is accurate reservoir models so in depth that geoscientists can use them to predict field reserves, fluid flow patterns, and future production.
The company wanted to better understand the scale of the RockMod simulation in the cloud, and wondered whether the cloud offered any real benefits compared to running the simulations on their own workstations.
Technical teams from CGG and AzureCAT looked at RockMod as a big-compute workload. In this type of architecture, computationally intensive operations such as simulations are split across CPUs in multiple computers (10 to 1,000s). A common pattern is to administer a cluster of virtual machines, then schedule and monitor the HPC jobs. This do-it-yourself approach would enable the company to set up their own cluster environment in Azure virtual machine scale sets. The number of VM instances can automatically scale per demand or on a defined schedule.
RockMod creates a family of multiple equi-probable simulation outputs, called realizations. In the proof of concept tests for their customer, CGG ran RockMod on a Microsoft Windows virtual machine on Azure. It served as the master node for job scheduling and distribution of multiple realizations across several Linux-based HPC nodes in a virtual machine scale set. Scale sets support up to 1,000 VM instances or 300 custom VM images, more than enough scale for multiple realizations.
An HPC task generates the realizations, and the speed depends on the number of CPU cores or non-hyperthreading more than the processor speed. AzureCAT recommended non-hyperthreading cores as the best choice for application performance. From a storage perspective, the realizations are not especially demanding. During testing, the storage IO rate went up to a few hundred megabytes per second (MB/s). Based on these considerations, CGG chose the cost-effective DS14V2 virtual machine with accelerated networking, which has 16 cores and 7 GB per core.
“Azure provided the ideal blend of HPC and storage performance and price, along with technical support that we needed to successfully demonstrate our high-end reservoir characterization technology on the cloud. It was a technical success and paved the way for full-scale commercial deployment.”
– Joe Jacquot, Strategic Marketing Manager, CGG GeoSoftware
Figure 2. Azure architecture of CGG Jason RockMod.
Benchmarks and benefits
A typical project is about 15 GB in size and includes more than three million seismic data traces. Some of the in-house workstations could render a single realization within a day or two, but the goal was to run 30 realizations by taking advantage of the cloud’s scalability. The initial small scale test ran one realization on one HPC node, which took just under 12 hours to complete. That was within the target range, and now the CGG team needed to see what would happen when they ran at scale.
To test the linear scalability of the job, they first ran eight realizations on eight nodes. The results were nearly identical to the small scale test run. The one realization to one node formula seemed to work. For the sake of comparison, they tried running 30 realizations on just eight nodes. That didn’t work so well, the tests were nearly four times slower.
The final test ran 30 realizations on 30 nodes, one realization to one node. The results were similar to the small scale test, and the job was completed in just over 12 hours. This scenario was tested several times to validate the results which were consistent. The test was a success.
Demo 2: CGG InsightEarth
In their exploration and development efforts, the company also used CGG InsightEarth, a software suite that accelerates 3D interpretation and visualization.
The interpretation teams at the company were using several InsightEarth applications to locate hydrocarbon deposits, faults and fractures, and salt bodies all of which can be difficult to interpret. They asked CGG to compare the performance of the InsightEarth suite on Azure to their workstations on premises. Their projects were typically 15 GB in size, with more than three million seismic data traces.
InsightEarth is a powerful, memory-intensive application. To get the best performance, the application must run on a GPU-based computer, and to get the best performance from GPUs, efficient memory access is critical. To meet this requirement on Azure, the team of engineers from CGG and AzureCAT looked at the specialized, GPU-optimized VM sizes that are available. The Azure NV-series virtual machines are powered by NVIDIA Tesla M60 GPUs and the NVIDIA GRID technology with Intel Broadwell CPUs, which are suited for compute-intensive visualizations and simulations.
The GRID license gives the company the flexibility to use an NV instance as a virtual workstation for a single user, or to give 25 users concurrent access to the VM running InsightEarth. The company wanted the collaborative benefits of the second model. Unlike a physical workstation, a cloud-based GPU virtual workstation would allow them all to view the data after running a pre-processing or interpretation step because all the data was in the cloud. This would streamline their workflow, eliminating the need to move the data back on premises for that task.
The initial performance tests ran InsightEarth on an NV24 VM on Azure. The storage IO demand was moderate, with rates around 100 MB/s. However, the VM’s memory size proved to be a bottleneck. The amount of data that could be loaded from the memory was limited, and the performance wasn’t as good as the more powerful GPU setup used on premises.
Next, the team ran a similar test using an ND-series VM. This type is specifically designed to offer excellent performance for AI and deep learning workloads, where huge data volumes are used to train models. They chose an ND24-size VM with double the amount of the memory and the newer NVIDIA Tesla P40 GPUs. This time, the results were considerably better than NV24.
From an infrastructure perspective, storage also matters when deploying high-performance applications on Azure. The team implemented SoftNAS, a type of storage that supports both the Windows and Linux VMs used in the overall solution. SoftNAS also suits the lower to mid-range storage IO demands for these simulation and interpretation workloads.
Figure 3. Azure Architecture for InsightEarth
Summary
GPUs and memory-optimized VMs provided the performance that the company needed for both Jason Rockmod and InsightEarth. Better yet, Azure gave them the scale they needed to run multiple realizations in parallel. In addition, they deployed GPUs to both software solutions, giving the CGG engineers a standard front end to work with. They set up access to the Azure resources through an easy-to-use portal based on Citrix Cloud, which also runs on Azure.
CGG’s customer, the oil and gas company, was delighted with the results. Based on the results of the benchmark tests, the oil and gas company decided to move all of their current CGG application workload to Azure. The cloud’s elasticity and Azure’s pay-per-use model were a compelling combination. Not only did the Azure solution perform, it proved to be more cost-effective compared to the limited scalability they could achieve with their computing power on-premises.
Company:
CGG
Microsoft Azure CAT Technical Lead:
Tony Wu
Quelle: Azure

Der Landesdatenschutzbeauftragte aus Hessen warnt vor Microsofts Cloud: Der Zugriff von Dritten könne nicht ausgeschlossen werden, daher dürften Schulen die Software Office 365 nicht einsetzen. Das ist aber nicht der einzige Grund. (Office 365, Microsoft)
Quelle: Golem

Lokale, unabhängige 5G-Netze bieten mehr Angriffs- und Ausfallsicherheit, meint der Breko. Netcom BW redet bereits mit mehreren Mittelständlern über Planung, Realisierung und Betrieb solcher Funknetze. (5G, Breko)
Quelle: Golem

Vier Jahre nach der Veröffentlichung stellt Apple das Macbook mit 12 Zoll ein, der indirekte Nachfolger ist das Macbook Air mit True-Tone-Panel. Das Macbook Pro ohne Touchbar fliegt ebenfalls aus dem Programm. (Macbook, Apple)
Quelle: Golem

Entwickler von Indiegames wehren sich derzeit massiv gegen den Key-Reseller G2A. Nun stellt sich heraus: Das Unternehmen wollte in Branchenmagazinen seine Sicht der Dinge darstellen und dafür bezahlen – aber die Beiträge nicht als Werbung kennzeichnen. (G2A, Indiegames)
Quelle: Golem