IoT × AI : 家電製品の作動状況を機械学習でリアルタイム予測
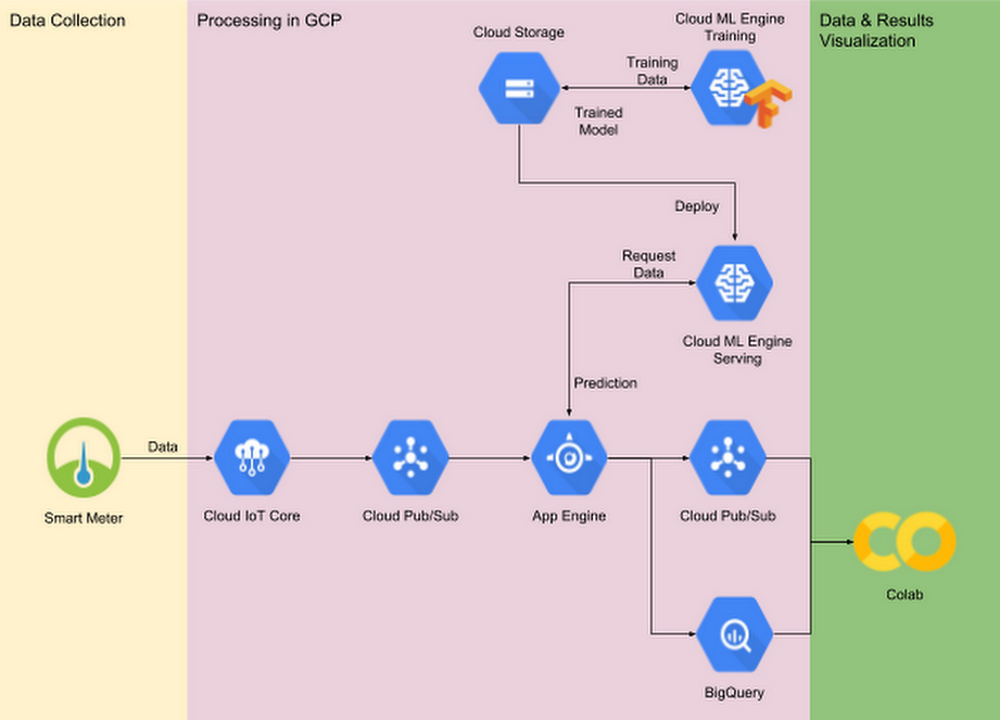
世界中でホーム オートメーションの人気が高まり、それにかかる電力のコストが上昇するにつれて、省エネルギーへの取り組みが多くの消費者にとって大きな関心事となっています。家庭用スマート メーターの登場により、世帯全体の消費電力を測定、記録することも今では可能になりました。さらに、スマート メーターのデータを機械学習モデルで分析すれば、個々の電化製品の挙動を正確に予測できます。それにより、たとえば冷蔵庫のドアが開いたままになっていると推測されるときや、非常識な時間帯にスプリンクラーが突然作動したときに、電力会社が契約者にメッセージを送るといったことも実現できるでしょう。この投稿では、家庭用電化製品(今回のデータセットでは、たとえば電気ケトルや洗濯機など)の作動状況をスマート メーターの測定データから正確に判定する方法とともに、LSTM(long short-term memory)モデルなどの新しい機械学習テクニックについてご紹介します。電化製品の作動状況がアルゴリズムで判定できるようになれば、それに対応したアプリケーションも作れるようになります。たとえば、次のようなものが考えられます。異常状態の検出 : 通常、家に誰もいなければテレビの電源は切れています。予期しない時間帯、あるいは異常な時間帯にテレビがオンになっていると、アプリケーションがユーザーにメッセージを送ります。習慣改善の提案 : 近隣家庭での電化製品の利用パターンを集計した形で示し、それを当該ユーザーの利用パターンと比較または参照できるようにするアプリケーションがあれば、電化製品の使い方を最適化できます。私たちは、Google Cloud Platform(GCP)を使用して、エンドツーエンドのデモ システムを開発しました。データ収集には Cloud IoT Core、機械学習モデルの構築には TensorFlow、モデルのトレーニングには Cloud Machine Learning Engine(Cloud ML Engine)、リアルタイムでのサービス提供と予測には Cloud Pub/Sub、App Engine、Cloud ML Engine を使用しています。本稿を読みながらご覧いただけるように、完全なソース ファイルはこちらの GitHub リポジトリから参照できます。デモ システムの概要IoT デバイスの人気の高まりと機械学習テクノロジーの発展により、新しいビジネス チャンスが生まれています。本稿では、スマート メーターが収集した総電力の測定値を最新の機械学習テクニックで処理し、家庭用電化製品(たとえば電気ケトルや洗濯機)の作動状況(電源オンかオフか)を推測する方法をご紹介します。GCP だけで開発したエンドツーエンドのデモ システムには次のものが含まれています。Cloud IoT Core と Cloud Pub/Sub によるデータの収集と取り込みCloud ML Engine でトレーニングされた機械学習モデルフロントエンドの App Engine と Cloud ML Engine を使用して提供される、同じ機械学習モデルBigQuery と Colab によるデータの可視化と調査図 1. デモ システムのアーキテクチャ下のアニメーションは、Cloud IoT Core を介して Colab に取り込まれた実際の消費電力データのリアルタイム モニタリングを示しています。図 2. リアルタイム モニタリングの様子IoT によって広がる機械学習の可能性データの取り込み機械学習モデルのトレーニングには十分な量の適切なデータが必要です。IoT の場合は、スマート IoT デバイスが収集したデータを遠く離れた中央のサーバーに安全かつ確実に送信するために、さまざまな課題を克服しなければなりません。特に、データのセキュリティや伝送の信頼性、ユース ケースに応じたタイムリー性などを考慮する必要があります。Cloud IoT Core は、世界中に分散した数百万のデバイスに簡単かつセキュアに接続して、それらのデバイスを管理するとともにデータを取り込むフルマネージド サービスです。デバイス マネージャとプロトコル ブリッジの 2 つが主要機能となります。デバイス マネージャは、デバイスを識別して認証し、その識別情報を保持することで、個々のデバイスを大まかな方法で設定、管理できるようにします。また、個々のデバイスの論理構成を保存し、デバイスの遠隔操作を行うことができます。たとえば、大量のスマート メーターのデータ サンプリング率を一斉に変更するようなことも可能です。プロトコル ブリッジは、接続しているすべてのデバイスを対象に自動でロード バランシングを行うエンドポイントを提供するとともに、MQTT や HTTP などの業界標準プロトコルを介したセキュアな接続をネイティブでサポートします。また、デバイスの遠隔測定データを Cloud Pub/Sub にパブリッシュすれば、後でその測定データを下流の分析システムに渡すことができます。私たちのデモ システムでは MQTT ブリッジを採用し、以下に示す MQTT 固有のロジックをコードに組み込んでいます。データの流れデータが Cloud Pub/Sub にパブリッシュされると、Cloud Pub/Sub は「プッシュ エンドポイント」(一般に、データを受け付けるゲートウェイ サービス)にメッセージを送ります。私たちのデモ システムの場合、Cloud Pub/Sub は、App Engine がホスティングするゲートウェイ サービスにデータをプッシュし、そこから Cloud ML Engine がホスティングする機械学習モデルにデータを転送して推論を実行させます。また、それとともに、未加工データと受け取った予測結果を BigQuery に格納し、後で(バッチ)分析できるようにします。私たちのサンプル コードはビジネス固有のさまざまなユース ケースに応用できますが、デモ システムでは未加工データと予測結果の可視化を行っています。コード リポジトリには、次の 2 つのノートブックが含まれています。EnergyDisaggregationDemo_Client.ipynb : このノートブックは、実際のデータセットから消費電力データを読み込むことで複数のスマート メーターをシミュレートし、読み込んだデータをサーバーに送信します。Cloud IoT Core 関連のコードは、すべてこのノートブックに含まれています。EnergyDisaggregationDemo_View.ipynb : このノートブックを使用すれば、指定したスマート メーターからの未加工の消費電力データと、モデルによる予測結果をほぼリアルタイムで表示できます。README ファイルと付属のノートブックで説明されているデプロイ方法に従えば、図 2 の表示を再現できるはずです。一方、ほかの方法でデータ分割パイプラインを作りたい場合は、Cloud Dataflow や Pub/Sub I/O を使用すれば、同様の機能を備えたアプリケーションを構築できます。データ処理と機械学習データセットの概要と調査結果エンドツーエンドのデモ システムを再現可能なものにするため、私たちは UK-DALE(UK Domestic Appliance-Level Electricity、こちら 1 からダウンロード可能)データセットを使用して、総電力の測定値を基に個々の電化製品のオン / オフを予測するモデルをトレーニングしました。UK-DALE は、5 世帯の世帯全体の電力消費と個々の電化製品の消費電力を 6 秒ごとに記録しています。デモ システムでは世帯 2 のデータを使っており、このデータセットには全部で 18 個の電化製品の消費電力が含まれています。データセットの粒度(サンプリング レート 0.166 Hz)を考慮すると、比較的消費電力の少ない電化製品の評価は困難なため、ラップトップやコンピュータ ディスプレイなどの消費電力についてはこのデモに含まれていません。後述のデータ調査結果に基づいて、18 個の電化製品のうち、ランニング マシン、洗濯機、食洗機、電子レンジ、トースター、電気ケトル、炊飯器、電気コンロの 8 個だけを調査対象とすることにしました。下の図 3 は、選択した 8 個の電化製品の消費電力ヒストグラムです。どの電化製品もほとんどの時間は電源オフになっているので、大半の測定値はゼロに近くなります。また図 4 は、選択した電化製品の消費電力の合計(app_sum)と世帯全体の消費電力(gross)との比較を示しています。デモ システムに対する入力は全体の消費電力量(青い曲線)だということに注意してください。これが最も手に入りやすく、家の外でも測定できる消費電力データなのです。図 3. 調査対象の電化製品とその電力需要のヒストグラム図 4. 世帯 2 のデータ サンプル(2013 年 7 月 4 日 : UTC)図 4 に示した世帯 2 のデータは 2013 年の 2 月下旬から 10 月上旬までのものですが、先頭と末尾の近辺には欠損値があるため、デモ システムでは 6 月から 9 月末までのデータを使用しています。表 1 は、選択した電化製品の実際の要約統計をまとめたものです。予想どおり、データは個々の電化製品のオン / オフ状態と個々の電化製品の消費電力規模によって極端にバランスの悪いものになっており、それが予測タスクを難しくする主要因になっています。表 1. 消費電力の要約統計データの前処理UK-DALE は個々の電化製品のオン / オフ状態を記録していないため、前処理において特に重要だったのは、各タイムスタンプにおける個々の電化製品のオン / オフ状態のラベル付けでした。電化製品の電源がほとんどの時間でオフになっており、ほとんどの測定値がゼロに近いことから、消費電力が測定値の標本平均よりも 1 標準偏差高いときは電源がオンであると見なすことにしました。データの前処理のコードはノートブックに含まれており、こちらから処理済みのデータをダウンロードすることもできます。前処理後のデータを CSV 形式にしているので、機械学習モデル トレーニングの入力パイプラインなどでは、TensorFlow の Dataset クラスが、データのロードと変換のための便利なツールとして機能します。たとえば、次のコードの 7 行目から 9 行目では指定された CSV ファイルからデータをロードし、11 行目から 13 行目ではデータを時系列シーケンスに変換しています。データの不均衡という問題については、大きいクラスをダウンサンプリングするか、小さいクラスをアップサンプリングすれば対処できます。私たちのデモでは、確率的ネガティブ ダウンサンプリングを提案しています。一定の確率としきい値に基づき、少なくとも 1 つの電化製品がオンになっているサブシーケンスは残すものの、すべての電化製品がオフになっているサブシーケンスはフィルタリングします。次のコードが示すように、フィルタリング ロジックは tf.data API と簡単に統合できます。最後に、『Data Input Pipeline Performance』ガイドのベスト プラクティスに従い、入力パイプラインからデータがロードされるのを漫然と待って GPU/TPU リソースを無駄にするようなことがないようにしましょう(トレーニング プロセスの高速化のために GPU/TPU が使用されている場合)。GPU/TPU を最大限に活用するには、次のコードに示すように、並列マッピングを使ってデータ変換とプリフェッチを並列化し、前処理とモデル トレーニングのステップが同時に実行されるようにします。機械学習モデル私たちは分類モデルとして LSTM ベースのネットワークを採用しています。RNN(再帰型ニューラル ネットワーク)と LSTM の基礎については『Understanding LSTM Networks』をご覧ください。図 5 は、私たちのモデル設計を図示したものです。長さ n の入力シーケンスが多階層の LSTM ネットワークに送られ、m 個のすべてのデバイスについて予測が行われます。LSTM セルへの入力のためにドロップアウト層を追加し、シーケンス全体の出力を完全接続層に送るようにしました。私たちはこのモデルを TensorFlow の Estimator として実装しています。図 5. LSTM ベース モデルのアーキテクチャ上記アーキテクチャの実装方法としては、TensorFlow ネイティブ API(tf.layers と tf.nn)と Keras API(tf.keras)の 2 つがあります。Keras は、TensorFlow のネイティブ API と比べて高レベルの API であり、使いやすさ、モジュール性、拡張性の 3 つの長所を兼ね備えたディープ ラーニング モデルのトレーニングと提供を可能にします。一方、tf.keras は TensorFlow による Keras API 仕様の実装です。次のコード例では、LSTM ベースの分類モデルを両方の方法で実装しています。比較してみてください。TensorFlow のネイティブ API を使用したモデルの実装 :Keras API を使用したモデルの実装 :トレーニングとハイパーパラメータ調整Cloud ML Engine は、トレーニングとハイパーパラメータ調整の両方をサポートしています。図 6 は、さまざまな組み合わせのハイパーパラメータを使って複数回試行したときの、電化製品全体の平均精度、再現率、F 値を示しています。ハイパーパラメータの調整により、モデルのパフォーマンスが大幅に向上しています。図 6. ハイパーパラメータ調整と学習曲線表 2 は、ハイパーパラメータ調整で最高のスコアを叩き出した 2 つの実験を選び、そのパフォーマンスをまとめたものです。表 2. スコアの高い 2 つの実験のハイパーパラメータ表 3 は、個々の電化製品における予測の精度と再現率を示しています。「データセットの概要と調査結果」の項で述べたように、電気コンロとランニング マシンについては、ピーク時の消費電力がほかのデバイスよりもかなり低かったため、予測が難しいことがわかります。表 3. 個々の電化製品における予測の精度と再現率まとめ以上、スマート メーターの測定データのみを基に電化製品の作動状況を正確に判断する方法を、機械学習を取り入れたエンドツーエンドのデモ システムを用いて解説しました。システム全体をサポートするため、Cloud IoT Core、Cloud Pub/Sub、Cloud ML Engine、App Engine、BigQuery などを組み合わせており、これらの GCP プロダクトはデータ収集 / 取り込み、機械学習モデルのトレーニング、リアルタイム予測など、デモの実装に必要な特定の問題を解決します。このシステムに興味のある方は、コードとデータの両方を入手して、ぜひお試しください。より能力の高い IoT デバイスと、急速に発展を遂げている機械学習が交わる領域では、もっと面白いアプリケーションがこれからもどんどん開発されていくと、私たちは楽観的に考えています。Google Cloud は、IoT のインフラストラクチャと機械学習トレーニングの両方を提供することで、新しくて能力の高いスマート IoT の可能性を追求し、現実のものにしていきます。* 1. Jack Kelly and William Knottenbelt. The UK-DALE dataset, domestic appliance-level electricity demand and whole-house demand from five UK homes. Scientific Data 2, Article number:150007, 2015, DOI:10.1038/sdata.2015.7.- By Yujin Tang, ML Strategic Cloud Engineer, Kunpei Sakai, Cloud DevOps and Infrastructure Engineer, Shixin Luo, Machine Learning Engineer and Yiliang Zhao, Machine Learning Engineer
Quelle: Google Cloud Platform




