Android: Huawei bekommt 90 Tage Aufschub beim US-Boykott
Die US-Technologiebranche hat einen Aufschub des Boykotts gegen Huawei durchgesetzt. Huawei-Gründer Ren bedankt sich bei den US-Unternehmen. (Huawei, Handy)
Quelle: Golem

Die US-Technologiebranche hat einen Aufschub des Boykotts gegen Huawei durchgesetzt. Huawei-Gründer Ren bedankt sich bei den US-Unternehmen. (Huawei, Handy)
Quelle: Golem

Dell hat seine Einstiegs-Businessnotebooks aktualisiert. Als Neuerung finden sich Intels jeweils aktuelle Prozessoren der 8. und 9. Generation in den Geräten. Teilweise sind in der Serie sogar Hexa-Core-Prozessoren verbaut. (Business-Notebooks, Intel)
Quelle: Golem

Eine hohe Auflösung, gutes Licht und leistungsfähige Sensoren zählen zu den Kernelementen, um Nutzern ein tolles Virtual-Reality-Erlebnis zu bieten. Mit seinen LEDs und Infrarot-Sensoren in VR-/AR-Brillen sorgt Osram genau dafür. Das Entwicklerteam wird immer größer – und braucht noch Verstärkung. (VR, Technologie)
Quelle: Golem
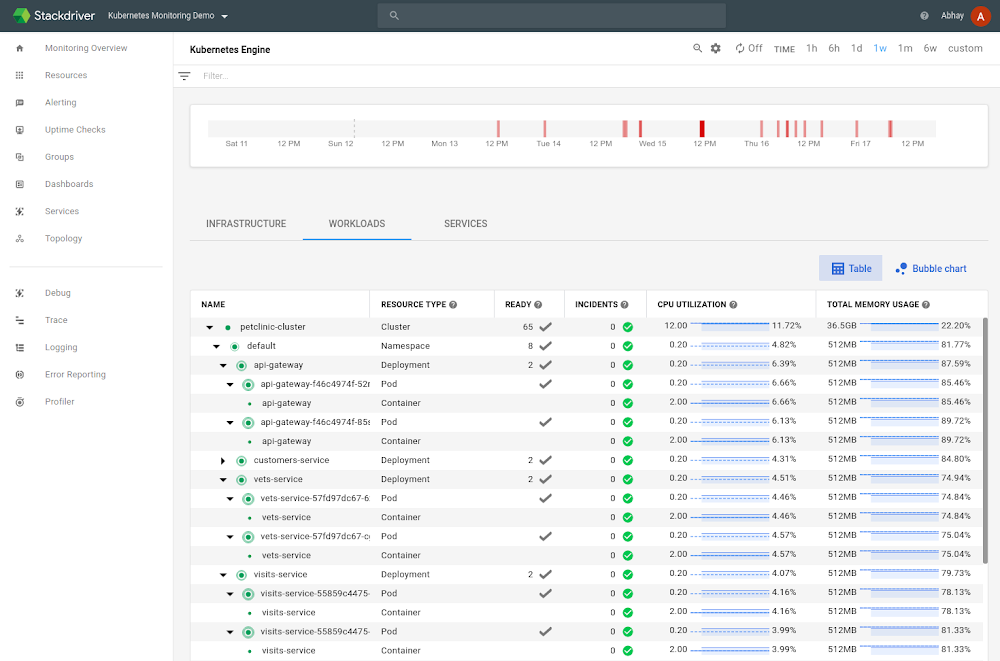
Since its launch in 2015, Google Kubernetes Engine (GKE) continues to set the standard for the industry on what it means to provide a managed Kubernetes service that puts security, reliability, and ease of use first. This innovation is driven by feedback from all Kubernetes users and GKE customers. Thank you for trusting us to provide the platform that powers your business transformation.Today, on the first day of KubeCon EU, we want to update you on what’s new in GKE.Your Kubernetes your way with GKEMove quickly and reliably with GKE release channelsAs a Google Cloud customer, you have a wide range of requirements for how to use your clusters and when to upgrade them. GKE has always abstracted away the complexity of managing Kubernetes releases by automating the upgrade and delivery of new versions to your clusters. When you create a cluster on GKE, your cluster is created with the default certified version in the GKE fleet, and you can leverage the auto-upgrade capability to keep your clusters up to date with bug fixes and security patches.Starting this month in alpha, GKE will offer release channels, allowing you to upgrade your clusters in a way that fits your business. We’ll offer three channels; Rapid, Regular, and Stable, each with different version maturity and stability, so you can subscribe your cluster to an update stream that matches your risk tolerance and business requirements.We’re excited to introduce the first of the release channels, the Rapid channel. You can subscribe your clusters to the Rapid channel starting now, and get early access to the latest Kubernetes version as it matures to Regular, and finally to the Stable channel.Try out Windows Server Containers in Rapid ChannelWe heard you—being able to easily deploy Windows containers is critical for enterprises looking to modernize existing applications and move them towards cloud-native technology. In Kubernetes 1.14, the upstream open-source community announced support for Windows nodes, and we’re pleased to offer Windows Server Containers in Kubernetes 1.14 on GKE. You’ll be able to experiment with Windows Server Containers and modernize your existing Windows applications from the new Rapid channel in June. Be in the know with Stackdriver Kubernetes Engine MonitoringToday, we’re excited to announce general availability of Stackdriver Kubernetes Engine Monitoring, a tool that gives you GKE observability (metrics, logs, events, and metadata) all in one place, to help provide faster time-to-resolution for issues, no matter the scale.Stackdriver Kubernetes Engine Monitoring observability data (metrics, logs and traces) and events for infrastructure, workloads and servicesKubernetes Engine Monitoring gives you a comprehensive view into your Kubernetes environment, including infrastructure, application and service data with speed and reliability. It comes pre-integrated with GKE, so you can use it to improve the reliability of the services running there from the get-go.”Stackdriver Kubernetes Engine Monitoring gives us complete visibility into our GKE environment, is easy to use and fosters a meaningful conversation between SREs and Engineering on the reliability of our applications. We now have a full view across all of our clusters and can dig into further details as needed–allowing us to diagnose issues faster and keep our applications available to users.” – Pardeep Sandhu, Site Reliability Engineer, SchlumbergerDevelop faster with Kubernetes apps on GKEIt’s easy to deploy integrated Kubernetes applications to GKE directly from the Google Cloud Platform (GCP) Marketplace, bringing an ecosystem of open-source and commercial applications to you in the cloud and on-prem in a simple, integrated way. Kubernetes apps also support organizations in their application modernization journey, by helping them deploy containerized applications on-prem before moving them to the cloud. Get started today, and encourage your ISV partners to offer their solutions as Kubernetes apps from GCP Marketplace.Use GKE Advanced for enhanced reliability, simplicity and scaleFinally, we recently introduced GKE Advanced with features and tooling to help you operate in fast-moving environments to simplify the management of workloads and clusters, and scale hands-free. You still benefit from Kubernetes’ portability and third-party ecosystem, but with an enhanced, and evolving, feature set.At Google Cloud our users are the inspiration for everything we do. Seeing how you use GKE to transform your business inspires us.Transforming businesses with GKEThe momentum we see across a variety of industries and customer segments is a testament to the value of Kubernetes and GKE. On the occasion of the five year anniversary of Kubernetes, we want to thank and celebrate some of our customers, who are transforming their businesses through GKE.Leading the way to cloud-native appsWhether you want to modernize your environment, or build cloud-native applications from scratch, consider choosing GKE as your container management and orchestration foundation.To celebrate Kubernetes’ 5th birthday, we’re giving away a free month of learning through our new Coursera course, Architecting with GKE†. And if you’re at KubeCon, be sure to check out our talks, and stop by the booth to say hi!† Offer valid until 30 September 2019, while supplies last.
Quelle: Google Cloud Platform

Der Berliner Elektroroller Unu wird in der neuen Generation deutlich moderner aussehen und soll ab August für rund 2.800 Euro erhältlich sein. (Elektromobilität, Technologie)
Quelle: Golem

Google hat die Datenbrille Glass Enterprise Edition 2 vorgestellt, die Unternehmen helfen soll, Augmented-Reality-Lösungen für Mitarbeiter zu entwickeln. (Project Glass, Display)
Quelle: Golem

Microsoft hat Vorschauversionen seines Browsers Edge für MacOS veröffentlicht. Der Browser auf Chromium-Basis enthält Anpassungen speziell für die Mac-Plattform. (Edge, Microsoft)
Quelle: Golem

Kubernetes is a powerful orchestration technology for deploying, scaling and managing distributed applications and it has taken the industry by storm over the past few years. However, due to its inherent complexity, relatively few enterprises have been able to realize the full value of Kubernetes; with 96% of enterprise IT organizations unable to manage Kubernetes on their own. At Docker, we recognize that much of Kubernetes’ perceived complexity stems from a lack of intuitive security and manageability configurations that most enterprises expect and require for production-grade software.
Docker Kubernetes Service (DKS) is a Certified Kubernetes distribution that is included with Docker Enterprise 3.0 and is designed to solve this fundamental challenge. It’s the only offering that integrates Kubernetes from the developer desktop to production servers, with ‘sensible secure defaults’ out-of-the-box. Simply put, DKS makes Kubernetes easy to use and more secure for the entire organization. Here are three things that DKS does to simplify (and accelerate) Kubernetes adoption for the enterprise:
Consistent, seamless Kubernetes experience for developers and operators
DKS is the only Kubernetes offering that provides consistency across the full development lifecycle from local desktops to servers. Through the use of Version Packs, developers’ Kubernetes environments running in Docker Desktop Enterprise stay in sync with production environments for a complete, seamless Kubernetes experience. With a quarterly release cycle for Kubernetes and new APIs getting added every release, different environments may end up running different versions of Docker and Kubernetes. Developers can switch between version packs with a single click to stay aligned to different resulting environments.
Streamlined Kubernetes lifecyle management ( Day 1 and Day 2 operations)
New cluster management tools enable operations teams to easily deploy, scale, backup and restore and upgrade a certified Kubernetes environment using a set of simple CLI commands. This delivers an automated way to install and configure Kubernetes applications across hybrid and multi-cloud deployment, including AWS, Azure, or VMware.
Enhanced security with ‘sensible defaults’
DKS comes hardened with “sensible defaults” that enterprises expect and require for production-level deployments. These include out-of-the-box configurations for security, encryption, access control, and lifecycle management — all without having to become a Kubernetes expert. DKS also allows organizations to integrate their existing LDAP and SAML-based authentication solutions with Kubernetes RBAC for simple multi-tenancy.
Take the next step to Kubernetes success
Try it for yourself: Sign up for the Docker Enterprise 3.0 public beta
Watch the webinar: How Docker Simplifies Kubernetes for the Masses
Introducing #Docker #Kubernetes Service (DKS). Discover the 3 ways DKS simplifies and accelerates Kubernetes adoption for the enterprise:Click To Tweet
The post Introducing Docker Kubernetes Service appeared first on Docker Blog.
Quelle: https://blog.docker.com/feed/
It’s never going to be possible to completely disconnect software from hardware. Indeed, hardware development is having a bit of a rebirth as young developers rediscover things like the 6502, homebrew computing, and 8-bit assembly languages. If this keeps going, in 20 years developers will reminisce fondly and build hobby projects in early IoT […]
The post Software Defined Storage: The Next Killer App for Cloud appeared first on Red Hat OpenShift Blog.
Quelle: OpenShift

The post Intro to NoSQL database apps, Part 1: Everything you ever wanted to know but were afraid to ask appeared first on Mirantis | Pure Play Open Cloud.
When a company is small — say, just a few people, not
much revenue — it’s natural to keep track of everything in simple spreadsheets or
user-friendly databases such as Microsoft Access. As you grow, you realize that
your needs go beyond what Access was designed for, and you start thinking about large
commercial databases such as SQL Server, or Oracle, or one of the open source databases
such as MySQL.
But eventually, when you get big enough, you discover
that even those databases aren’t beefy enough to handle the job. Maybe it’s the
type of data, or the volume of data, or your new cloud-based architecture, but you
realize it’s time.
You need to start learning about NoSQL.
Can’t wait to jump right in? Join us for me for a crash course on NoSQL and Cassandra.
NoSQL originally meant that literally: “No Structured
Query Language”. These days, though, it actually means “Not Only Structured Query
Language”, because a NoSQL database tends to have much broader applications and
flexibility than RDBMS.
There are more than 225 different NoSQL databases,
including the more well known open source projects such as Cassandra, Redis, and Etcd,
cloud-based versions such as Amazon Web Services DynamoDB, and proprietary products
such as Oracle NoSQL. They’re all different, but they share various traits.
In this article, we’ll discuss what makes them different
from traditional relational databases and why you might want to take advantage of
them.
What is NoSQL and how is it
different from RDBMS
The most obvious way that a NoSQL database differs from
traditional relational databases is in the structure of the data. An RDBMS
consists of tables of data structured according to a schema:
These tables are usually “normalized”, meaning that
specific pieces of data appear only once, and they’re linked together by keys. So
if, for example, you wanted to see all of Alice’s skills, you could do it with an SQL
query:
SELECT EMPLOYEE.name, SKILLS.skill_name from SKILLS, EMPLOYEES where SKILLS.emp_id = EMPLOYEES.id and EMPLOYEES.name = ‘Alice’
This kind of query brings the data from both tables
together using a “join”.
Non-relational, or NoSQL databases, are different, in
that there is no defined schema. Data is added and defined as it comes in, much as
relationships are created and modified on the fly in an object oriented system, rather
than being pre-defined in a dictionary. The structure of the data doesn’t matter.
Well, almost.
In fact, there are four different types of NoSQL
databases:
Key-value stores: Key-value
stores, such as Redis and etcd, do exactly what it says on the tin; they store a
value associated with a key. This might be something as simple as:
NewLymeOH = 44047
StatenIslandNY = 10314
BostonMA = 02134
Or it might be something more complicated, with
parameterized keys such as
Employee:1:firstname = Nick
Employee:1:lastname = Chase
Employee:2:firstname = Buddy
Employee:2:lastname = Rich
Wide Column: Wide Column databases,
such as Cassandra, are like a cross between a RDBMS and a key-value store, in that
they do have tables, and the tables consist of rows, but each row can have
different columns:
Sometimes these database will
support a query language similar to the SQL used with relational databases, but not
always.
Document: Document databases, such as MongoDB, store each entity as a single document
within the database. Like Wide Column databases, each document can have a completely
different structure, which is often represented as JSON.
Graph: Graph databases, such as Neo4J, concentrate not so much on the elements of
the data itself but on the relationships between those elements. They’re built
on the concept of nodes or entities, analogous to a row in a table, properties, or
information about each node, and edges, or relationships between nodes.
(Ironically, a Graph database is usually persisted using a Key-Value store, but
some actually use an RDBMS as their persistence layer.)
But structure isn’t the only difference between SQL and
NoSQL databases. One of the most important differences has to do with consistency.
RDBMSs are defined by the acronym ACID, an initialism for:
Atomicity: Either all operations in a transaction succeed or all of them
fail.
Consistency: Consistency means that the database will always be in a working state,
with all constraints and triggers satisfied.
Isolation: Another defining property of transactions is that once one begins, none of
the changes are visible from outside of that transaction until the transaction is
committed.
Durability: Once
a transaction is committed, the data is saved in such a way that it will not be lost,
even if there’s a crash or power failure.
NoSQL databases, on the other hand, are defined by the
acronym BASE (because developers love a good pun), which stands for:
Basically Available: NoSQL databases are architected to be highly available; with no single
point of failure, even if a node goes down, the database will still be
operational.
Soft state: The
state of a NoSQL database can change without affecting the availability of
the
Eventual consistency: A NoSQL database can accept a transaction even if it takes time —
usually on the order of milliseconds — for all nodes to reach a consistent
state.
There’s no need to change over to a NoSQL database all
at once; the two types can coexist quite nicely using a paradigm called polyglot
persistence. But why would you even want to consider it in the first place?
Why you’d want to use a NoSQL database
There are lots of reasons that you might find yourself
thinking about using one for the various NoSQL databases, including scalability and
cost, performance, and flexibility.
In a high impact environment, data streams and
feeds can operate too quickly to allow for traditional transaction execution, which
requires a commit and flush to the database in order to make them permanent.
NoSQL databases, on the other hand, are designed to hold entries in memory and
persistent them when storage has had time to catch up, enabling you to be more “run and
gun” than an RDBMS.
NoSQL databases are designed so that they can be scaled
horizontally, which means that you can start with a single small server and scale up —
or down — as you need to, for a true Cloud native architecture. For example, let’s say
you know from the beginning that you want high availability, so you start with three
small servers to satisfy your requirement for redundancy.
These databases enable the system to continue
functioning should one or more nodes go down — unlike RDBMS, where the failure of a
single drive or server can bring down the entire application. This means that if
usage begins to outstrip the capacity of your three servers, you can add more, and in
general they will be auto-discovered by the cluster and the data populated to the new
nodes.
On the other hand, when usage goes down, you can shut
down those additional nodes, and because the failure or disappearance of an individual
node doesn’t affect the performance of the system, your application keeps on
going.
Contrast this with a traditional RDBMS, which (usually)
can only scale upwards, meaning that to get better performance, you need a larger
machine. As a result, you spend the vast majority of your time in one of two
states: either your machine is too small for the traffic you’re getting and your users
are getting a poor experience, or your machine is too big for the traffic you’re
getting and you’ve got spare capacity sitting around, wasting money.
As far as performance is concerned, NoSQL databases are
designed for very large datasets, and as a result, usually perform faster. In
addition, many, such as Redis, are in-memory databases, which improves performance even
more.
Finally, there’s the NoSQL advantage itself. The ability
to have a “schemaless” system provides a number of benefits, including:
In systems with huge amounts of data, getting locked
into a particular schema can cause enormous problems later on. Sure, you can
always change the schema later, but for large systems this can be extremely dangerous
and time consuming before you even consider changes to the application based on that
database.
NoSQL databases are a good choice when speed
and simplicity are more important than the ability to do transactions or immediate
consistency.
You can store unstructured or differently
structured data, because you don’t have to define a schema for every piece of data
that goes on. If you have large amounts of unstructured data, such as documents, this
means you can store it without alteration, leaving the original data
intact.
You can create a hierarchy of data that is
self-referential, or described by the data itself, enabling complicated structures
without complicated planning.
It’s important to remember, however, that not all NoSQL
databases are created equal.
Choosing the right NoSQL database
There is one significant drawback to NoSQL databases,
however. While RDBMS’s are generally the same — SQL has been fairly standardized for
decades, and it’s usually a matter of simply changing drivers to change the database
behind your application — NoSQL databases are all different, and it’s important to
know what you want before committing to one over another.
There are four major differences between NoSQL
databases:
Data model: As
we discussed earlier, there are four different kinds of NoSQL databases. If you’re
primarily dealing with large documents, you’ll be better off with a Document-oriented
database such as MongoDB, Couchbase, or CouchDB. If you have simple key-value pairs,
obviously a key-value store such as Redis, etcd, or MemcacheDB is your best bet. If
your data is very SQL-like, a wide-column database such as Cassandra or HBase should
be your focus. Finally, if you are very interested in the relationships between
various pieces of data, you’ll want a graph database such as Neo4J.
Architecture: While NoSQL databases are generally architected for scalability, they’re
not all implemented in the same way. Some, like MongoDB, use the Master/Slave model
where a single node acts as the database of record and other nodes assist. Others,
like Cassandra or etcd, are masterless systems, in which every node is exactly the
same. Depending on how you intend to operate your system, this may matter to
you.
Data distribution
model: How is the data synchronized? With some
NoSQL databases, all nodes are read-write, taking data and replicating it out to all
other nodes. This method is an advantage when the application frequently writes to
the database, as latency can be reduced by sending write operations to the closest
node. Others designate a single node to accept write operations, and that node
replicates the data to others to speed up reads. This can be beneficial in situations
in which the application send makes changes to the database, but when writes are
made, you want to make sure they’re captured quickly.
API: If you’re
coming from the RDBMS world, one thing that might surprise you is the lack of
standardization in the ways in which you interact with the data in each database.
Some databases require the use of a specific API, where others make a SQL-like
query language available, such as Cassandra’s CQL.
In addition, different types of NoSQL databases have
different strengths and weaknesses. For example, key-value stores have high
performance and flexibility, but support only low complexity in the data. A graph
database can handle high complexity but has only moderate performance.
If you’re thinking that this leads to the functional
equivalent of “vendor lockin”, you’re right. So it is always a good idea to
thoroughly investigate before committing, even if that means doing a small proof of
concept first.
Next week, we’ll be starting a project demonstrating the
use of these NoSQL databases, building, and eventually containerizing, an application
built on Cassandra.The post Intro to NoSQL database apps, Part 1: Everything you ever wanted to know but were afraid to ask appeared first on Mirantis | Pure Play Open Cloud.
Quelle: Mirantis