Identity and authentication, the Google Cloud way
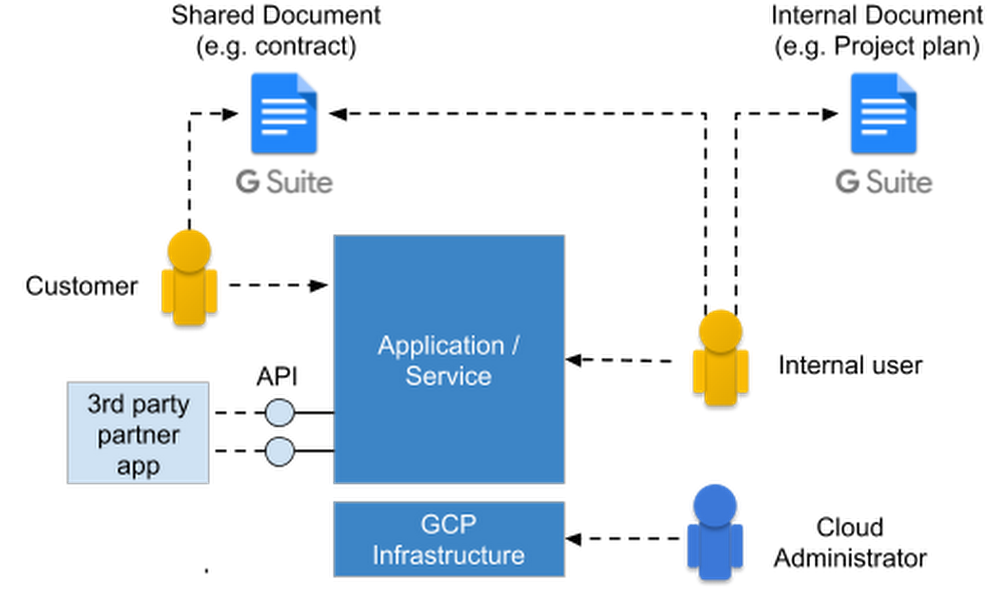
Users expect simple and secure sign-up, sign-in, and self-service experiences from all their favorite devices. As a security professional, you could build identity and access management functionality for your organization, but that’s hard and expensive: you’d need to build and maintain an identity platform that stays up-to-date with constantly evolving authentication requirements, keeps user accounts secure in the face of increasing threats, and scale the system reliably when the demand for the service grows. Or, you can have Google do it for you.Whatever your identity needs, Google Cloud has a complete set of tools that you can integrate to create a modern, sophisticated identity platform. This post describes Google Cloud’s authentication and identity management offerings to help you determine what solution best fits your needs.Authentication use casesSetting up authentication can be tricky. You’ve got a variety of use cases—everything from workplace productivity suites, cloud-based resources and APIs. Some authentication is done on behalf of a piece of software, e.g., when one service invokes another service’s API. Most other authentication is based on user populations, including customers, partners, and employees. Some of these populations collaborate through shared resources, e.g., a G Suite document that’s shared between an employee and a customer. The following diagram shows a potential (simplified) scenario:In all but the most trivial cases, there are lots of different types of users that need to be authenticated:Internal users accessing workplace or office productivity solutionsInternal users accessing third-party appsInternal users accessing internally built and hosted appsInternal users accessing and administering cloud resources directlyUsers making a proxy call to an API (tracking who made call, and on behalf of which end user the request was made)External users accessing applicationsIf you deploy your own applications, those too need to be authenticated. Examples include:API calls from internal servicesAPI calls from third partiesDevices authenticating to cloud-hosted servicesWith this variety of users, use cases and applications, it can be confusing to know which identity and authentication method to use, in what circumstances. GCP identity management and authentication methodsGoogle Cloud offers a number of authentication and identity management solutions that support many common use cases:Cloud Identity- Cloud Identity is an Identity as a Service (IDaaS) and enterprise mobility management (EMM) product that offers identity services and endpoint administration for G Suite or as a stand-alone product. As an administrator, you can use Cloud Identity to manage your users, apps, and devices from the central Google Admin console. Click here to learn more about Cloud Identity features.Secure LDAP – This feature of Cloud Identity and G Suite lets employees access LDAP-based apps and infrastructure using their Cloud Identity (or G Suite) credentials. With Secure LDAP, IT teams can use a single cloud-based identity and access management solution (Cloud Identity) to enable employees access to both SaaS and traditional apps/infrastructure.Cloud Identity for Customers and Partners (CICP) – CICP is a customer identity and access management (CIAM) platform that lets you add Google-grade identity management functionality to your apps. Built on top of Firebase Authentication, CICP provides an end-to-end authentication system for third-party users to access your apps and services, including mobile/web apps, games, and APIs, to name a few. If you’re building a service on Google Cloud (or anywhere else for that matter), and need secure, yet easy-to-use authentication capabilities, check out CICP.In addition to managing/federating end user credentials, CICP also provides a token brokerage service.API Proxies (Apigee Edge / Cloud Endpoints) – Google Cloud API proxies are an abstraction layer that “fronts” for your backend service APIs, providing not only a proxy but also management and security features such as authentication and validation. That way, you know what is calling your APIs, with short-lived tokens and logging helping to prevent their unauthorized use. Google Cloud provides two options: Cloud Endpoints are a great choice across GCP while Apigee Edge works cross-platform and includes enterprise features like rate limiting, quotas, analytics, and more.Cloud Identity-Aware Proxy (IAP) – Cloud IAP works by verifying user identity and the context of a request to access a cloud-based application hosted on GCP. It determines if a user should be allowed to access the application. Cloud IAP is a building block toward BeyondCorp, an enterprise security model that enables every employee to work from untrusted networks without having to use a VPN.When Cloud IAP grants a user access to an application or resource, they’re subject to the fine-grained access controls implemented by the product in use without requiring a VPN. When a user tries to access a Cloud IAP-secured resource, Cloud IAP performs authentication and authorization checks. Context-aware access allows organizations to define and enforce granular access to GCP workloads and G Suite based on a user’s identity and the context (location, device, etc.) of their request. Context-aware access verifies that:The user is trusted: they have a password, authentication strength (e.g. 2SV, Security Keys), and Cloud IAP’s machine-learning detects no abnormal user behaviour.The device is trusted with Endpoint Verification.The location is trusted (IP address).Authenticating against GCP – Authenticating directly to GCP requires a recognized identity such as a Google account, a service account, a Google Group or a Cloud Identity or G Suite identity (including identities that have been synced with Cloud Identity).Mapping your use case to a GCP authentication methodNote in all cases we assume that GCP is the identity providerThe following matrix helps you determine what identity/authentication solution is appropriate for your use case:Internal user authentication requirementsApplication access authentication requirementsAuthentication decision treeIf text and tables aren’t your thing, here’s a visual way to help you decide how to pick the appropriate identity and authentication method for your use case.As you can see, Google Cloud provides a wealth of authentication options for seemingly any kind of user or application. To learn more about identity and authentication of Google Cloud, check out the resources in this blog post. Then, there’s also the Security & Identity Fundamentals quest1, a hands-on training course. And be sure to let us know about any use cases that aren’t covered here!1. Use code 1j-security-983 and get one month of Qwiklabs access to complete the quest free of charge (redeem by Jan 31, 2019)
Quelle: Google Cloud Platform








