Is This An Ad? The Treasury Secretary's Wife's Instagram
This is Louise Linton, actress, lawyer, and the wife of U.S. treasury secretary Steven Mnuchin.

Linton is a 36-year-old from Scotland who has appeared in stuff like CSI:NY and Cabin Fever: Reboot. She married Mnuchin, 54, this summer.
Pool / AFP
And on Monday, she posted this photo on Instagram, complete with brand #tags that are typical of #spon.

deleted Instagram
And THEN she GOT INTO IT with a commenter named Jenni who called her out for (apparently) using taxpayer money for her #daytrip.
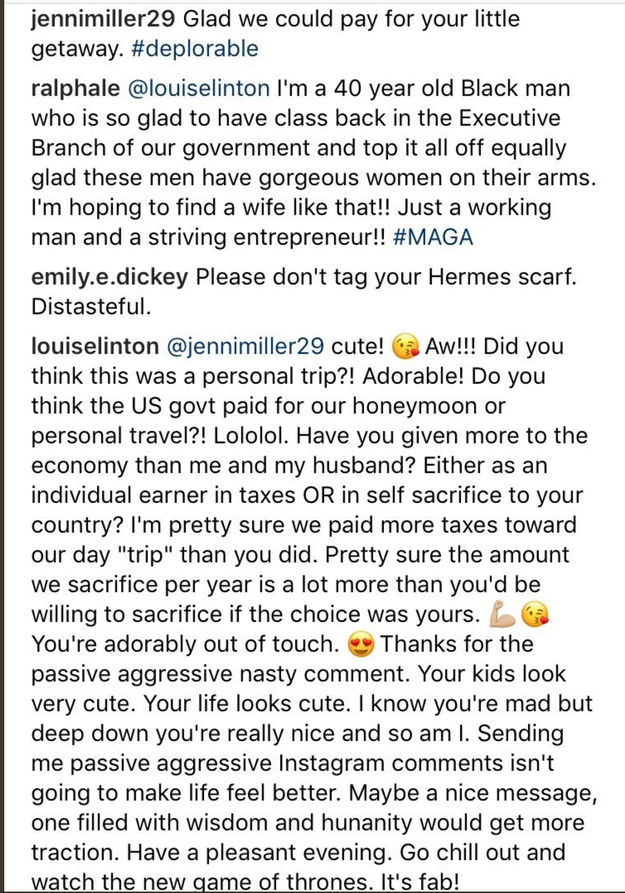
deleted Instagram
Sure, you could use this for a deep discussion of class war, social media, and the Trump administration.
But what I really want to know is: Was this an ad?
I mean, who tags brands in a post that's not #spon, right? Although it's not typical for the family members of high level government officials to do fashion ads, Linton isn't a typical politician's spouse – for example, she recently acted in a movie staring Charlie Sheen.
Plus, she's no stranger to fashion advertising. According to her personal website, she's the “inaugural brand ambassador” for a line of handbags called the “Linton Collection” from a Scottish brand called Dunmore. (At publishing time, Dunmore has not replied to request for clarification from BuzzFeed News on if she's still currently a brand ambassador, and if promoting these other brands on her Instagram would be a conflict.)
I'm curious: what do we assume is going on in this photo (don't cheat and scroll down).
So was this an #ad #spon #partner?

According to the New York Times, an administration spokesperson said that she was not compensated by those brands she tagged. But if there's one thing I know about the Instagram #spon game, sometimes people and brands have different definitions of what “compensated” means, especially when brands engage in the common practice of gifting thousands of dollars' worth of merchandise or travel to a celebrity in the hopes that they'll post about it.
So BuzzFeed News reached out to the luxury brands to ask if there was any “gifted” merchandise or compensation. Both Tom Ford and Valentino confirmed that there was nothing of the sort — no loaned items, freebies or anything. We will update as soon as we hear from Hermés and Roland Mouret, but I think it's safe to call it at this point: it's not an ad.
Louise Linton, you beautiful sassy creature, keep living your wild life and continue to pay for all your own stuff.
Quelle: <a href="Is This An Ad? The Treasury Secretary's Wife's Instagram“>BuzzFeed







