
Google
There are already a dozen different ways you can watch TV without cable – and now, Google is offering cord cutters yet another option, called YouTube TV, that offers a mix of live TV, cloud DVR storage, *and* on-demand content to set itself apart from established competition like Netflix and Amazon. The new service, which costs $35 a month, will be offered on the web, Android, iPhone, iPad, Google Chromecast, and Chromecast-enabled TVs.
US households pay $103.10 per month on average for cable, so it’s no wonder that services streaming shows, movies, and sports over the Internet are increasingly popular. Most streaming sites charge between $9 and $25 a month to access content on-demand, on multiple devices, wherever there’s a strong Internet connection. Another plus? Not having to deal with frustrating customer service representatives trying to force you not to cancel your subscription.
YouTube TV is a way for Google to compete with the likes Hulu and Netflix by offering its massive user base premium content, rather than just (mostly amateur) user-uploaded content. The homepage of the YouTube TV app features popular YouTube web series from independent creators like Lizzie Bennet, alongside shows from ABC and Showtime.
So, is YouTube TV worth it? I had a few days to play with the Android version of the new app, and think it’s a compelling option for those who are really into TV, especially live TV. But the on-demand content is fairly limited, so YouTube TV is pricey if you already subscribe a standalone sports package or a TV-focused service, like Hulu Plus.
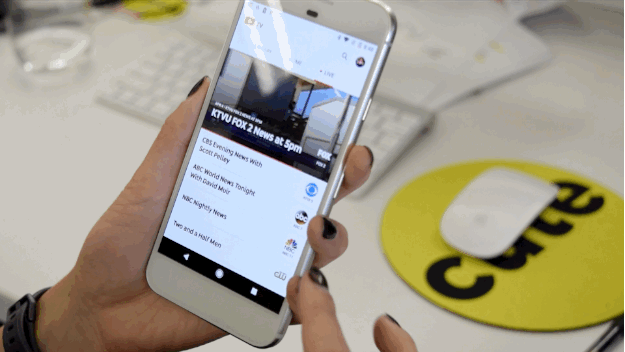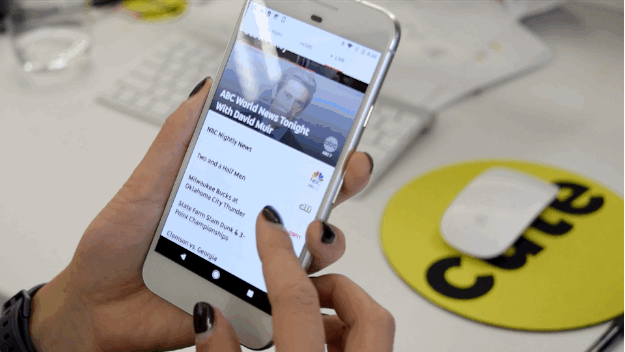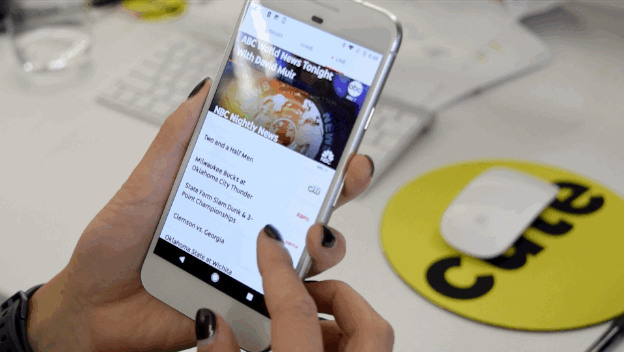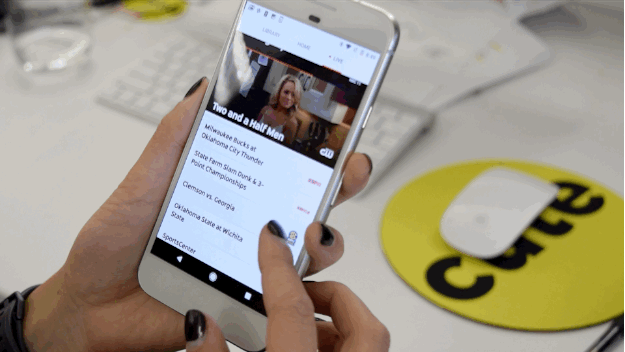
Nicole Nguyen / BuzzFeed News
Here’s what you get for $35 per month.
YouTube TV is essentially three things: a live TV streaming service, a cloud-based DVR with unlimited storage, and a link to YouTube content related to those TV shows.
A subscription to YouTube TV gets you live streams from Disney (including Disney Channel, ESPN, and ABC), NBCUniversal (including MSNBC, Bravo, E!, and Telemundo), CBS (including The CW and CBS Sports Network), Fox (including Fox News and Nat Geo), AMC Networks (including AMC and BBC America) and The Weather Channel.
It's a bit more limited than what Sling Blue, plus some extras, and Playstation Vue offer though, depending on the package, those are a bit more expensive than YouTube TV. You’ll notice that Viacom channels like Comedy Central and Turner Broadcasting programming from CNN and TBS are missing.
According to Google, YouTube TV subscribers will soon be able to purchase premium add-ons like Showtime ($11/month), Fox Soccer Plus ($15/month), Shudder, and Sundance Now in addition to the base tier.
The full list of YouTube TV&039;s channels:
Disney: ABC, ESPN, ESPN2, ESPN3, ESPNU, ESPNews, SEC Network, Disney Channel, Disney Junior, Disney XD, Freeform
NBCUniversal: NBC, Telemundo, Bravo, Chiller, CNBC, E&033;, Golf Channel, MSNBC, Universo, NBCSN, Oxygen, Sprout, SyFy, Universal HD, USA, Comcast Regional Sports Networks, NECN (New England Cable News)
CBS: CBS, The CW, CBS Sports NetworkFox: FOX, FS1 (Fox Sports 1), FS2 (Fox Sports 2), BTN (Big Ten Network), FX, FXX, FXM, Nat Geo, Nat Geo Wild, Fox News, Fox Business, Fox Regional Sports NetworksAMC Networks: AMC, BBC America, BBC World News, WE tv, IFC, Sundance TV
The Weather Channel: Local Now
You’ll also have access to YouTube Red, which is premium ad-free content made by YouTube stars and would cost you $10 per month without a YouTube TV subscription.
It’s basically an Internet-friendly, mobile-friendly live TV guide.
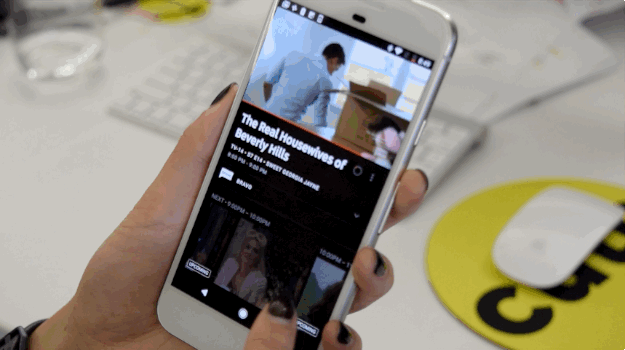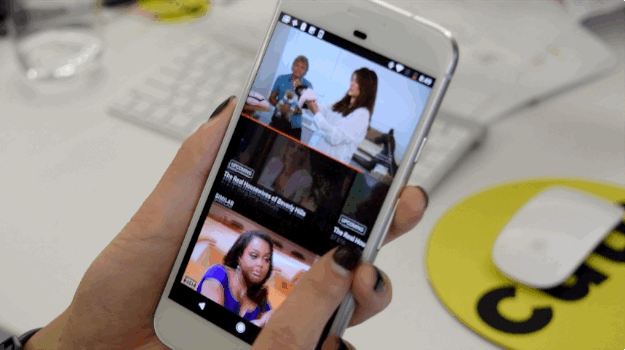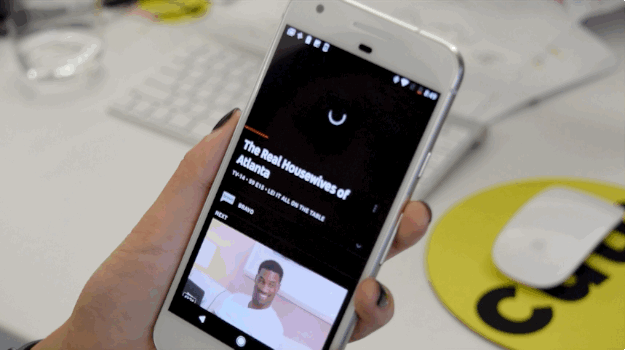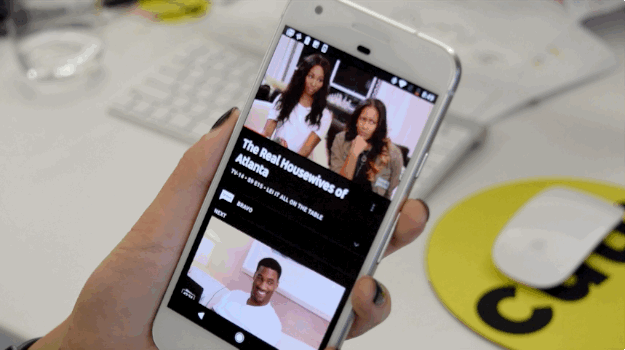
The experience is great on mobile (it’s available on Android, iPhone, and iPad, as well as web and Chromecast). The “Live” tab in the app feels the most like a traditional TV experience. You can scroll through different channels and preview what’s streaming live on each. To start watching a show, you tap in and are taken to a different page with the stream on top and lots of extra content around it, like what’s coming up next and shortcuts to jump to most recently watched channels.
Underneath the stream, there’s a section of recommended content, which is how I went down a Real Housewives rabbit hole for nearly two hours. I recommend tilting your phone to view in landscape, so all of that extra distraction goes away and the show goes full screen.
Nicole Nguyen / BuzzFeed News

Nicole Nguyen / BuzzFeed News
YouTube TV feels a lot like TiVo on your phone.
The playback works like TiVo (lol, remember TiVo??). What you’re watching is live, but you can pause, rewind, and move forward. Unfortunately, like live TV, you have to sit through ads. All of them. (Unless you’ve DVR’d the content and can fast forward.)
Also like TiVo, you can save upcoming live content to your DVR. Throughout the app, you&039;ll see a big (+) plus button that indicates you can “add” that show or movie to your library. Any show in your library will be recorded the next time it airs on TV, no matter which network it’s on.

Nicole Nguyen / BuzzFeed News
Both new episodes and reruns will be recorded in Google’s cloud, and you weirdly can’t set the app to record just new episodes, but that doesn’t matter, since YouTube TV’s DVR has unlimited storage space.
There are YouTube videos embedded throughout the app.
The YouTube TV app takes plenty of opportunities to suggest you watch YouTube videos. Scripted shows like Scandal and reality TV series like Real Housewives have their own landing pages with “Related on YouTube” sections that are auto-populated with YouTube content about the show. For Keeping Up With the Kardashians, there were highlights from past episodes uploaded by E&033;’s official YouTube account. The Bachelor, on the other hand, featured an interview from Nick and Vanessa, the series’ newest couple, on Jimmy Kimmel Live and a video titled “Top 10 Worst Bachelors On The Bachelor” by a user named MsMojo (hard agree).

Nicole Nguyen / BuzzFeed News
What you can and can’t watch on-demand is a bit confusing.
The availability of a show&039;s episodes depends completely on the network. Let’s say you missed last night’s episode of Scandal on ABC and failed to add the show to your “library” beforehand. You can stream the last five episodes, as you would on ABC Go (with a TV provider account) or Hulu Plus.
On Fox’s Empire, you can stream the entire season so far, but only season three is available on YouTube TV, while Hulu has seasons one through three. The same goes for NBC’s The Voice. All 13 episodes that have aired this season are available.
For MSNBC’s The Rachel Maddow Show only one episode, the latest, can be streamed. That’s also true of All In With Chris Hayes.
You can DVR games for teams, but you can’t follow individual athletes.

Nicole Nguyen / BuzzFeed News
If you love hockey or basketball, you’ll be able to record upcoming games from your favorite teams. But if you’re a tennis fan, you can’t add “Roger Federer” to your library. You could only watch the US Open if it’s playing on one of the networks signed on to YouTube TV.
Ultimately, a streaming service is only as good as its content, and if YouTube TV doesn’t offer a show you watch, it’s not worth it.
On day one, the YouTube TV service will be pretty limited. For now, the service is only open to viewers in LA, New York, Chicago, Philadelphia, and the San Francisco Bay Area. Google says that more markets will follow in the coming months.
If you’re into network shows with a strong live following like The Bachelor, ones that are more timely like NBC Nightly News, or live sports, then YouTube TV isn’t a hard sell. Its closest competitor is Sling TV, starting at $20 per month, though most customers get Sling Blue ($25), plus a variety of extras for news and lifestyle channels at an additional $5 per month per package. Sling has noteworthy channels that YouTube TV doesn’t, like CNN and Comedy Central and recently launched a 50-hour cloud DVR service for $5 per month.
If you’re addicted to HBO’s Game of Thrones or Amazon’s Transparent, then YouTube TV probably isn’t your best choice. HBO, like most premium networks, offers a standalone Internet-only subscription service called HBO Now for $15 per month, specifically targeting cord cutters. Amazon Prime Video costs $9 per month, which is similarly priced to other on-demand services like Hulu Plus and Netflix. If you are already an Amazon Prime member, you get limited access to the Prime Video library. For most cord cutters, it might be better to mix-and-match services with content you’ll actually watch than to pay $35 a month for YouTube TV.
Quelle: <a href="Here&039;s A First Look At YouTube&039;s Cable TV Service“>BuzzFeed






