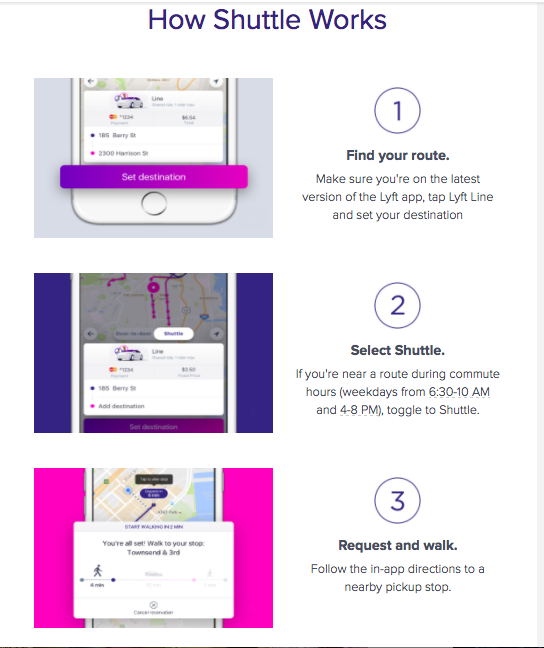
Deep learning is impacting everything from healthcare, transportation, manufacturing, and more. Companies are turning to deep learning to solve hard problems like image classification, speech recognition, object recognition, and machine translation. In this blog post, Intel’s BigDL team and Azure HDInsight team collaborate to provide the basic steps to use BigDL on Azure HDInsight.
What is Intel’s BigDL library?
In 2016, Intel released its BigDL distributed Deep Learning project into the open-source community, BigDL Github. It natively integrates into Spark, supports popular neural net topologies, and achieves feature parity with other open-source deep learning frameworks. BigDL also provides 100+ basic neural networks building blocks allowing users to create novel topologies to suit their unique applications. Thus, with Intel’s BigDL, the users are able to leverage their existing Spark infrastructure to enable Deep Learning applications without having to invest into bringing up separate frameworks to take advantage of neural networks capabilities.
Since BigDL is an integral part of Spark, a user does not need to explicitly manage distributed computations. While providing a high-level control “knobs” such as number of compute nodes, cores, and batch size, a BigDL application leverages stable Spark infrastructure for node communications and resource management during its execution. BigDL applications can be written in either Python or Scala and achieve high performance through both algorithm optimization and taking advantage of intimate integration with Intel’s Math Kernel Library (MKL). Check out Intel’s BigDL portal for more details.
Azure HDInsight
Azure HDInsight is the only fully-managed cloud Hadoop offering that provides optimized open source analytic clusters for Spark, Hive, MapReduce, HBase, Storm, Kafka, and R Server backed by a 99.9% SLA. Other than that, HDInsight is an open platform for 3rd party big data applications such as ISVs, as well as custom applications such as BigDL.
Through this blog post, BigDL team and Azure HDInsight team will give a high-level view on how to use BigDL with Apache Spark for Azure HDInsight. You can find a more detailed step to use BigDL to analyze MNIST dataset in the engineering blog post.
Getting BigDL to work on Apache Spark for Azure HDInsight
BigDL is very easy to build and integrate. There are two major steps:
Get BigDL source code and build it to get the required jar file
Use Jupyter Notebook to write your first BigDL application in Scala
Step 1: Build BigDL libraries
The first step is to build the BigDL libraries and get the required jar file. You can simply ssh into the cluster head node, and follow the build instructions in BigDL Documentation. Please be noted that you need to install maven in headnode to build BigDL, and put the jar file (dist/lib/bigdl-0.1.0-SNAPSHOT-jar-with-dependencies.jar) to the default storage account of your HDInsight cluster. Please refer to the engineering blog for more details.
Step 2: Use Jupyter Notebook to write your first application
HDInsight cluster comes with Jupyter Notebook, which provides a nice notebook-like experience to author Spark jobs. Here is a snapshot of a Jupyter Notebook running BigDL on Azure Spark for Apache HDInsight. For detailed step-by-step example of implementing a popular MNIST dataset training using LeNet model, please refer to this Microsoft’s engineering blog post. For more details on how to use Jupyter Notebooks on HDInsight, please refer to the documentation.
BigDL workflow and major components
Below is a general workflow of how BigDL trains a deep learning model on Apache Spark: As shown in the figure, BigDL jobs are standard Spark jobs. In a distributed training process, BigDL will launch spark tasks in executor (each task leverages Intel MKL to speed up training process).
A BigDL program starts with import com.intel.analytics.bigdl._ and then initializes the Engine, including the number of executor nodes and the number of physical cores on each executor.
If the program runs on Spark, Engine.init() will return a SparkConf with proper configurations populated, which can then be used to create the SparkContext. For this particular case, the Jupyter Notebook will automatically set up a default spark context so you don’t need to do the above configuration, but you do need to configure a few other Spark related configuration which will be explained in the sample Jupyter Notebook.
Conclusion
In this blog post, we have demonstrated the basic steps to set up a BigDL environment on Apache Spark for Azure HDInsight, and you can find a more detailed step to use BigDL to analyze MNIST dataset in the engineering blog post “How to use BigDL on Apache Spark for Azure HDInsight.” Leveraging BigDL Spark library, a user can easily write scalable distributed Deep Learning applications within familiar Spark infrastructure without an intimate knowledge of the configuration of the underlying compute cluster. BigDL and Azure HDInsight team have been collaborating closely to enable BigDL in Apache Spark for Azure HDInsight environment.
If you have any feedback for HDInsight, feel free to drop an email to hdifeedback@microsoft.com. If you have any questions for BigDL, you can raise your questions in BigDL Google Group.
Resources
Learn more about Azure HDInsight
Aritificial Intelligence Software and Hardware at Intel
BigDL introductory video
Quelle: Azure