Anzeige: Digitale Zeitschaltuhr-Steckdose unter 35 Euro bei Amazon
Die digitale Zeitschaltuhr-Steckdose im Dreierpack spart Strom, erhöht den Komfort und ist heute zum neuen Amazon-Bestpreis zu haben. (Technik/Hardware)
Quelle: Golem

Die digitale Zeitschaltuhr-Steckdose im Dreierpack spart Strom, erhöht den Komfort und ist heute zum neuen Amazon-Bestpreis zu haben. (Technik/Hardware)
Quelle: Golem

Das Investment-Unternehmen erhält im Gegenzug KI-Modelle für seine Dienstleistungen und OpenAI die Unternehmensdaten für KI-Trainings. (OpenAI, KI)
Quelle: Golem

Aktuell gibt es bei Amazon ein interessantes Angebot zu einer Einsteigerdrohne. Sie ist für deutlich unter 100 Euro erhältlich. (Drohne, Amazon)
Quelle: Golem

Eine Akkuwerkstatt meldet: US-Panasonic-Akkus in Teslas hielten rund 400.000 Kilometer durch, LG-Zellen aus China nur 240.000 Kilometer. (Tesla, Elektroauto)
Quelle: Golem

Das Oberlandesgericht Hamm schaltet bei der Sammelklage gegen Vodafone den Europäischen Gerichtshof ein. Damit verzögert sich ein Urteilsspruch. (Vodafone, DSL)
Quelle: Golem

In Android klaffen zwei gefährliche Sicherheitslücken, die bereits aktiv ausgenutzt werden. Google hat sie zusammen mit über 100 weiteren gepatcht. (Sicherheitslücke, Google)
Quelle: Golem

Elektroautos sind leise – angenehm für die Passagiere, potenziell gefährlich für Fußgänger und Radfahrer. Ein neues Brummen könnte helfen. (Elektroauto, Wissenschaft)
Quelle: Golem
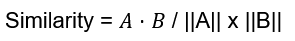
Embeddings have become the backbone of many modern AI applications. From semantic search to retrieval-augmented generation (RAG) and intelligent recommendation systems, embedding models enable systems to understand the meaning behind text, code, or documents, not just the literal words.
But generating embeddings comes with trade-offs. Using a hosted API for embedding generation often results in reduced data privacy, higher call costs, and time-consuming model regeneration. When your data is private or constantly evolving (think internal documentation, proprietary code, or customer support content), these limitations quickly become blockers.
Instead of sending data to a remote service, you can easily run local embedding models on-premises with Docker Model Runner. Model Runner brings the power of modern embeddings to your local environment, giving you privacy, control, and cost-efficiency out of the box.
In this post, you’ll learn how to use embedding models for semantic search. We’ll start by covering the theory behind embedding and why developers should run them. Then, we’ll wrap up with a practical example, using Model Runner, to help you get started.
Understanding semantic search embeddings
Let’s take a moment to first demystify what embeddings are.
Embeddings represent words, sentences, and even code as high-dimensional numerical vectors that capture semantic relationships. In this vector space, similar items cluster together, while dissimilar ones are farther apart.
For example, a traditional keyword search looks for exact matches. If you search for “authentication”, you’ll only find documents containing that exact term. But with embeddings, searching for “user login” might also surface results about authentication, session management, or security tokens because the model understands that these are semantically related ideas.
This makes embeddings the foundation for more intelligent search, retrieval, and discovery — where systems understand what you mean, not just what you type.
For a deeper perspective on how language and meaning intersect in AI, check out “The Language of Artificial Intelligence”.
How Vector Similarity Enables Semantic Search with Embeddings
Here’s where the math behind semantic search comes in, and it’s elegantly simple.
Once text is converted into vectors (lists of numbers), we can measure how similar two pieces of text are using cosine similarity:
Where:
A is your query vector (e.g., “user login”),
B is another vector (e.g., a code snippet or document).
The result is a similarity score, typically between 0 and 1, where values closer to 1 mean the texts are more similar in meaning.
In practice:
A search query and a relevant document will have a high cosine similarity.
Irrelevant results will have low similarity.
This simple mathematical measure allows you to rank documents by how semantically close they are to your query, which powers features like:
Natural language search over docs or code
RAG pipelines that retrieve contextually relevant snippets
Deduplication or clustering of related content
With Model Runner, you can generate these embeddings locally, feed them into a vector database (like Milvus, Qdrant, or pgvector), and start building your own semantic search system without sending a single byte to a third-party API.
Why use Docker Model Runner to run embedding models
With Model Runner, you don’t have to worry about setting up environments or dependencies. Just pull a model, start the runner, and you’re ready to generate embeddings, all inside a familiar Docker workflow.
Full data privacy
Your sensitive data never leaves your environment. Whether you’re embedding source code, internal documents, or customer content, you can rest assured that everything stays local — no third-party API calls, no network exposure.
Zero cost per embedding
There are no usage-based API costs. Once you have the model running locally, you can generate, update, or rebuild your embeddings as often as you need, at no extra cost.
That means iterating on your dataset or experimenting with new prompts won’t affect your budget.
Performance and control
Run the model that best fits your use case, leveraging your own CPU or GPU for inference.
Models are distributed as OCI artifacts, so they integrate seamlessly into your existing Docker workflows, CI/CD pipelines, and local development setups. This means you can manage and version models just like any other container image, ensuring consistency and reproducibility across environments.
Model Runner lets you bring models to your data, not the other way around, unlocking local, private, and cost-effective AI workflows.
Hands-on: Generating embeddings with Docker Model Runner
Now that we understand what embeddings are and how they capture semantic meaning, let’s see how simple it is to generate embeddings locally using Model Runner.
Step 1. Pull the model
docker model pull ai/qwen3-embedding
Step 2. Generate Embeddings
You can now send text to this endpoint via curl or your preferred HTTP client:
curl http://localhost:12434/engines/v1/embeddings
-H "Content-Type: application/json"
-d '{
"model": "ai/qwen3-embedding",
"input": "A dog is an animal"
}'
The response will include a list of embedding vectors, which is a numerical representation of your input text.
You can store these vectors in a vector database like Milvus, Qdrant, or pgvector to perform semantic search or similarity queries.
Example use case: Semantic search over your codebase
Let’s make it practical.
Imagine you want to enable semantic code search across your project repository.
The process will look like:
Step 1. Chunk and embed your code
Split your codebase into logical chunks. Generate embeddings for each chunk using your local Docker Model Runner endpoint.
Step 2. Store embeddings
Save those embeddings along with metadata (file name, path, etc.). You would usually use a Vector Database to store these embeddings, but in this demo, we’re going to store them in a file for simplicity.
Step 3. Query by meaning
When a developer searches “user login”, you embed the query and compare it to your stored vectors using cosine similarity.
We have included a demo in the Docker Model Runner repository that does exactly that.
Figure 1: Codebase example demo with embeddings stats, example queries, and search results.
Conclusion
Embeddings help applications work with intelligent meaning, not just keywords. The old hassle was wiring up third-party APIs, juggling data privacy, and watching per-call costs creep up.
Docker Model Runner flips the script. Now, you can run embedding models locally where your data lives with full control over your data and infrastructure. Ship semantic search, RAG pipelines, or custom search with a consistent Docker workflow — private, cost-effective, and reproducible.
No usage fees. No external dependencies. By bringing models directly to your data, Docker makes it easier than ever to explore, experiment, and innovate, safely and at your own pace.
How you can get involved
The strength of Docker Model Runner lies in its community, and there’s always room to grow. We need your help to make this project the best it can be. To get involved, you can:
Star the repository: Show your support and help us gain visibility by starring the Docker Model Runner repo.
Contribute your ideas: Have an idea for a new feature or a bug fix? Create an issue to discuss it. Or fork the repository, make your changes, and submit a pull request. We’re excited to see what ideas you have!
Spread the word: Tell your friends, colleagues, and anyone else who might be interested in running AI models with Docker.
We’re incredibly excited about this new chapter for Docker Model Runner, and we can’t wait to see what we can build together. Let’s get to work!
Get started with Docker Model Runner →
Learn more
Check out Docker Model Runner integration with vLLM announcement
Visit our Model Runner GitHub repo! Docker Model Runner is open-source, and we welcome collaboration and contributions from the community!
Get started with Docker Model Runner with a simple hello GenAI application
Quelle: https://blog.docker.com/feed/
AWS Transform for mainframe now offers test planning and automation features to accelerate mainframe modernization projects. New capabilities include automated test plan generation, test data collection scripts, and test case automation scripts, alongside functional test environment tools for continuous delivery and regression testing, helping accelerate and de-risk testing and validation during mainframe modernization projects. The new capabilities address key testing challenges across the modernization lifecycle, reducing the time and effort required for mainframe modernization testing, which typically consumes over 50% of project duration. Automated test plan generation helps teams reduce upfront planning efforts and align on critical functional tests needed to mitigate risk and ensure modernization success, while test data collection scripts accelerate the error-prone, complex process of capturing mainframe data. Test automation scripts then enable scalable execution of test cases by automating test environment staging, test case execution, and results validation against expected outcomes. By automating complex testing tasks and reducing dependency on scarce mainframe expertise, organizations can now modernize their applications with greater confidence while improving accuracy through consistent, automated processes. The new testing capabilities in AWS Transform for mainframe are available today in US East (N. Virginia), Asia Pacific (Mumbai), Asia Pacific (Seoul), Asia Pacific (Sydney), Asia Pacific (Tokyo), Canada (Central), Europe (Frankfurt), and Europe (London) Regions. To learn more about automated testing in AWS Transform for mainframe, and how it can help your organization accelerate modernization, read the AWS News Blog, visit the AWS Transform for mainframe product page, or explore the AWS Transform User Guide.
Quelle: aws.amazon.com
AWS Transform custom is now generally available, accelerating organization-specific code and application modernization at scale using agentic AI. AWS Transform is the first agentic AI service to accelerate the transformation of Windows, mainframe, VMware, and more—reducing technical debt and making your tech stack AI-ready. Technical debt accumulates when organizations maintain legacy systems and outdated code, requiring them to allocate 20-30% of their software development resources to repeatable, cross-codebase transformation tasks that must be performed manually. AWS Transform can automate repeatable transformations of version upgrades, runtime migrations, framework transitions, and language translations at scale, reducing execution time by over 80% in many cases while eliminating the need for specialized automation expertise.
The custom transformation agent in AWS Transform provides both pre-built and custom solutions. It includes out-of-the-box transformations for common scenarios, such as Python and Node.js runtime upgrades, Lambda function modernization, AWS SDK updates across multiple languages, and Java 8 to 17 upgrades (supporting any build system including Gradle and Maven). For organization-specific needs, teams can define custom transformations using natural language, reference documents, and code samples. Users can trigger autonomous transformations with a simple one-line CLI command, which can be scripted or embedded into any existing pipeline or workflow. Within your organization, the agent continually learns from developer feedback and execution results, improving transformation accuracy and tightly aligning the agent’s performance with your organization’s preferences. This approach enables organizations to systematically address technical debt at scale, with the agent continually improving while developers can focus on innovation and high-impact tasks.
AWS Transform custom is now available in the US East (N. Virginia) AWS Region.
To learn more, visit the user guide, overview page, and pricing page.
Quelle: aws.amazon.com