Nuri bzw. Bitwala: Berliner Fintech-Start-up geht das Geld aus
Das Berliner Fintech findet keine neuen Investoren. Nuri hat mit der insolventen Krypto-Börse Celsius zusammengearbeitet. (Fintech, Wirtschaft)
Quelle: Golem

Das Berliner Fintech findet keine neuen Investoren. Nuri hat mit der insolventen Krypto-Börse Celsius zusammengearbeitet. (Fintech, Wirtschaft)
Quelle: Golem

Eine Umsatzwarnung vorab: Nvidia hat im zweiten Quartal 2022 weit über eine Milliarde US-Dollar weniger mit Geforce-Grafikkarten verdient. (Nvidia, Wirtschaft)
Quelle: Golem

CutefishOS ist eine von Hunderten Linux-Distibutionen. Es starb, sollte geforkt werden und war plötzlich wieder da. Und wieso? Weil es “cute” ist. Von Boris Mayer (Linux-Distribution, Debian)
Quelle: Golem

Nach einer Entscheidung des Landgerichts München erhalten Webseitenbetreiber mit eingebundenen Google Fonts vermehrt Abmahnungen. (Politik/Recht, Google)
Quelle: Golem
One of the most exciting things about WordPress is that it’s constantly improving. In fact, did you know that Gutenberg releases new functionality and improvements every two weeks?! There have been a number of really cool and powerful capabilities rolled out over the last few months that give you even more control over the design of your site and your content. We wanted to take a minute to highlight some that we’re especially excited about.
Note: These updates are most relevant to those of you who have a block theme activated.
Use Your Featured Image in the Cover Block Borders in Layout BlocksSee What Margin vs Padding Actually DoesPatterns Are Easier to Find and More Convenient to UseLeveling Up the Query Block Notable Mentions
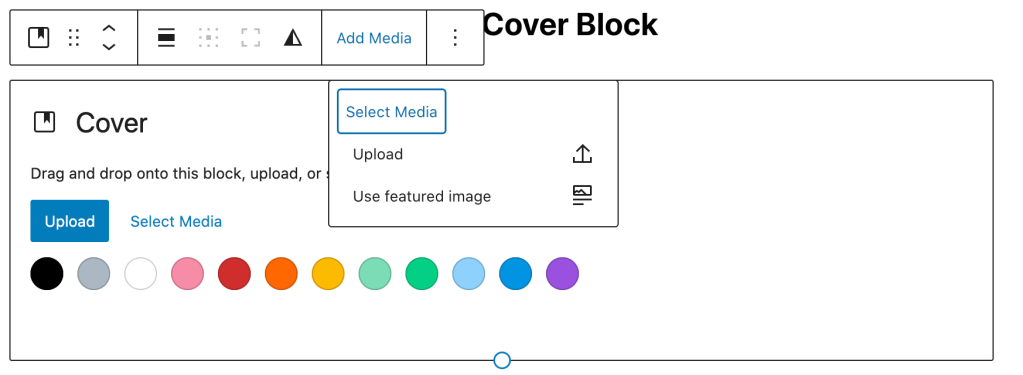
Use Your Featured Image in the Cover Block
Over the last few months the Gutenberg team has really powered up the cover block and its ability to leverage the featured image set in your post/page. Not only can you do that when creating new content, you can use it in your templates too, making it easier than ever to make your featured image a bigger part of every post.
Borders in Layout Blocks
You now have the ability to add and customize borders in the columns, row, stack, and group blocks. Use them for subtle dividers or go nuts to create some fun retro drop-shadows. This is a great way to make different sections on your site stand out!
See What Margin vs Padding Actually Does
I’ve been working in the web space for a long time and I still get confused with how padding and margin will impact my layout — especially when there are multiple layers of blocks involved! You will now see exactly where the change is being applied as you adjust your settings.
Patterns Are Easier to Find and More Convenient to Use
Gutenberg 12.7 brings patterns front and center to help save you time and energy. Why recreate a layout block by block when you can start with something more complete? Take advantage of all of the great patterns the WordPress.com designers put together for our customers or maybe consider adding a pattern of your own to the WordPress.org pattern directory.
Leveling Up the Query Block
The Query Loop has grown a lot over the past few months. Not only can you filter by different authors or taxonomies, but you can now filter to show all content under a parent category. This is perfect for creators who create different types of content or jump between drastically different subject matters. It’s really the ultimate block for displaying a collection of posts and it just keeps getting better.
Notable Mentions
You can now customize and display text on your social icons. We’ve made it easier to transform your content into different blocks without losing the work you’ve already done. Your new buttons will keep the design settings you already applied, preventing you from having to re-apply the settings for every button you add.
This is just a small subset of new features released over the last few months. Let us know what you think in the comments and feel free to share your favorites!
Quelle: RedHat Stack

Editor’s note: Today we hear from NTUC Enterprise, which operates a sprawling retail ecosystem, including NTUC FairPrice, Singapore’s largest grocery chain, and a network of Unity pharmacies and Cheers convenience stores. As a social enterprise, NTUC Enterprise’s mission is to deliver affordable value in areas like daily essentials, healthcare, childcare, ready-to-eat meals, and financial services. Serving over two million customers annually, NTUC Enterprise strives to empower all Singaporeans to live more meaningful lives.In August 2021, NTUC FairPrice launched a new app payment solution, allowing customers to pay for purchases and accumulate reward points at any FairPrice store or Unity pharmacy, by simply scanning a QR code. The app eliminates the need to present a physical loyalty or credit card and integrates all customer activities across NTUC FairPrice’s network of stores and services. By using the FairPrice app’s payment feature, customers enjoy a seamless checkout experience at all FairPrice and Unity outlets.The mission to build an integrated app across a network of over 200 stores encountered two challenges that we were able to overcome with Google Cloud solutions, namely Cloud Functions, BigQuery, and Cloud Run:Financial reconciliation: FairPrice transactional data sits in multiple locations, including the point-of-sale (POS) server, the FairPrice app server, and the payment gateway (third-party technology used by merchants to accept purchases from customers). For the app to work, our finance team needed to ensure that all sales data coming from disparate sources are tallied correctly.Platform stability: Instead of a staggered rollout, we opted for a ‘big bang’ launch across all FairPrice and Unity stores across Singapore. System resilience, seamless autoscaling, and a near-zero latency network environment were critical for ensuring that customers weren’t stuck in line due to network delays or outages, especially during peak hours.For a complex operation such as ours, the main technical hurdle was agile syncing between transaction systems. Our finance team needed to ensure that all funds that land in the bank correspond with sales made through our stores’ POS machines. Resolving this issue required a custom solution that integrates disparate data sources across the sales spectrum.At the time, the architecture of our sales system was as follows: The POS system processed a transaction and sends the data into our SAP network. From there, the data was funneled through enterprise resource planning (ERP) workflows managed by the finance team.The actual financial transaction, however, was performed on our FairPrice app server. This communicated with a third-party payment gateway that then transferred funds electronically to our bank.The POS system was sophisticated enough to aggregate different payment methods registered in the FairPrice app, from GrabPay to Visa and Mastercard, and send granular transactions information to finance. But given that it wasn’t executing actual transactions, finance then needed to make extra reconciliations to ensure that the POS data and payment data corresponded. This process placed a significant manual strain on the team, which would only increase as the business continued to grow. Automating financial processes to drive business growth with cloud technologyTo automate financial reconciliation, we used Google Cloud tools and designed a custom solution to integrate POS data with the payment network. Here’s a step-by-step summary of how we integrated all the elements of our transactions ecosystem, unlocking the potential for growth in our FairPrice app: We first worked with the POS team to set up real-time data pipelines to import all transactional data across our retail network, from online sales to physical store purchases, into Cloud Storage every five minutes. Next, we deployed Cloud Functions to detect changes made in Cloud Storage, before processing the data and syncing it with BigQuery, our main data analytics engine for data imported from POS systems into SAP systems. Leveraging CloudSQL as our main managed database, we created data pipelines from the app server into BigQuery. We created two parallel channels to ingest datastreams into BigQuery, which then became a unified data processing engine for unlimited, real-time insights. At that point, we used Google Cloud Scheduler to send BigQuery data analytics at the end of each day to a SAP secure file transfer protocol (SFTP) folder for processing by the data analytics team. Combining readouts from these two data sources, our data scientists can now build an easy-to-read Data Studio dashboard. If transactions from different systems do not match up, an email alert will be sent to the finance team and other platform stakeholders. Finance then reconciles the transactions in Data Studio to ensure all sales from the POS system and the app server correspond correctly.Combining the power of BigQuery with the convenience of Data Studio provided us with an additional advantage: the finance team, without requiring in-depth technical knowledge, can now easily obtain any piece of data they need without seeking help from the engineering team. The finance team can directly query what they need in BigQuery, and create an instant visualization on the Data Studio dashboard for any business use case. Keeping customers happy with seamless autoscaling driven by Cloud RunOne of the key objectives of launching Pay for our FairPrice app is to enable faster, more seamless checkouts across all stores in our retail network, through quick-and-easy QR code scanning. With a ‘big bang’ rollout, we needed the most powerful and agile computing infrastructure available to handle fluctuations in footfall at our stores, from peak lunchtime to dips in the middle of the night. We sought to combine this ability to autoscale with minimal infrastructure configuration, so our development team could focus on building innovative solutions that delight our customers.Google Kubernetes Engine (GKE) had been powering NTUC FairPrice solutions for a long time. When it came to developing our new payment solution, we decided that it would be a good time to try Cloud Run, cognizant of the complex interplay of APIs required to evolve the app. The aim was to see if we could achieve even more automation and ease-of-use in scaling and deploying our solution. The experiment paid off as we gained a new dimension of API agility through the optimized deployment of Cloud Run features. Here’s an overview of how we leveraged Cloud Run to support failure-free store operation with virtually no manual configuration:Default endpoints: Our FairPrice app deploys a wide range of proprietary APIs to synchronize all aspects of the solution. Cloud Run’s key advantage here is that provides a secure HTTPS endpoint by default. This automates the connection of APIs to software programs, removing the need to set up extra layers of network components to manage APIs. Ensuring this strong connectivity results in a seamless experience for shoppers.Automated configuration: Even with Autopilot, the new GKE operating environment, we still needed to set up CPU and memory for our microservices clusters. With Cloud Run, we’re freed from this task. All that is required is to set the maximum instance variable, and Cloud Run takes care of the rest, by automatically scaling microservice clusters in real-time according to our needs. This saves our DevOps team several hours per week, which they can devote to developing new features and updates for the FairPrice app. Ultimately, this convenience is passed on to our customers, translating into a more seamless and enjoyable shopping experience. In just one year since launching Pay for the FairPrice app, we have gained measurable benefits from the innovations enabled by Google Cloud tools: A 90% rate of return to the app. This means that nine out of 10 customers who use the app once will continue using it for subsequent purchases. Added nearly 270,000 new FairPrice customers to the app, and that number is growing at an exponential rate. Since launching the app, we have been able to convert 6% of offline transactions into digital transactions.Given that app availability and seamless end user experiences are major factors in Net Promoter Scores (NPS), NTUC FairPrice has achieved ~75% in overall customer satisfaction.Building Singapore’s food “super app” with Google Cloud toolsWe’re excited about the next stage of our digital evolution, which is to turn the FairPrice App into a food ‘super app.’ We aim to spark customer delight in everything related to food within the NTUC FairPrice Group network. This includes “hawker centers” (food courts), restaurants, deliveries, and takeaways.All of these services will be built on Google Cloud solutions, in particular Cloud Run and BigQuery. We believe that with our newfound autoscaling and data analytics capabilities, NTUC FairPrice is ready to bring the business to new heights, and meet Singapore’s appetite for great food.Related ArticleNew Singapore GCP region – open nowThe Singapore region is now open as asia-southeast. This is our first Google Cloud Platform (GCP) region in Southeast Asia and our third …Read Article
Quelle: Google Cloud Platform

Storing state with containers Kubernetes has become the preferred choice for running not only stateless workloads (e.g., web services) but also for stateful applications (e.g., e-commerce applications). According to the Data on Kubernetes report, over 70% of Kubernetes users run stateful applications in containers. Additionally, there is a rising trend of managed data services like MariaDB and Databricks using Google Kubernetes Engine to power their SaaS businesses to benefit from the portability of Kubernetes, built-in auto-upgrade features such as blue-green deployments, backup for GKE and out-of-the-box cost efficiency for better unit economics. All of this means that container-native storage on GKE is increasingly important. Specifically, storage that can be seamlessly attached and detached to containers as they churn (because the average container lifetime is much shorter than VMs) and remain portable across zones to stay resilient. That’s where Filestore Enterprise fits in. Customers get a fully managed regional file system with four 9s of availability. Storage is instantaneously attached to containers as they churn and zonal failovers are handled seamlessly. The rest of this blog explores multiple storage options with containers and how Filestore Enterprise fits in to help guide customers to make decisions of the best storage option that meets their needs.External persistent state for “stateless” containers (left) vs. persistent containers with CSI managed state within persistent volumes (right)Storage optionsThree storage models (from left to right): local file system, SAN and NAS.To understand the lay of the land, let’s explore three options for common patterns for attached storage with containers (note: Cloud Storage is accessed via the application code in a container and not covered here). Local file system over a local SSD device: A local file system (over local ssd block device) is the simplest to set up and can be very cost-effective and provide good performance (over local SSD), but in most cases it lacks enterprise storage capabilities such as snapshots, backups, and asynchronous DR. Also it provides limited reliability and redundancy as the state is host local. This model is well suited for scratch space/ephemeral storage use cases, but much less so for production-level, mission-critical use cases.Local file system over a remote/shared block device (SAN): The SAN (Storage Area Network) model is powerful and well known. A SAN-backed remote volume can provide good performance, advanced storage services, and good reliability. As the volume is external to the containers’ host, the persistent volume can be reattached (mounted) to a different host in case of container migration or if the original one failed, but is predominantly limited to only one host and Pod at a time. In the cloud world, SAN devices are replaced by networked block services, such as Google Cloud Persistent Disk (PD).Remote/networked file system (NAS): The NAS (Network Attached Storage) model is semantically a powerful storage model as it also allows read-write sharing of the volume across several containers. In such a model the file system logic is implemented in a remote filer and accessed via a dedicated file system protocol, most commonly Network File System (NFS). In the cloud world, NAS devices are commonly replaced by file system services such as Filestore.GCP block and file storage backendsIn Google Cloud non-local storage can be implemented using either PD or Filestore. PD provides flexible SSD- or HDD-backed block storage, while Filestore provides NFSv3 file volumes. Both models are CSI (Container Storage Interface) managed and fully integrated into the GKE management system. The main advantages and disadvantages of both models (depicted below) are as follows:PD provides capacity-optimized storage (HDD) and good price-performance variants (SSD, Balanced). PD provides flexible sizes and zonal volumes. On the other hand, PD based volumes do not support read-write sharing. This means multiple containers can’t read and write to the same volume. Customers can choose Regional support (RePD) but this is limited to active-passive models. PD-backed volumes support container migration and failover (after host failures), but such migration or failover may require time and expertise to implement.Filestore provides similar HDD and SSD variants and active-active regional (enterprise) variants. All Filestore variants support the read-write sharing model and almost instantaneous container migration and failover. Because of this increased functionality, Filestore-backed volumes have higher cost compared to the PD-backed volumes and have a minimum size limit of 1TB.Main Google Cloud storage models PD & FilestoreFilestore as fully managed container storageBoth PD and Filestore support container native operations such as migrating containers across hosts for use cases such as upgrades or failover. Customers on PD get best-in-class price/performance with extensive selection of multiple PD types. That’s why PD is popular with many GKE customers, as they benefit from price-performance and capabilities. However, with PD, customers need to have expertise in storage systems. In PD, the file system logic is built into the host. This coupling means during migration the host must cleanly shut down the container, unmount the file system, reattach the PD to the target host, mount the file system and only then boot the container. While GKE manages a lot of these operations automatically, in the case of failover there are potential file system and disk corruption issues. Users will need to run some cleanup processes (“fsck”) on the mounted volume before it can be used. With Filestore, customers get a fully managed regional file system that is decoupled from the host. Customers don’t need any expertise to operate storage and failovers are handled seamlessly as there are no infrastructure operations to attach/detach volumes. In addition, customers also benefit from storage that can be simultaneously read and written to by multiple containers.In addition to the general value of the Filestore as a GKE backend, Filestore Enterprise supports mission-critical and medium-to-large stateful deployments as it adds regional (four 9s) availability, active-active zone access, instantaneous snapshots, and smaller SSD entry point for each volume. Summary and conclusionsGoogle Cloud offers several fully managed options for GKE persistent volumes. In addition to the PD-based volumes, Filestore Enterprise is a first-class citizen storage backend for GKE and can also serve mission-critical use cases where (active/active) regional redundancy and fast failover/migration are important. Furthermore, Filestore Enterprise is just getting started on delivering better price-performance efficiency for customers. For example, customers can access a private preview to drive higher utilization of Filestore Enterprise instances by bin packing volumes as shares. Summary tableLinksAccessing file shares from Google Kubernetes Engine clusters | FilestoreHow persistent container storage works — and why it mattersDisk and image pricing | Compute Engine: Virtual Machines (VMs) | Google CloudPersistent disksService tiers Using the Filestore CSI driver1. The full list of PD models and pricing can be found here: https://cloud.google.com/compute/disks-image-pricing#disk
Quelle: Google Cloud Platform
Application modernization is quickly becoming one of the pillars of successful digital transformation and cloud migration initiatives. Many organizations are becoming aware of the dramatic benefits that can be achieved by moving legacy, on-premises apps and databases into cloud native infrastructure and services, such as reduced Total Cost of Ownership (TCO), elimination of expensive commercial software licenses, and improved performance, scalability, security and availability.The complexity of applications and databases to a cloud-centric architecture requires a rapid, accurate, and customized assessment of modernization potential and identification of challenges. Addressing business and functional drivers, TCO calculations, uncovering technological challenges and cross-platform incompatibilities, preparation of migration, and rollback plans can be essential to the success and outcome of the migration. These cloud migration initiatives are often divided into three high-level phases: Discovery: identifying and cataloging the source inventory. Output is usually an inventory of source apps, databases, servers, networking, storage, etc. The discovery of existing assets within a data center is usually straightforward and can often be highly automated. Pre-migration readiness: the planning phase. This includes the analysis of the current portfolio of the databases and applications for migration readiness, determining the target architecture, identifying technological challenges or incompatibilities, calculating TCO, and preparing detailed migration plans. Migration execution: where the rubber hits the road. During this phase of the migration process, database schemas are actively converted, the application data access layer is refactored, data is replicated from source to target, often in real-time, and the application is deployed in its determined compute platform(s). Successful evaluation and planning phase as part of the pre-migration readiness phase can bolster confidence in investment towards modernization. Skipping or inaccurately completing the pre-migration phase can lead to a costly and sub-optimal result. Relying on manual pre-migration assessments can lead to long migration timelines, reduced success rates and poor confidence in the post-migration state, increased risk and total migration cost. Some of the commonly asked question during pre-migration include:How compatible are my source databases, which are often commercial and proprietary in nature, with their open-source cloud-native alternatives? For example, how compatible are my Oracle workloads and usage patterns with Cloud SQL for PostgreSQL? What’s my degree of vendor lock-in with my current technology stack? Are proprietary features and capabilities being used that are incompatible with open-source database technologies?How tightly-coupled are my applications with my current database engine technology? Can my applications be deployed as-is, refactored for cloud readiness with ease, or will it be a big undertaking? How much effort will my migration require? How expensive will it be? What will be my run-rate in Google Cloud post-migration and my ROI?Can we identify quick-win applications and databases to start with?There is a direct association between the accuracy and speed of the pre-migration phase and the outcome of the migration itself. The faster and more accurately organizations complete the required pre-migration analysis, the more cost efficient and successful the migration itself will usually be. EPAM Systems, Inc., a leader in digital transformation, worked with Google Cloud as a preferred partner to accelerate cloud migrations beginning with pre-migration assessments. Leveraging EPAM’s migVisor for Google Cloud—a unique pre-migration accelerator that automates the pre-migration process—and EPAM’s consulting and support services, organizations can quickly generate a cloud migration roadmap for rapid and systematic pre-migration analysis. This approach has resulted in the completion of thousands of database assessments for hundreds of customers.migVisor is agentless, non-intrusive, and hosted in the EPAM cloud. migVisor seamlessly connects to your source databases and runs SQL queries to ascertain the database configuration, code, schema objects and infrastructure setup. Scanning of source databases is done rapidly and without interruption to production workloads.migVisor prepares customers to land applications in Google Cloud and its managed suite of databases services and platforms such as Cloud SQL, bare metal hosting, Spanner and Cloud Bigtable. migVisor supports re-hosting (lift-and-shift), re-platforming, and re-factoring. “EPAM’s recent application assessment update to its migration tooling system, migVisor, will bring a new level of transparency to the entire application and database modernization process”, said Dan Sandlin, Google Cloud Data GTM Director at Google Cloud. “This enables organizations to make the most of digital technologies and provides a clear IT ecosystem transformation that allows our customers to build a flexible foundation for future innovation.”Previously, migVisor focused on assessments of the source databases and the compatibility of customers’ existing database portfolio with cloud-centric database technologies. Coming this quarter, migVisor adds support for application assessments, augmenting its existing and class-leading capabilities in the database space. The addition of application modernization assessment functionality in migVisor, combined with EPAM’s certification and specialization in Google Cloud Data Management and hands-on engineering experience, strengthens EPAM’s position as a leader for large-scale digital transformation projects and migVisor as a trusted product for cloud migration assessments to Google Cloud customers. EPAM provides customers an end-to-end solution for faster and more cost-effective migrations. Assessments that used to take weeks can now be completed in mere days. Within minutes of registering for an account, anyone can start usingmigVisor by EPAM to automatically assess applications and application code. Visit themigVisor page to learn more and sign up for your account.Related ArticleAccelerate Google Cloud database migration assessments with EPAM’s migVisorThe Database Migration Assessment is a Google Cloud-led project to help customers accelerate their deployment to Google Cloud databases w…Read Article
Quelle: Google Cloud Platform
This blog post has been co-authored by Kapil Raval, Principal Program Manager, Microsoft.
Bluware, which develops cloud-native solutions to help oil and gas operators to increase exploration and production workflow productivity through deep learning by enabling geoscientists to deliver faster and smarter decisions about the subsurface and today announced its collaboration with Microsoft for its next-generation automated interpretation solution, InteractivAI™, which is built on the Azure implementation of the OSDU™ Data Platform.
The two companies are working together to provide comprehensive solutions combining Microsoft Cloud implementation of OSDU™ Data Platform with Bluware’s subsurface knowledge. As the world’s energy companies retool for the future, they are juggling priorities between new forms of energy, carbon emissions, and maintaining the growing demand for fossil fuels. Innovative solutions such as cloud computing and machine learning are playing an important role in this transition.
To address an energy super major’s seismic interpretation challenges, Bluware is providing an interactive deep learning solution that runs natively on Azure, called InteractivAI™.
InteractivAI™ is utilized by the organization’s exploration and reservoir development teams to accelerate seismic interpretations and improve results by assisting geoscientists in identifying geological and geophysical features that may have been previously missed, incorrectly interpreted, or simply too time-consuming to interpret.
Using a data-centric approach, the application is unique in its ability, allowing users to train and infer simultaneously. Imagine running deep learning in real-time where the interpreter is providing feedback that the operator can actually see as the network suggests on-the-fly interpretations. This even includes results on data that is either not readily visible to the human eye or very difficult to see. This interactive workflow delivers more precise and comprehensive results in hours compared to months resulting in higher quality exploration and reservoir development.
The interactive deep learning approach
Bluware is pioneering the concept of ‘interactive deep learning’, wherein the scientist remains in the figurative ‘driver’s seat’ and steers the network as it learns and adapts based on the interpreter’s teachings. The adjustment and optimization of training the data set provides immediate feedback to the network, which in turn adjusts weights and biases accordingly in real-time.
Bluware differs from other deep learning approaches which use a neural network that has been pre-trained on multiple data sets. Users must rely on a network that was trained on data they have not seen, created with a set of unknown biases, and therefore something they have no control over.
The basic parameterization exposed to scientists in these traditional approaches gives the illusion of network control without really ceding any significant control to the user. Processing times can be days or weeks, and scientists can only supply feedback to the network once the training is complete, at which point training will need to run again from scratch.
The interactive deep learning approach is a data-specific approach that focuses on creating the best learning and training model for the geology the user is working with. Unlike traditional deep learning approaches, the idea is to start with a blank, untrained network and train it while labeling to identify any feature of interest. This approach is not limited to salt or faults, but can also be used to capture shallow hazards, injectites, channels, bright spots, and more. This flexibility allows the expert to explore the myriad of possibilities and alternative interpretations within the area of interest.
The energy company initially conducted a two-month evaluation with multiple experts across their global asset teams. The results were remarkable, and the organization is continually adding users. Additionally, Bluware has provided a blueprint for the company’s IT team for an Azure Kubernetes Service (AKS) implementation which will accelerate and expand this Azure-based solution.
A seismic data format designed for the cloud
As companies continue to wrestle with enormous, complex data streams such as petabytes of seismic data, the pressure to invest in digital technology intensifies. Bluware has adapted to this imperative, delivering a cloud-based format for storing seismic data called Volume Data Store™ (VDS). Microsoft and Bluware have worked together to natively enable VDS as part of the Microsoft Cloud implementation of OSDU™ Data Platform, where developers and customers can connect to the seismic data stored and provide interactive AI-driven seismic interpretation workflows by using the InteractivAI™ SaaS from the Azure Appsource.
Bluware and Microsoft are collaborating in parallel to support major energy customers through their seismic shift initiatives including moving petabytes of data to Azure Blob storage in a cloud-native VDS environment.
Revolutionizing the way energy companies store and use seismic data
Bluware designed InteractivAI™ not only with seismic workflows in mind but also with an eye on the trends shaping the future of the energy sector. Creating a cloud-native data format makes it scalable for energy companies to do more with their data while lowering costs and speeding up workflows, allowing them to arrive at more accurate decisions faster leveraging the power of Azure.
About Bluware
In 2018, a group of energy-focused software companies, namely Bluware, Headwave, Hue, and Kalkulo AS merged to become Bluware Corp. to empower change, growth, and a sustainable future for the energy sector.
As companies pivot from fossil fuels to cleaner energy sources, the combination of new industry standards, cloud computing, and AI will be critical for companies to adapt quickly, work smarter, and continue to be profitable. Companies that adapt faster, will have a significant advantage over their competition. For more information, visit Bluware’s website.
Quelle: Azure

The new updated Azure Lab Services allows you to set up and configure Cloud labs for your classroom and training scenarios. You don’t have to worry about setting up, expanding, or managing on-premises labs anymore. We provide a managed service and take the hassle out of managing and maintaining these labs. The updated service comes with improved performance and enhanced backend reliability. With the introduction of virtual network (VNet) injection and more control of the virtual network, you can now unlock key training and classroom scenarios such as lab-to-lab communication and utilize the service to teach a wide range of courses requiring complex configurations. With this new update you also now have an option to integrate the service with the Canvas learning management system.
The introduction of additional roles, Azure policies, and enhanced cost tracking and management capability provides the features you need to fully understand, manage and maintain your service. The availability of a .NET SDK, Python SDK, Azure PowerShell module, and Azure Resource Manager (ARM) templates makes it easy for IT and administrators to automate and manage all aspects of the service. Learn more about the Azure Lab Services update and how to use it.
With major reliability and performance enhancements to the original service, this major update is bringing a whole slew of additional features for IT organizations, administrators, educators, and students.
The update is bringing features and functionality for all personas of the service including administrators, educators, and students.
New features help IT departments and administrators automate and manage
For the IT staff and the service administrators, now there is a concept of creating a lab plan instead of a lab account in the Azure portal to start the process of creating labs. A lab plan is used to create, configure settings, and manage the labs. For ease of administration of the lab, new roles have been created to provide granular control to different people in the organization who will manage and maintain the labs. We are also introducing default and custom Azure policies with this update to help administrators with more control over the management of the labs.
Similar to the older service, you will have to request additional virtual processors (vCPUs), depending on your Azure subscription, and how many labs and virtual machines you want to create in the labs. With this updated release, there is an improved vCPU capacity management for your subscription, and you don't share the vCPU capacity with other customers when using the service.
With the new release, it is also easier to track costs for your labs or the virtual machines utilizing Azure Cost Management. On the networking front, we are introducing Virtual Network Injection compared to virtual network peering, which was offered in the older service. Virtual Network Injection provides you with control of Azure NSG (Network Security Group) and load balancer for your virtual network. Virtual Network Injection supports some of the common scenarios such as lab-to-lab communication, access to Azure or on-premises license server, and utilizing Azure File services.
In order to make it easy for administrators to manage and maintain the service, we are offering a range of tools including a .NET SDK, Python SDK, Azure PowerShell module, and ARM templates. These tools will not only help you with automating and managing your service but can also be utilized to build value-add services on top of our service for your customers.
In alignment with all the global compliance and regulatory laws around data residency, the customers now have a choice to deploy the labs and related virtual machines in their region of choice, so their data stays local to where they want.
More options and flexibility for educators
Educators and instructors are also getting features and new functionality to improve their experience in the service. The updated service can also be integrated with Canvas, a popular learning management system. This makes it easy for educators to stay in Canvas to create, manage, and maintain their labs, and students can also access the labs and virtual machines from within Canvas. Educators now have the option to create labs with virtual machines and assign students to them with non-admin access.
The auto-shutdown feature of the virtual machines has now been improved to work across both Windows and Linux virtual machines. In addition, there are improvements around virtual machine idle detection based on resource usage and user presence. The update also provides additional flexibility to the educator to skip the virtual machine template creation process if they already have an image to use and don’t want to customize it. Using an already existing image or the default image from the Azure marketplace allows for fast creation of the lab compared to when the educator wants to create a lab with an image but will further customize it after the lab is created.
Faster, easier access for students
The updated service has also introduced improvements to the student experience. Students can now troubleshoot any virtual machine access issues by redeploying their virtual machine without losing data. If the lab is set up to use Azure Active Directory (AAD) group sync, there is no longer a need to send an invitation email to the students to register for the lab and get access to the virtual machine. Now, a virtual machine is automatically assigned to the student and they can access it immediately.
Learn more
Enable your educational, learning, and training scenarios today no matter what industry, by using the service. Get started today to use the enhanced experience and new features by utilizing the Azure Lab Services August 2022 update!
Quelle: Azure