We are excited to introduce Phi-3, a family of open AI models developed by Microsoft. Phi-3 models are the most capable and cost-effective small language models (SLMs) available, outperforming models of the same size and next size up across a variety of language, reasoning, coding, and math benchmarks. This release expands the selection of high-quality models for customers, offering more practical choices as they compose and build generative AI applications.
Starting today, Phi-3-mini, a 3.8B language model is available on Microsoft Azure AI Studio, Hugging Face, and Ollama.
Phi-3-mini is available in two context-length variants—4K and 128K tokens. It is the first model in its class to support a context window of up to 128K tokens, with little impact on quality.
It is instruction-tuned, meaning that it’s trained to follow different types of instructions reflecting how people normally communicate. This ensures the model is ready to use out-of-the-box.
It is available on Azure AI to take advantage of the deploy-eval-finetune toolchain, and is available on Ollama for developers to run locally on their laptops.
It has been optimized for ONNX Runtime with support for Windows DirectML along with cross-platform support across graphics processing unit (GPU), CPU, and even mobile hardware.
It is also available as an NVIDIA NIM microservice with a standard API interface that can be deployed anywhere. And has been optimized for NVIDIA GPUs.
In the coming weeks, additional models will be added to Phi-3 family to offer customers even more flexibility across the quality-cost curve. Phi-3-small (7B) and Phi-3-medium (14B) will be available in the Azure AI model catalog and other model gardens shortly.
Microsoft continues to offer the best models across the quality-cost curve and today’s Phi-3 release expands the selection of models with state-of-the-art small models.
Azure AI Studio
Phi-3-mini is now available
Explore the release
Groundbreaking performance at a small size
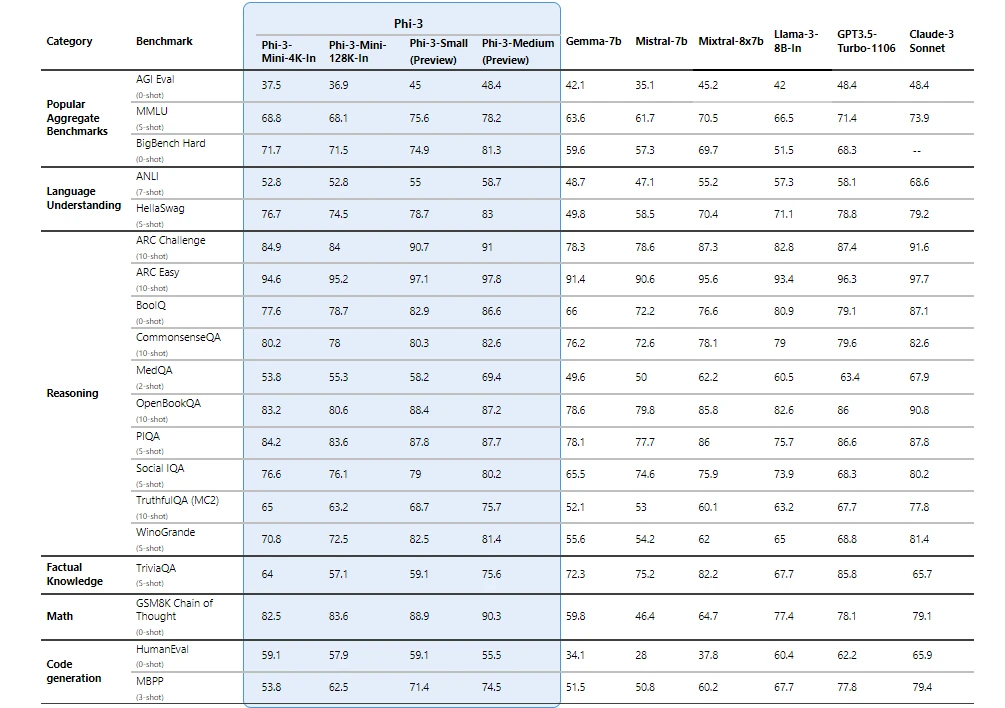
Phi-3 models significantly outperform language models of the same and larger sizes on key benchmarks (see benchmark numbers below, higher is better). Phi-3-mini does better than models twice its size, and Phi-3-small and Phi-3-medium outperform much larger models, including GPT-3.5T.
All reported numbers are produced with the same pipeline to ensure that the numbers are comparable. As a result, these numbers may differ from other published numbers due to slight differences in the evaluation methodology. More details on benchmarks are provided in our technical paper.
Note: Phi-3 models do not perform as well on factual knowledge benchmarks (such as TriviaQA) as the smaller model size results in less capacity to retain facts.
Safety-first model design
Responsible ai principles
Learn about our approach
Phi-3 models were developed in accordance with the Microsoft Responsible AI Standard, which is a company-wide set of requirements based on the following six principles: accountability, transparency, fairness, reliability and safety, privacy and security, and inclusiveness. Phi-3 models underwent rigorous safety measurement and evaluation, red-teaming, sensitive use review, and adherence to security guidance to help ensure that these models are responsibly developed, tested, and deployed in alignment with Microsoft’s standards and best practices.
Building on our prior work with Phi models (“Textbooks Are All You Need”), Phi-3 models are also trained using high-quality data. They were further improved with extensive safety post-training, including reinforcement learning from human feedback (RLHF), automated testing and evaluations across dozens of harm categories, and manual red-teaming. Our approach to safety training and evaluations are detailed in our technical paper, and we outline recommended uses and limitations in the model cards. See the model card collection.
Unlocking new capabilities
Microsoft’s experience shipping copilots and enabling customers to transform their businesses with generative AI using Azure AI has highlighted the growing need for different-size models across the quality-cost curve for different tasks. Small language models, like Phi-3, are especially great for:
Resource constrained environments including on-device and offline inference scenarios.
Latency bound scenarios where fast response times are critical.
Cost constrained use cases, particularly those with simpler tasks.
For more on small language models, see our Microsoft Source Blog.
Thanks to their smaller size, Phi-3 models can be used in compute-limited inference environments. Phi-3-mini, in particular, can be used on-device, especially when further optimized with ONNX Runtime for cross-platform availability. The smaller size of Phi-3 models also makes fine-tuning or customization easier and more affordable. In addition, their lower computational needs make them a lower cost option with much better latency. The longer context window enables taking in and reasoning over large text content—documents, web pages, code, and more. Phi-3-mini demonstrates strong reasoning and logic capabilities, making it a good candidate for analytical tasks.
Customers are already building solutions with Phi-3. One example where Phi-3 is already demonstrating value is in agriculture, where internet might not be readily accessible. Powerful small models like Phi-3 along with Microsoft copilot templates are available to farmers at the point of need and provide the additional benefit of running at reduced cost, making AI technologies even more accessible.
ITC, a leading business conglomerate based in India, is leveraging Phi-3 as part of their continued collaboration with Microsoft on the copilot for Krishi Mitra, a farmer-facing app that reaches over a million farmers.
“Our goal with the Krishi Mitra copilot is to improve efficiency while maintaining the accuracy of a large language model. We are excited to partner with Microsoft on using fine-tuned versions of Phi-3 to meet both our goals—efficiency and accuracy!”
Saif Naik, Head of Technology, ITCMAARS
Originating in Microsoft Research, Phi models have been broadly used, with Phi-2 downloaded over 2 million times. The Phi series of models have achieved remarkable performance with strategic data curation and innovative scaling. Starting with Phi-1, a model used for Python coding, to Phi-1.5, enhancing reasoning and understanding, and then to Phi-2, a 2.7 billion-parameter model outperforming those up to 25 times its size in language comprehension.1 Each iteration has leveraged high-quality training data and knowledge transfer techniques to challenge conventional scaling laws.
Get started today
To experience Phi-3 for yourself, start with playing with the model on Azure AI Playground. You can also find the model on the Hugging Chat playground. Start building with and customizing Phi-3 for your scenarios using the Azure AI Studio. Join us to learn more about Phi-3 during a special live stream of the AI Show.
1 Microsoft Research Blog, Phi-2: The surprising power of small language models, December 12, 2023.
The post Introducing Phi-3: Redefining what’s possible with SLMs appeared first on Azure Blog.
Quelle: Azure