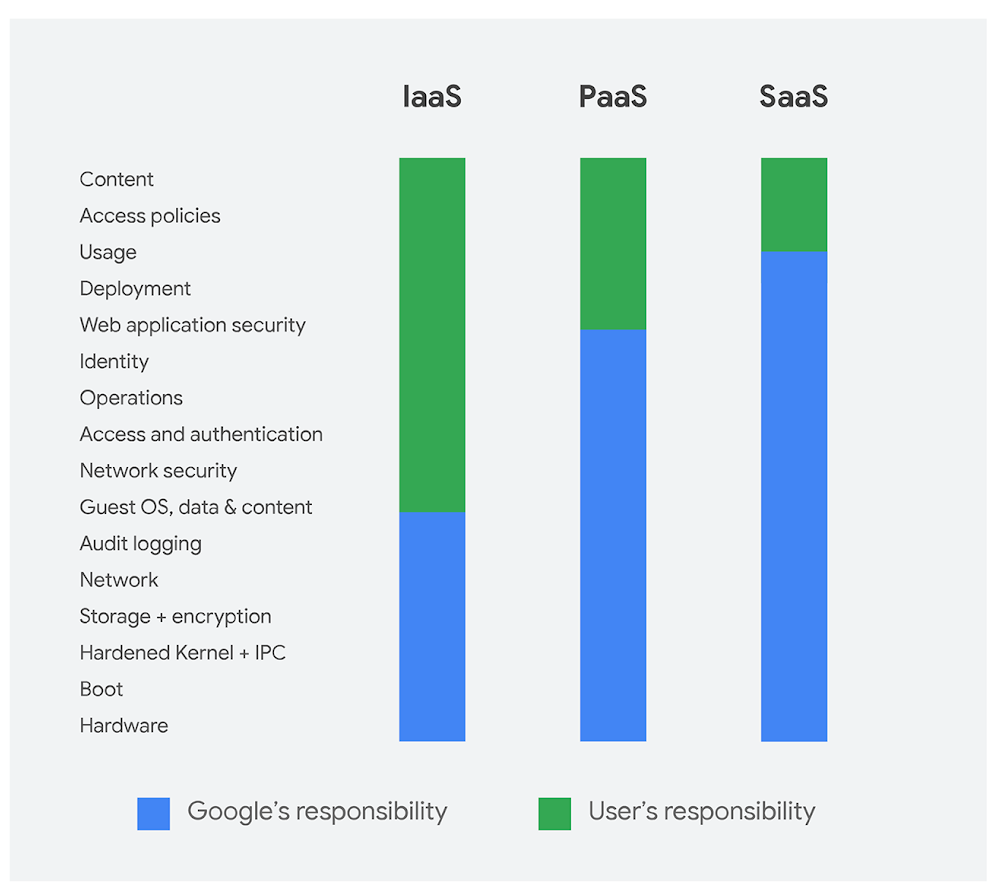
Editor’s note: This post is part of our blog post series on container security at Google.Security in the cloud is a shared responsibility between the cloud provider and the customer. Google Cloud is committed to doing its part to protect the underlying infrastructure, like encryption at rest by default, and in providing capabilities you can use to protect your workloads, like access controls in Cloud Identity and Access Management (IAM). As newer infrastructure models emerge, though, it’s not always easy to figure out what you’re responsible for versus what’s the responsibility of the provider. In this blog post, we aim to clarify for Google Kubernetes Engine (GKE) what we do and don’t do—and where to look for resources to lock down the rest.Google Cloud’s shared responsibility modelThe shared responsibility model depends on the workload—the more we manage, the more we can protect. This starts from the bottom of the stack and moves upwards, from the infrastructure as a service (IaaS) layer where only the hardware, storage, and network are the provider’s responsibility, up to software as a service (SaaS) where almost everything except the content and its access are up to the provider. (For a deep dive check out the Google Infrastructure Security Design Overview whitepaper). Platform as a service (PaaS) layers like GKE fall somewhere in the middle, hence the ambiguity that arises.For GKE, at a high level, we are responsible for protecting:The underlying infrastructure, including hardware, firmware, kernel, OS, storage, network, and more. This includes encrypting data at rest by default, encrypting data in transit, using custom-designed hardware, laying private network cables, protecting data centers from physical access, and following secure software development practices.The nodes’ operating system, such as Container-Optimized OS (COS) or Ubuntu. GKE promptly makes any patches to these images available. If you have auto-upgrade enabled, these are automatically deployed. This is the base layer of your container—it’s not the same as the operating system running in your containers.The Kubernetes distribution. GKE provides the latest upstream versions of Kubernetes, and supports several minor versions. Providing updates to these, including patches, is our responsibility.The control plane. In GKE, we manage the control plane, which includes the master VMs, the API server and other components running on those VMs, as well as the etcd database. This includes upgrades and patching, scaling, and repairs, all backed by an SLO.Google Cloud integrations, for IAM, Cloud Audit Logging, Stackdriver, Cloud Key Management Service, Cloud Security Command Center, etc. These enable controls available for IaaS workloads across Google Cloud on GKE as well.Conversely, you are responsible for protecting:The nodes that run your workloads, including VM images and their configurations. This includes keeping your nodes updated, as well as leveraging Compute Engine features and other Google Cloud products to help protect your nodes. Note that we already manage the containers that are necessary to run GKE, and provide patches for your OS—you’re just responsible for upgrading.The workloads themselves, including your application code, dockerfiles, container images, data, RBAC/IAM policy, and containers and pods that you are running. This means leveraging GKE features and other Google Cloud products to help protect your containers.Hardening the control plane is Google’s responsibilityGoogle is responsible for making the control plane more secure – which is the component of Kubernetes that manages how Kubernetes communicates with the cluster, and applies the user’s desired state. The control plane includes the master VM, API server, scheduler, controller manager, cluster CA, root-of-trust key material, IAM authenticator and authorizer, audit logging configuration, etcd, and various other controllers. All of your control plane components run on Compute Engine instances that we own and operate. These instances are single tenant, meaning each instance runs the control plane and its components for only one customer. (You can learn more about GKE control plane security here.)We make changes to the control plane to further harden these components on an ongoing basis—as attacks occur in the wild, when vulnerabilities are announced, or when new patches are available. For example, we updated clusters to use RBAC rather than ABAC by default, and locked down and eventually disable the Kubernetes dashboard.How we respond to vulnerabilities depends on which component the vulnerability is found in:The kernel or an operating system: We apply the patch to affected components, including obtaining and applying the patch to the host images for Kubernetes, COS and Ubuntu. We automatically upgrade the master VMs, but you are responsible for upgrading nodes. Spectre/Meltdown and L1TF are examples of such vulnerabilities.Kubernetes: With Googlers on the Kubernetes Product Security Team, we often help develop and test patches for Kubernetes vulnerabilities when they are discovered. Since GKE is an official distribution, we receive the patch as part of the Private Distributors’ List. We’re responsible for rolling out these changes to the master VMs, but you are responsible for upgrading your nodes. Take a look at these security bulletins for the latest examples of such vulnerabilities, CVE-2017-1002101, CVE-2017-1002102, and CVE-2018-1002015.Component used in Kubernetes Engine’s default configuration, like Calico components for Network Policy, or etcd: We don’t control the open-source projects used in GKE, however, we select open-source projects that have demonstrated robust security practices and that take security seriously. For these projects, we may receive a patch from upstream Kubernetes, a partner, or the distributor list of another open-source project. We are responsible for rolling out these changes, and/or notifying you if there is action required. TTA-2018-001 is an example of such a vulnerability that we patched automatically.GKE: If a vulnerability is discovered in GKE, for example through our Vulnerability Reward Program, we are responsible for developing and applying the fix.In all of these cases, we make these patches available as part of general GKE releases (patch releases and bug fixes) as soon as possible given the level of risk, embargo time, and any other contextual factors.We do most of the hard work to protect nodes, but it’s your responsibility to upgrade and reap the benefitsYour worker nodes in Kubernetes Engine consist of a few different surfaces that need to be protected, including the node OS, the container runtime, Kubernetes components like the kubelet and kube-proxy, and Google system containers for monitoring and logging. We’re responsible for developing and releasing patches for these components, but you are responsible for upgrading your system to apply these patches.Kubernetes components like kube-proxy and kube-dns, and Google-specific add-ons to provide logging, monitoring, and other services run in separate containers. We’re responsible for these containers’ control plane compatibility, scalability, upgrade testing, as well as security configurations. If these need to be patched, it’s your responsibility to upgrade to apply these patches.To ease patch deployment, you can use node auto-upgrade. Node auto-upgrade applies updates to nodes on a regular basis, including updates to the operating system and Kubernetes components from the latest stable version. This includes security patches. Notably, if a patch contains a critical fix and can be rolled out before the public vulnerability announcement without breaking embargo, your GKE environment will be upgraded before the vulnerability is even announced.Protecting workloads is still your responsibilityWhat we’ve been talking about so far is the underlying infrastructure that runs your workload—but you of course still have the workload itself. Application security and other protections to your workload are your responsibility.You’re also responsible for the Kubernetes configurations that pertain to your workloads. This includes setting up a NetworkPolicy to restrict pod to pod traffic and using a PodSecurityPolicy to restrict pod capabilities. For an up-to-date list of the best practices we recommend to protect your clusters, including node configurations, see Hardening your cluster’s security.If there is a vulnerability in your container image, or application, however, it is also fully your responsibility to patch it. However, there are tools you can use to help:Google managed base images, which are regularly patched by Google for known vulnerabilities.Container Registry vulnerability scanning to analyze your container images and packages for potential known vulnerabilities.Cloud Security Scanner (alpha) to help you detect common application vulnerabilities.Incident response in GKESo what if you’ve done your part, we’ve done ours, and your cluster is still attacked? Damn! Don’t panic.Google Cloud takes the security of our infrastructure—including where user workloads run—very seriously, and we have documented processes for incident response. Our security team’s job is to protect Google Cloud from potential attacks and protect the components outlined above. For the pieces you’re responsible for, if you’re looking to further protect yourself from potential container-specific attacks, Google Cloud already has a range of container security partners integrated with the Cloud Security Command Center.If you are responding to an incident, you can leverage Stackdriver Incident Response & Management (alpha) to help you reduce your time to incident mitigation, refer to sample queries for Kubernetes audit logs, and check out the Cloud Forensics 101 talk from Next ‘18 to learn more about conducting forensics.What’s the tl;dr of GKE security? For GKE, we’re responsible for protecting the control plane, which includes your master VM, etcd, and controllers; and you’re responsible for protecting your worker nodes, including deploying patches to the OS, runtime and Kubernetes components, and of course securing your own workload. An easy way to do your part is touse node-autoupgradeprotect your workload from common image and application vulnerabilities, andfollow the Google Kubernetes Engine hardening guide.If you follow those three steps, together we can build GKE environments that are resilient to attacks and vulnerabilities, to deliver great uptime and performance.
Quelle: Google Cloud Platform